
Jetbot系列11-智能避障之模型训练
这原本应该是任何深度学习应用的第一个步骤,包括采集所需要的图像数据以及用框架工具进行模型训练,但这个过程比较枯燥乏味,因此在上一篇文章先让大家体验一下避撞的效果,但最终还是得回头将这个步骤补上,才能让这个项目更加完整,并且适合于更多使用场景。
Jetbot使用深度学习最基础的图像分类功能,模拟人类真实的视觉感知能力来实现避撞的应用,基本的原理在前一篇文章里已经详细说明,原厂提供的best_model.pth模型文件所采用的数据集,肯定于您的现场环境不尽相同,如果在您的场地所显示的效果不够好,那最根本的解决办法,就是重新收集数据并且训练模型。
这个部分没有什么技术或原理需要说明,主要是以下几个细节需要多加注意就行:
- 摄像头规格一致性:
采集数据使用的摄像头与live_demo是同一个型号,包括镜头的广角度,如果使用同一个是最好的。任何人不能期望用160度广角摄像头采集数据所训练的模型,能在平光摄像头下很精准地识别,反之亦然。
同样地,也不要期望用手机或其他设备去采集图像所训练的模型,能在Jetbot上非常顺畅地执行推理,也不要指望在Jetbot上执行很顺畅的模型,能在其他种类摄像头下获得精准的推理结果,当然我们不会阻止您去尝试的。
摄像头的匹配是深度学习应用的基础关键,如果忽略这个基本点,则其他工作的努力也可能都是白费。
- 图像收集与分类的细节:
项目里提供的data_collection.ipynb脚本,就是配合Jetbot小车使用CSI摄像头拍摄图像并且进行分类。
这个脚本的内容非常简单,主要功能就是启动摄像头、创建 ”add free” 与 ”add blocked” 按钮,将画面捕捉的图像分别添加到 ”free” 与 “blocked” 文件夹中,然后提供给训练代码执行模型训练,请自行调整输出成下面状态,便于后面的操作。
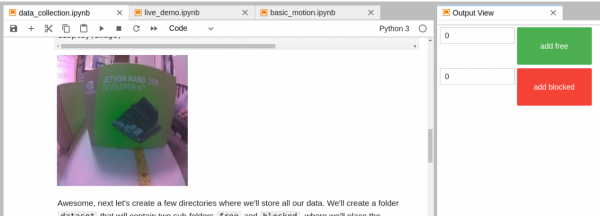
这个环节是最繁琐但又至关重要的部分,很多疏忽之处都是在这里发生,因为大部分初学者都不知道这个数据分类步骤所造成的影响,特别是对“距离感”的分类问题,这是影响避撞效果。下图左是Jetbot与标的物距离20厘米时,下图右则是会拍摄到的图像。

这时候要将这张图归类为“free”还是“blocked”?这就看每个人不同的习惯,保守的人可能归类到“free”而激进的人可能归类到“blocked”,这个归类就影响Jetbot小车“看到”怎样的图像就决定转向。
如果您想让小车在距离标的物10厘米时才转向,那么在上一张图时选择“free”分类,然后在下一张“距离10厘米”时所拍的图像归类为“blocked”,否则Jetbot可能大老远看到这个标的物时就判断为”blocked”

最好先定好安全距离,然后在面对不同标的物时都采取相同的标准,如此用Jetbot摄像头为“free”类与“blocked”类各收集200张左右图片,也就是我们得为在控制电脑上运行data_collection.ipynb脚本,执行400+次的图像采集与分类的工作。

在https://www.youtube.com/watch?v=Pn84HPMnApI有一段关于这个数据收集与分类的视频,上图是这个视频的部分截屏,其实想象一下就知道有多繁琐,虽然过程并不困难,但考验的时大家的耐心与细心。
事实上,例如单纯的障碍物体可以较轻松地该物体放到Jetbot前面,根据不同距离选择分类,还是比较轻松的。比较辛苦的部分是“路况图像”的采集与分类,例如在办公室地面会遇到的“桌椅脚”、“墙角”、“不平坦”等路况,就必须让Jetbot到现场去采集,这才是整个环节中最耗费劳动力的部分。
这样的问题是否有辅助的方法?我们在本系列第9篇文章“用键盘与摇杆控制基本走动”的内容中,讲解过用basic_motion.ipynb能创建如下图右下角的控制板,去控制Jetbot小车的移动,现在就开启这个脚本,一路执行到这个控制板控制功能,然后同样将这个控制板的Output View与data_collection.ipynb的输出,集成如下图状态。
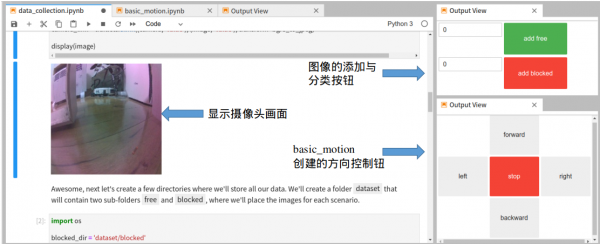
现在就可以将Jetbot置于地上,我们坐在桌上操作控制台PC,透过右下角按钮指挥Jetbot移动,然后透过摄像头回传的画面,将图像进行分类,这样就不用拎着笔记电脑、趴在地上去用手挪动Jetbot去获取图像。
- 选择训练设备:
在data_collection.ipynb最后一个步骤是将收集分类的数据集进行压缩,目的是要在其他计算性能较好的设备上进行模型训练,可以在Jetson AGX Xavier、Xavier NX或者装有CUDA GPU卡的x86 PC上,但还需要配置相应的开发环境,包括CUDA、CUDNN、TensorRT等库,以及TensorFlow、PyTorch、torchvision这些框架,这里面还牵涉到非常多的版本对应问题,其实是相当复杂的一项任务。
事实上,面对这样400张224x224尺寸的图像集,计算数据量并不大,用Jetbot的Jetson Nano(含2GB)是足以胜任的,顶多就是一两个小时的模型训练时间,但与重新达一个训练环境相比,这个就简单太多了。
因此这里推荐就是使用Jetbot的设备进行训练就行,这样收集完数据之后也不需要进行文件压缩的步骤。
- 神经网络的一致性:
在项目中提供3个train_model_xxx.ipynb,其中train_model.ipynb使用最经典的AlexNet神经网络进行训练,其对应的演示脚本就是前一篇文章的live_demo.ipynb,这是针对AlexNet神经网络的推理应用。
如果在这里选择使用改良过的ResNet18神经网络(train_model_resnet18.ipynb脚本),则演示的时候就得使用相同神经网络的live_demo_resnet18.ipynb,这些对应不能有错。
至于还有两个与trt相关的演示脚本,也都是基于ResNet18神经网络的延伸功能,先用live_demo_resnet18_build_trt.ipynb脚本将best_model.pth转换成TensorRT加速引擎的best_model_trt.pth,再用live_demo_resnet18_trt.ipynb调用进行演示,这会在推理过程使用更少的计算资源。
另外还有个train_model_plot.ipynb训练脚本,则是在AlexNet神经网络基础上添加“可视化”的检视功能,对于模型训训练并没有什么影响。
训练脚本里面的绝大部分参数都是经过优化处理的,除非您对这个神经网络相当熟悉,否则就不需要去改动,除了以下3个可以进行调整:
- batch_size:在“Create data loaders to load data in batches”步骤的train_loader与test_loader的batch_size可以根据设备显存进行调整。
- NUM_EPOCHS:训练回合数,基本上用30回应该足够,通常20回可能已经进入收敛状态。
- BEST_MODEL_PATH:最终输出文件名,这个训练脚本会在训练回合数中找出精确度最高的一次结果,然后存成指定文件名。如果您要面向多个不同场地的话,可能需要训练多个模型,就可以自行设定。
- 检验结果:
这里唯一的检验方式,就是执行live_demo让Jetbot跑动起来,看看是否如预期般地避开障碍物与坑洞,如果最终识别效果不够好,通常最可能出现问题的部分如下:
- 数据集需要清洗:很多初学者发生的问题,主要是因为数据集数量不足或存在不正确分类的图片所导致,解决办法就是重新检查每一张图片,清洗掉不良的数据或者补充更多正确的图形。
- 回合数不够:就加大NUM_EPOCHS数值后重新再训练,然后再次检验。
好了,这个数据收集与模型训练的阶段并不存在什么技术问题,虽然极度无聊而且繁琐,但却又不能跳过去,好好耐心并细心的处理。【完】
来源:业界供稿
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2022
02/15
14:17
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
