
Jetson Nano 2GB系列文章(19):Utils的videoOutput工具
上一篇文章为大家深入地讲解了videoSource()这个非常强大的输入源处理模块,本文的重点将聚焦在videoOutput()这个输出标的处理模块。
videoOutput()与videoSource()几乎具备一致的特性。这里直接列出了videoOutput()所支持的输出种类与媒体格式:
- 支持5种输出方式:
- 显示器:“display://0”
- RTP视频流:“rtp://<remote_ip>:1234”
- 视频文件:“完整文件名”,例如 “input.mp4”,
- 图像文件:“完整文件名”,例如 “room_0.jpg”,
- 文件夹:“完整文件夹路径”,当识别到输出类型为“文件夹”时,就会按照流水号递增方式生成文件名。
- 支持4种视频输出格式:MKV、MP4、AVI与FLV
- 支持5种媒体输出格式:H.264、 H.265、VP8、VP9与MJPEG
- 支持4种图像格式:JPG、PNG、TGA与BMP
- 自动根据数据源,调用合适的NVDEC解码功能
- 调用CUDA核处理大部分基础图像处理任务
我们在前面已经熟悉了将结果输出到显示器上的方式,接下来就来体验其他几种输出方式,这对于将来开发边缘应用是非常有帮助的。要知道绝大部分的边缘计算场景,都是不能在设备上直接连上显示器的,那么此时如何观看该设备上所监控到的视频内容呢?通常就是将输入源所获取的数据,做完深度学习推理识别之后的结果,做以下两种处理方式:
- 在当地存成视频,然后批次往管理服务区发送,再删除该视频,以保留空间。
- 将视频流直接转向到其他设备上进行显示。
至于使用哪种方式,必须根据实际场景而定。而本文的重点就是带着大家,对这两种用法进行试验,并借此学会这些使用方法。
我们还是用10lines.py代码为基础来进行修改,不过为了节省测试时间,这里会将深度学习推理计算的部分省略掉,只保留videoSource()与videoOutput()这两部分的代码。修改后的内容如下:
|
import jetson.utils input = jetson.utils.videoSource(INPUT) output = jetson.utils.videoOutput(OUTPUT)
while output.IsStreaming(): img = input.Capture() output.Render(img) |
这个6行代码,让人看起来非常轻松,却又支持了绝大部分常用的输入、输出形态与格式。
接下来的重点,就是将代码内的INPUT与OUTPUT做有效的置换,试试以下几种组合状况:

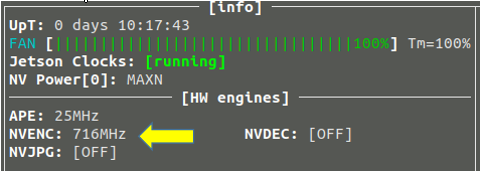
- 从CSI摄像头读入,然后输出存放至csi.mp4视频文件,这个相对直观,因此不多做说明。在观察jetson-stats时,若输出为视频文件,NVENC编码器的功能就启动了。
- 用VisionWorks的范例视频signs.avi作为输入,输出成个别侦图像到output目录里。视频长度为22秒,输出后生成44张图像,就是每0.5秒生成一张图像,不过实际生成的数量并不一定,与其他相关参数也有关。
- 这个组合是本文的重点实验,因为RTP视频流转向的实用性非常高,操作较为复杂,必须在发送端与接收端之间进行配合,因此需要花点时间说明并演示。
接下来就进行RTP视频流转向的示范步骤:
- 设备:一台Jetson Nano担任“发送端”,另外需要一台设备执行“接受端”,这个可以是另一台Jetson设备,也可以是Windows、MAC或Ubuntu操作系统的x86电脑。
- 网络:本实验的发送端与接收端设备,都在内网中的同一个网段。这里的实验用MicroUSB线连接Jetson Nano 2GB与运行Ubuntu操作系统的x86电脑,此时Jetson Nano的IP是192.168.55.1,x86电脑的IP是192.168.55.100,因此就需要将代码中OUTPUT部分修改成“rtp://192.168.55.100:1234”,修改后的完整代码如下:
|
import jetson.utils input = jetson.utils.videoSource(“/dev/video0”) output = jetson.utils.videoOutput(“rtp://192.168.55.100:1234”)
# import jetson.inference # net = jetson.inference.detectNet("ssd-mobilenet-v2", threshold=0.5)
while output.IsStreaming(): img = input.Capture() # detections = net.Detect(img) output.Render(img) |
- 执行步骤:
- 在发送端上执行以下指令:
|
1 |
|
执行过程中会出现如下截屏的摄像头信息内容:
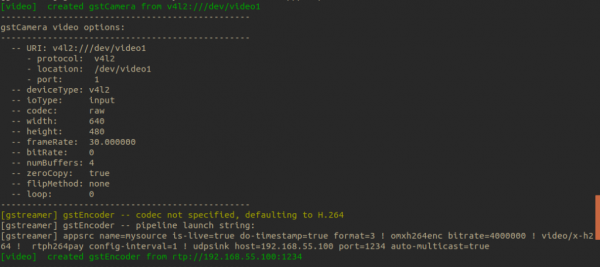
最后停在下面截屏的地方,发送端到这边就不用再去动这个指令框了。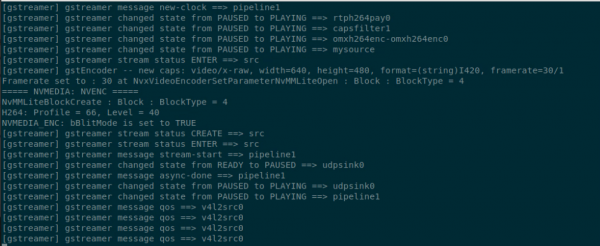
- 在接收端执行接收的动作:
- 在Ubuntu操作系统下,可执行以下指令便能直接接收视频流:
|
1 |
|
正确执行指令后,接收端设备的命令行会停留在如下图的状态:
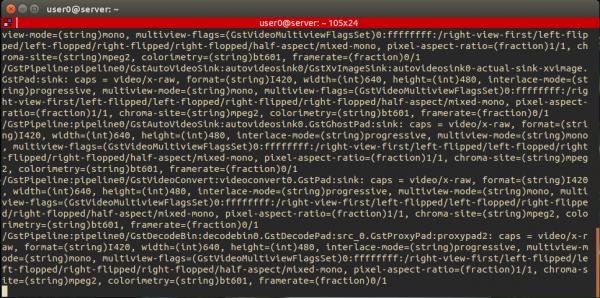
并且还会跳出一个显示框,核对以下显示的内容与Jetson Nano上的摄像头是否一致。
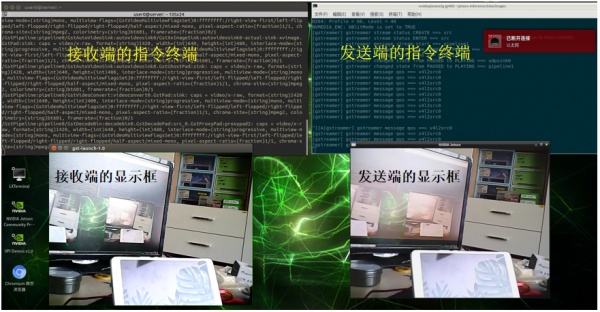
发送端与接收端之间的显示,是否出现时间差?取决于网络的质量!
-
- 用VLC播放软件,适用于Windows、Mac、Ubuntu操作系统:
首先得在接收设备上安装VLC播放软件,然后用文字编辑器生成一个”.sdp”文件,例如”rdp.sdp”,里面的内容如下:
|
ic=IN IP4 127.0.0.1 m=video 1234 RTP/AVP 96 a=rtpmap:96 H264/90000 |
同样先在发送端执行10lines.py这个代码,然后在接收端用VLC播放器打开rdp.sdp,就可以在VLC播放器上显示了。
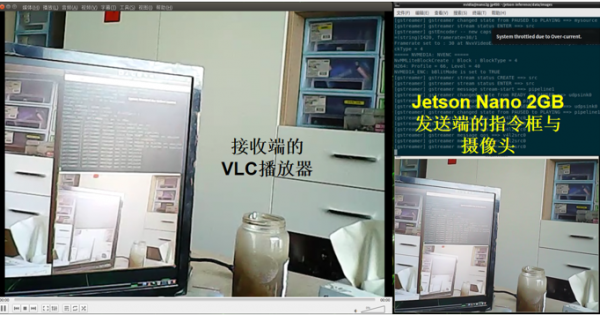
这样就能很轻松地将Jetson Nano 2GB上的摄像头看到的画面,直接透过RTP转到PC上去呈现。
这时候,如果你打开Jetson Nano 2GB的jetson-stats监控软件,也会看的左下角“NVDEC”处于执行的状态。
如果我们这时候将“物件检测”的推理识别功能打开的话,会出现怎样的结果呢?先将前面代码中的”#”部分取消,开启对象检测的功能,执行一次看看就知道,是否如下图一样会出现检测的结果。

好的,到这里为止,是不是已经可以更好地掌握videoOutput()的一些用法了呢?
来源:业界供稿
好文章,需要你的鼓励


Nvidia押注开放基础设施迎接智能体AI时代的Nemotron 3模型家族
AI智能体必须能够在大型上下文和长期时间段内进行合作、协调和执行,Nvidia表示,这需要一种新型的基础设施,一种开放的基础设施。

Anthropic最新CJE技术:让AI评判AI不再瞎猜,终结LLM评估乱象
这篇论文提出了CJE(因果法官评估)框架,解决了当前LLM评估中的三大致命问题:AI法官偏好倒置、置信区间失效和离线策略评估失败。通过AutoCal-R校准、SIMCal-W权重稳定和OUA不确定性推理,CJE仅用5%的专家标签就达到了99%的排名准确率,成本降低14倍,为AI评估提供了科学可靠的解决方案。

微软停用Visual Studio Code的IntelliCode AI代码补全扩展
微软正式弃用Visual Studio Code编辑器的IntelliCode AI代码补全扩展,建议C#开发者改用GitHub Copilot Chat对话式AI助手。被弃用的扩展包括IntelliCode、IntelliCode Completions、IntelliCode for C# Dev Kit和IntelliCode API Usage Examples。微软建议开发者卸载相关扩展,继续使用Roslyn内置语言服务器支持或安装GitHub Copilot Chat。弃用后,开发者将不再看到代码补全列表中的星标提示和内联灰色文本建议,这些扩展也将立即停止bug修复和支持服务。

NVIDIA团队让立体视觉AI实现“真正“实时运行:速度提升10倍却不牺牲精度
NVIDIA团队开发出Fast-FoundationStereo系统,成功解决了立体视觉AI在速度与精度之间的两难选择。通过分而治之的策略,该系统实现了超过10倍的速度提升同时保持高精度,包括知识蒸馏压缩特征提取、神经架构搜索优化成本过滤,以及结构化剪枝精简视差细化。此外,研究团队还构建了包含140万对真实图像的自动伪标注数据集,为立体视觉的实时应用开辟了新道路。
2021
06/01
09:45
分享
点赞

机器人咖啡杯?自动隔热垫?AI研究人员让它变成现实
AI行业2025年迎来现实检验
AWS欲弥合企业AI概念验证与生产部署之间的鸿沟
Apache Tika关键漏洞影响比预想更严重且涉及组件更广
IBM收购Confluent 强化数据和自动化投资组合
谷歌推出代码进化智能体,助力企业降低云计算隐性成本
Nvidia押注开放基础设施迎接智能体AI时代的Nemotron 3模型家族
微软停用Visual Studio Code的IntelliCode AI代码补全扩展
JetBrains发布Kotlin 2.3.0版本更新
中东2026年科技趋势:AI、网络安全和主权基础设施成为焦点
风投预测企业AI明年将强劲增长——再次
CIO对2026年AI发展的五大预测
