
NVIDIA Jetson Nano 2GB 系列文章(38):nvdsanalytics视频分析插件
这是个非常有用的插件,是DeepStream 5.0添加的功能,对nvinfer(主检测器)和nvtracker附加的元数据执行分析,目前主要针对涉及感兴趣区域(ROI)的过滤、过度拥挤检测、方向检测和跨线统计等四大功能,如下表:
|
功能 |
说明 |
|
ROI过滤 |
此功能检测ROI中是否存在目标类别的对象,结果作为每个对象的元数据附加,以及每帧ROI中的对象总数。 |
|
拥挤检测 |
在“ROI过滤”的前提下,检测每帧对象总数是否处于过度拥挤的状态,就是检测ROI中的对象数量是否超过预先配置的阈值。 |
|
方向检测 |
使用对象位置历史记录和当前帧信息检查对象是否遵循预配置的方向。结果作为每个对象的元数据附加。 |
|
跨线统计 |
此功能检查对象是否遵循虚拟线的预配置方向,以及是否已越过虚拟线。当测线交叉时,结果将附加到对象上,同时还会附加帧元,其中累积计数与测线交叉的每帧计数一起附加。 |
可以看出这是NVIDIA经过实际项目的要求所增加的功能插件,主要就是针对视频内的我们所指定的“某个区块(兴趣区,ROI)”或“某条线(跨越线)”范围中的标的物件,进行“物件动向”的分析与统计(如下图)。大部分的使用场景是在道路流量分析的应用,但这也可以应用在營建工地、生产工厂、楼宇、校园、消防设施的危险区(danger zone)监控,实用性非常之高。
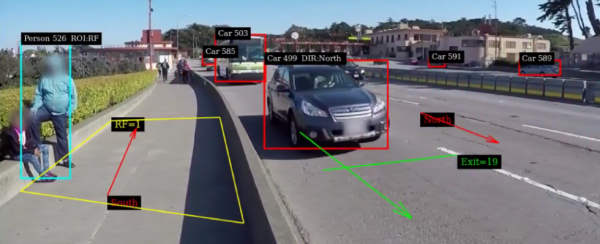
有经验的开发人员就会很清楚,如果缺少nvdsanalytics这个插件的时候,则开发者需要自行从nvtracker里面抽取相关数据,然后与兴趣区或跨越线进行持续比对,确认是否属于要列入统计数据的物件,至于“动向分析”功能,更需要大量的“前后帧”位置比对去进行判断,这些开发的工作量是相当艰辛、计算量是非常巨大的,如今在DeepStream里面只要轻松调用nvdsanalytics插件,就能轻松地完成很复杂的工作。
在DeepStream开发套件里的deepstream-nvdsanalytics-test是C/C++版本的范例代码,先前文章里带着大家安装过的deepstream_python_apps范例中,也提供Python版本的代码,在范例路径下面的deepstream-nvdsanalytics里面。
- Gst-nvdsanalytics工作原理
DeepStream一直令人赞赏的一个特色,就是将插件的接口做得十分简单,因此在开始执行范例代码之前,我们需要先对这个插件有个初步了解,请参考下面链接的原厂说明:https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_plugin_gst-nvdsanalytics.html,下图是Gst-nvdsanalytics的基本工作原理图:
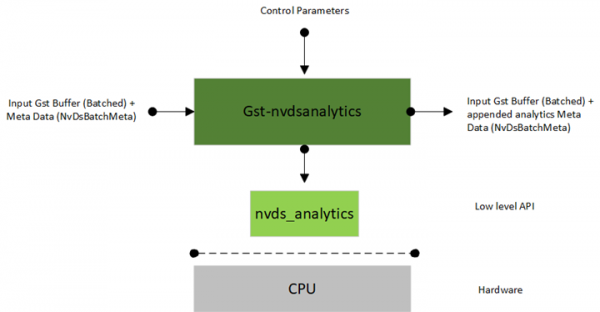
整个执行流程其实就是很简单的四个步骤:
- 接受上游(左边)的nvinfer与nvtracker元件发送的批处理缓冲区(GstBuffer + NvDsBatchMeta),并从中提取元数据;
- 将元数据传递到低阶nvds_analytics接口(上图下方)进行处理;
- 低阶接口根据为每个流的所制定配置(前面所列的四项功能)的规则去执行分析;
- 然后返回添加了分析元数据的作为输出,这是每个跟踪对象以及整个帧的分析结果。
这个插件伴随着NvDsAnalyticsFrameMeta与NvDsAnalyticsObjInfo两组元数据,可以在DeepStream开发包的sources/includes/nvds_analytics_meta.h找到完整的定义,也可以在https://docs.nvidia.com/metropolis/deepstream/sdk-api/Meta/analytics.html 找到使用说明。这里也简单说明一下,对于后面说明代码时会有帮助:
- NvDsAnalyticsFrameMeta:定义“帧级(frame level)”的数据内容,配合所提供的四项功能,主要结构如下:
- ocStatus(数据类型:bool):在给定的ROI区域内
- objInROIcnt(数据类型:unit32_t):在ROI区域内检测到的物件总数
- objLCCurrCnt(数据类型:unit64_t):保存当前帧中跨线物件的数量
- objLCCumCnt(数据类型:unit64_t):保存已配置线条的累计跨线物件数量
- unique_id(数据类型:guint):保存nvdsanalytics实例的唯一标识符
- objCnt(数据类型:unit64_t):保存每帧里面每个类ID的对象总数
- NvDsAnalyticsObjInfo:定义“对象(object level)”的数据内容,配合所提供的四项功能,主要结构如下:
- roiStatus(数据类型:字符串数组):保存对象所在的ROI标签数组
- ocStatus(数据类型:字符串数组):保存对象所在的ROI标签数组保存对象所在的过度拥挤标签数组
- lcStatus(数据类型:字符串数组):保存对象已跨越的线交叉标签数组
- dirStatus(数据类型:字符串):保存跟踪对象的方向字符串
- unique_id(数据类型:guint):保存nvdsanalytics实例的唯一标识符
前面工作流最右边的输出,是以帧级的NvDsAnalyticsFrameMeta结构进行封装,想要调用是时就定义一个用户元,将meta_type设置为NVDS_USER_FRAME_META_NVDSANALYTICS。然后将用户元添加到NvDsFrameMeta的frame_user_meta_list成员。
分析(每个检测到的对象)的输出结果封装在NvDsAnalyticsObjInfo结构中,同样再定义定义一个用户元,将类型设置为NVDS_USER_OBJ_META_NVDSANALYTICS,然后将这个用户元添加到NvDsObjectMeta的obj_user_meta_list成员中。
上述步骤与数据结构,已经将大部分nvdsanalytics插件的工作都部署的差不多了,剩下就是启动并监听交互信息的部分。
- 项目配置文件说明
这个范例的代码与前面几个范例的工作流程是一致的,只是这里接受多个输入源,包括H264/H265视频文件与RTSP视频流,因此需要建立多个队列(queue)作为缓冲来处理,至于nvanalytics_src_pad_buffer_probe部分与test1的osd_sink_pad_buffer_probe代码结构的逻辑也是相近的,因此请自行根据先前代码内容进行类比,这里就不花力气再重复那些冗余的内容。
不过这个项目里面的配置文件与前面的项目有比较大的不同之处,因此这里就花点时间探索这部分的细节。范例的配置文件为config_nvdsanalytics.txt,一共有5个配置组
这个插件一共有以下的5个配置组:
- [property]:配置插件的一般行为,这是唯一的强制(必须有的)组
- [roi-filtering-stream-<n>]:为第<n>个流配置roi筛选规则参数,无数量限制
- [overcrowding-stream<n>]:为第<n>个流配置过度拥挤参数的阈值
- [direction-detection-stream-<n>]:为第<n>个流配置方向检测参数
- [line-crossing-stream-<n>]:为第<n>个流配置跨线参数
在[property]组里面的参数是大家比较熟悉的,其他组里面有几个用法比较特殊的参数,在这里挑出来说明
- roi-<label>:用在[roi-filtering-stream-<n>]与[overcrowding-stream-<n>]这两个组,可自行配置<label>名称,例如“RF”、“OC”、“DangerZone”等,后面设定一组“多(3以上)边形”坐标,使用“;”作为间隔,坐标顺序为“x1;y1;x2;y2;x3; y3;...”,例如“roi-DangerZone=295;643;579;634;642;913;56; 828”、“roi-OC=295; 643;579; 634;642;913;56;828”等,可以为每个视频源指定多个的兴趣区。
- direction-<label>:用在[direction-detection-stream-<n>]组,可自行配置<label>内容,例如“South”、“East”、“Forward”等等,后面给定一组(x1;y1;x2;y2)坐标来表示方向,当对象沿这个方向移动时,前面设定的标签将作为用户元数据附加到对象里,可以为每个视频源指定多个方向。
- line-crossing-<label>:用在[line-crossing-stream-<n>]组里面,同样可自行设定<label>内容,例如“Entry”、“Exit”、“Start”等,后面的设定值定义两组线的四个坐标,依序为(x1d;y1d;x2d;y2d;x1c;y1c;x2c;y2c),其中第一组(x1d;y1d;x2d;y2d)代表移动的方向,如下图“向下方的黄色箭头”所表示;第二组(x1c;y1c;x2c;y2c)标示“跨越线”的坐标,如下图与黄色箭头所交叉的“横向线”。

只有当物件“以符合要求的方向通过跨越线“,才算符合这里的统计要求,才会纳入这个视频分析的计数之中,这个功能定义的十分完善。
同样的,我们可以为每个视频流提供多组这种跨越线的配置。
- extended:用在[line-crossing-stream-<n>]组,这个开关设定值是为了将上一个参数做个扩展,当设置为“0(关闭)”的时候,则计算物件通过的参考依据就仅止于“两条线的交叉点”,如果设置为“1(开启)”时,就会以(x1c;y1c;x2c;y2c)整条线作为参考依据。
- mode:用在[line-crossing-stream-<n>]与[direction-detection-stream-<n>]这两个组,设定“检测方向”与“配置方向”一致性的严格程度,有“loose(宽松)”、“strict(严格)”、“balance(平衡)”三种选项,例如“loose”只检查物体是否已越过线,并且该物体保持同一方向行进即可,公差可能会很高。
以上是比较复杂的参数与用法的简单说明,如果需要所有参数的完整说明,请直接参考https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_plugin_gst-nvdsanalytics.html 下方的“Configuration File Parameters”内容。
接下来就开始执行这个很有用处的范例,透过修改参数值来感受用途。
- 范例执行
由于deepstream_nvdsanalytics.py这个代码可以接受多个视频输入,因此需要使用“file:///”格式给定输入文件完整路径,为了简化指令长度,我们在工作目录下使用软链接来提供视频文件路径:
|
ln -s ../../../../samples/streams/sample_720p.h264 ~/test.h264 python3 deepstream_nvdsanalytics.py file:///home/nvidia/test.h264 |
下面是这个范例的执行画面:
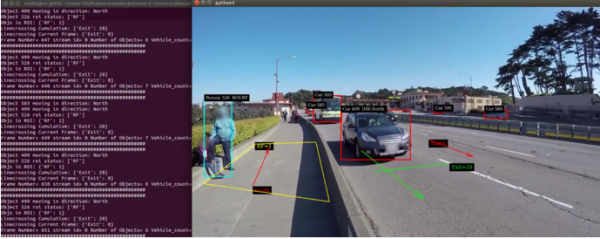
接下去看看所显现的数据代表什么意思,下面是我们截取第649帧图像的检测结果:
|
################################################## Object 503 moving in direction: North Object 499 moving in direction: North Object 526 roi status: ['RF'] Objs in ROI: {'RF': 1} Linecrossing Cumulative: {'Exit': 20} Linecrossing Current Frame: {'Exit': 0} Frame Number= 649 stream id= 0 Number of Objects= 7 Vehicle_count= 5 Person_count= 2 |
- 最上面两行表示物件编号503与499行进方向为“North”
- 第三行在RF兴趣区检测到编号526物件(图左方站立的人)
- 第四行显示兴趣区RF目前检测到“1”个物件
- 第5行统计出“累积通过”右方黄色线的物件数量为“20”
- 第6行显示“正在通过”右方黄色线的物件数量为“0”
- 第7行显示这是“第649帧”,检测到“7”个物件,其中有“5”辆车与“2”个人
如何?这个插件的功能很棒吧,可以让你自由地设定要监控的区域,并且非常有效率地按照你所设定的要求,反馈对应的统计数据。《完》
来源:业界供稿
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2021
11/02
11:41
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
