扫一扫
分享文章到微信
扫一扫
关注官方公众号
至顶头条
来源:业界供稿 2018-11-24 13:13:19
关键字:
公司名称: 菲数科技
公司介绍:
杭州菲数科技有限公司是创建于2015年的研发型公司,是国内最早一批专注于FPGA异构加速解决方案的专业公司,OpenPOWER基金会成员,Xilinx公司的国内官方合作伙伴。
菲数科技目前是FPGA异构加速领域的主流供应商,已经获得了多个国内一线互联网数据中心认可并批量使用,可以提供从硬件板卡,开发设计环境,驱动及应用接口,到FPGA逻辑设计及算法实现的整套的加速解决方案。
菲数科技致力于为客户提供多元的数据处理加速服务,包括深度学习,高性能计算,边缘计算,数据压缩/加解密,网络安全等多方面,尤其在CNN卷积网络的加速方案上,性能指标突出。
解决方案介绍: 通用型CNN卷积神经网络FPGA加速解决方案
CNN卷积神经网络是一种深度的监督学习下的机器学习模型,具有极强的适应性,善于挖掘数据局部特征,提取全局训练特征和分类,它的权值共享结构网络使之更类似于生物神经网络,在模式识别各个领域都取得了很好的成果。最近在多层卷积神经网络的突破导致了识别任务(如大量图片分类和自动语音识别)准确率的大幅提升。
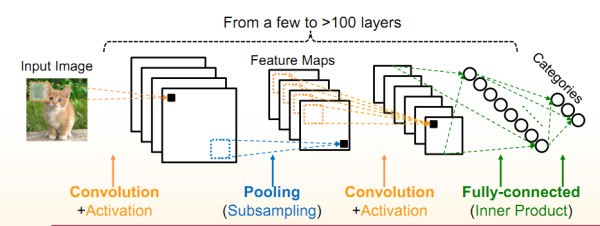
卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。卷积神经网络结构包括:卷积层,降采样层,全链接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。可以看到CNN算法主要由conv ,pooling,norm等几个部分组成,工作时将image跟weight灌进去,最终得到预测结果。在CNN里面主要耗时的就是conv二维卷积了。性能瓶颈也主要在于卷积时需要大量乘加运算,参与计算的大量weight参数会带来的很多访存请求。这些多层神经网络很大,很复杂,需要大量计算资源来训练和评估。
人工智能行业发展ABC三要素:算法(Algorithm)、大数据(Big Data)和计算力(Computing),大数据和算法可以分别比作人工智能的燃料和发动机,计算力则是制约人工智能成“人”还是“成神”的基础硬件—处理器芯片。实现计算力的提升有四种方案:CPU、GPU、FPGA、ASIC。FPGA正是作为一种AI芯片呈现在人们的面前,准确的说,FPGA不仅仅是芯片,它能够通过软件的方式定义,所以更像是AI芯片领域的变形金刚。
利用FPGA做计算加速在可编程性,实时性和互联性上的优势十分明显,相较于CPU/GPU有足够竞争力的低延时高性能,然而其短板也非常的明显,FPGA使用HDL硬件描述语言来进行开发,开发周期长,入门门槛高,需要FPGA的开发周期跟上深度学习算法的迭代周期。
菲数科技设计开发的通用型CNN FPGA加速解决方案,采用通用架构设计,无须更改底层设计文件,通过配置文件即可获得对各种主流算法模型的支持,可以支持在线模型切换。同时,对于新兴的深度学习算法,在此通用基础版本上进行相关算子的快速开发迭代,模型加速开发时间从之前的数月降低到现在的一到两周之内。
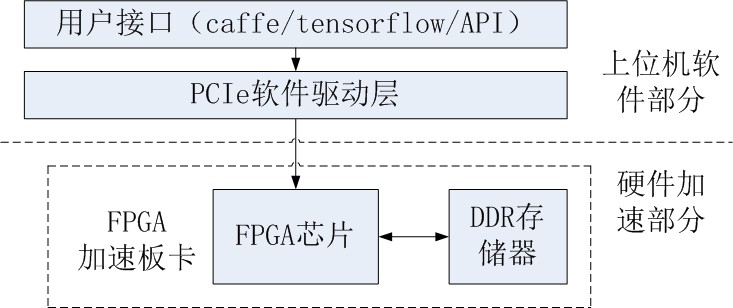
通过Caffe/Tensorflow/Mxnet等框架训练出来的CNN模型,通过菲数的加速库ANN生成相应的配置文件;同时,对图片数据和模型权重数据按照优化规则进行预处理,以及压缩后通过PCIe下发到FPGA加速器中。FPGA加速器根据配置,进行加速工作,加速器执行一遍完整缓冲区中的配置则完成一张图片深度模型的计算加速工作。每个功能模块各自相对独立,只对每一次单独的模块计算请求负责。加速器与深度学习模型相对抽离,各个layer的数据依赖以及前后执行关系均在配置文件中进行控制。
解决方案优势/带给客户的好处:
菲数科技支持通用卷积神经网路的加速库ANN的FX613Q加速板卡,采用了Xilinx的Xilinx VU13P芯片,性能领先, 使用方便,且从硬件板卡,FPGA IP方案到用户API,形成完整产品方案:
• 支持caffe/tensorflow开源环境下直接使用,自动解析网络拓扑和权重文件并自动配置FPGA
• 支持通用cnn加速应用,即可同时支持Resnet,SSD,VGG和YOLO等等网络拓扑
• 性能超越同级别的GPU,能耗比突出
•解决方案使用场景和案例:
菲数科技的通用卷积神经网路的加速库ANN应用于直播场景的图片审定,很好地满足了项目对于大批量和实时性的要求。
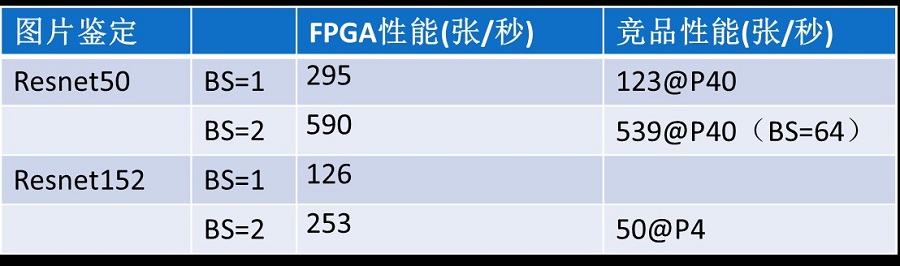
在Caffe环境下,Resnet50的架构,Batch Size=2的情况下,每秒可处理规格为224x224x3的图片590张,超过了同类GPU P40的性能。而在Resnet152架构下,每秒可以处理253张,约为P40的两倍。
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。




