
NVIDIA Jetson Nano 2GB 系列文章(29): DeepStream 目标追踪功能
在计算机视觉的应用中,“识别”只是一个相当入门的技术,相信很多人在执行深度学习推理应用中,经常产生的质疑就是“识别出的类别,有什么用途呢”?
确认每一帧图像中有多少个我们想要识别的种类,以及他们在图像中的位置,只是整个应用的第一步而已,如果缺乏“目标追踪(tracking)”的能力,就很难提供视频分析的基础功能。
在标准 OpenCV 体系里有 8 种主流的目标追踪算法,有兴趣的可以在网上搜索并自行研究。
算法的基本逻辑就是需要对视频的相邻帧进行“类别”与“位置”的比对,因此这部分的计算还是相当消耗计算资源的,也就是当视频分析软件“开启”目标追踪功能时,其识别性能必定有所下降,大家必须先有这样的认知。
DeepStream 的定位就是针对“视频分析”的应用,因此“目标追踪”是其最基本的功能之一。
在前面使用的 myNano.txt 配置文件中,只需要调整一个设定值就能开启或关闭这个追踪功能,非常简单。
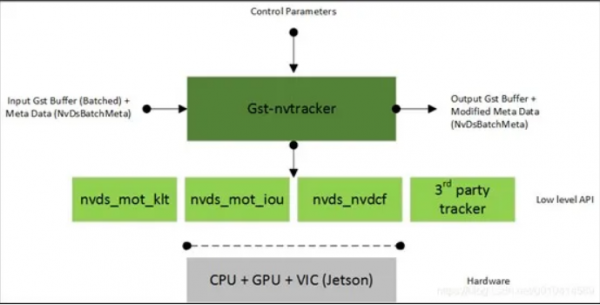
DeepStream 支持 IOU、KLT 与 NVDCF 三种目标追踪算法(如下图),其中 IOU 的性能最好,在 Jetson Nano 2GB 上的总体大约能到 200FPS;NVDCF 的精确度最高,但目前性能大约只能到 56FPS;KLT 算法目前在性能与精确度的平衡比较好,总体性也能到 160FPS,因此通常都选择 KLT 追踪器做演示。
算法的细节不多做解释,请自行寻找相关技术文件学习,这里就直接进入实验的过程。还是以前一篇文章中的 myNano.txt 配置文件为主,如果不知道的话,就用 source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt 复制一份出来就可以,透过修改里面的参数,让大家体验一下 DeepStream 目标追踪的功能。
01
目标追踪功能的开关
在 myNano.txt 最下方,可以看到[tracker]的设定组,下面有个“enable=1”的参数,就是目标追踪的功能。
现在先执行一次启动追踪功能,如下图可以看到每个识别出的物件除了类别、标框之外,旁边还有个编号,这个编号会一直跟着该物件,这样就形成“追踪”的功能。

此时的识别性能如下图,总性能(8 个数字相加)大约 160FPS。

如果将[trakcer]下面改成“enable=0”,再执行看看结果如何?下图中能识别出物件的类别与标框位置,但是已经没有编号。

关闭追踪功能之后的识别性能如下图,总识别性能可以达到 250FPS 左右。

02
切换追踪器
前面说过,目前 DeepStream 5.0 支持三种追踪器,那么要如何选择呢?同样在[tracker]参数组下方,有这样的三行参数:
|
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_iou.so #ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_nvdcf.so ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_klt.so |
前面加上“#”号的就是处于关闭的状况,请先将[tracker]切回“enable=1”的开启状态,接下来请自行加减“#”的位置以切换追踪器的选择,分别测试这三个追踪器的不同之处,包括识别性能与追踪能力。
这部分必须直接在视频中体验,因此就不截屏显示。测试结果可以感受到 IOU 追踪器的性能最好,可达到 200FPS 左右,但是同一物件的编号并不是太稳定,而 NVDCF 追踪器的编号最为稳定,但性能大概只有 IOU 的 1/4,最多只能承受 2 路视频的实时分析。
KLT 算法总体性能可达到 160FPS,可以支持到8路以内的实时识别,追踪能力也比 IOU 好不少,不过这个算法对 CPU 的占用率比较高,是这个算法的主要缺点。该如何选择需要看实际的场景与计算设备的资源而定。
03
获取追踪数据
前面打开目标追踪功能的目的,并不只是为了在显示器上看看而已,而是用这些数据做更有价值的应用,而这些数据要从什么地方得到呢?通常都需要透过 Python 或 C++从 DeepStream 提供的接口去获取。
这里提供一个无需了解 DeepStream 接口就能获取目标追踪数据的方法,只要我们在 myNano.txt 里面的[application]参数组,添加一条“kitti-track-output-dir=<PATH>”的路径指向就可以,这里假设要将数据存入“/home/nvidia/track”路径下,在 myNano.txt 里添加一行参数即可:
|
[application] 。。。 。。。 kitti-track-output-dir=/home/nvidia/track |
执行“deepstream -c myNano.txt”之后,就可以看到/home/nvidia/track目录下产生非常多的文件,如下截屏:

每个文件存放“一帧”的目标追踪结果,例如我们测试的 sample_1080p_h264.mp4 视频有 48 秒,每秒有 30 帧图像,就会生成 1440 个文件。
前面 6 位数“00_000”代表视频源的编号,从“0”开始,如果有 4 路视频源就会有“00_000”~“00_003”的编号,后面 6 位则是流水号,例如这个测试视频就会生成“000000.txt”~“001440.txt”,由这两部分组合而成文件名。
最后看一下文件的内容,如下所示:

这是 KITTI 格式的数据,第一栏位是该物件的类别,第二栏是该物件的“追踪编号”,后面数据所代表的意义,请自行参考 KITTI 的格式定义。
现在我们就可以依序读入这些追踪文件,或者将这些文件回传给控制中心,进行文件解析与信息提取,这样是不是很方便?相信这些内容对于开发会很有帮助。
来源:业界供稿
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2021
08/02
15:23
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
