
曙光存储“硬核”发布会:重磅新品、全新理念共同亮相
6月25日,曙光存储召开了主题为“先进存力,凝聚数据要素”的新品暨品牌发布会,震撼发布全球首个亿级IOPS集中式全闪存储FlashNexus,重磅升级分布式存储ParaStor,同时推出行业首个通存解决方案,应对“强无止境”数据存储性能和成本需求。

二十年来,曙光存储自主研发推出多款产品,实现了业务、应用和技术的突破,多项技术能力表现达到全球顶尖水平,本次发布的系列产品,是曙光存储二十年磨一剑的成果。
中科曙光总裁历军在发布会上表示:“新技术新应用快速迭代,而算力和存力是不变的两大底层支撑,先进算力和先进存力也是曙光长期投入研发的重要业务之一。曙光相信,变化是常态,而在任何时代,唯有强者‘恒存’。”

世界级“强存” 硬核技术自研突破
作为全球存储技术皇冠上的明珠,集中式存储性能往往代表存储厂商的最高水准。坚持自主研发二十年的曙光存储,本次发布的FlashNexus系列不仅是全球首个亿级IOPS集中式全闪存储,还是业界唯一有百控级扩展能力的集中式存储产品,稳定性保障首次突破7个9,综合性能领先同类产品50%以上,又一次用前沿技术引领产业革新。

曙光存储“强存”—重磅发布FlashNexus集中式全闪新品
应对金融、运营商、医疗等行业的全部关键业务系统,比如证券报盘等,一套FlashNexus产品即可轻松应对。此外,通过全栈自研软硬件支撑,FlashNexus可为用户提供强安全性与强生态兼容性。
“智存” 五级加速 做最懂AI的存储
在发布会上,曙光存储宣布重磅升级经典分布式存储产品——ParaStor全闪存储。新一代ParaStor依托NVMe全闪的技术优化,单节点带宽最高达到130GB/s,320万IOPS,成为国产化、x86、ARM等平台的最佳选择。

曙光存储“智存”—ParaStor分布式全闪系列全面升级
作为AI存储加速利器,升级后的ParaStor全闪存储具备五级数据加速技术,包括本地内存加速、BurstBuffer加速层、XDS双栈兼容、网络加速与存储节点高速层,搭配全路径AI亲和机制,让数据无需等待。容器化AI平台的最佳存储选择,可极致发挥硬件性能,提升全平台整体表现20倍以上!
跨平台 “通存” 让数据无界流动
当前伴随AI大模型狂飙,算力网络快速发展,不同平台、不同形态数据的融合应用需求持续突显。跨域存储集群组合管理、数据冷热分级感知、数据跨域网流动及跨域无感知访问等关键技术亟待攻克。
曙光存储首创“通存”解决方案,借助同根同源的集中式存储资源池与分布式存储资源池,让数据无界流动,实现跨平台一键式容灾恢复、跨形态热温冷数据无感流动和跨域资源池全维度视图,以充分提升存储资源利用率,并大幅降低整体数据拥有成本。
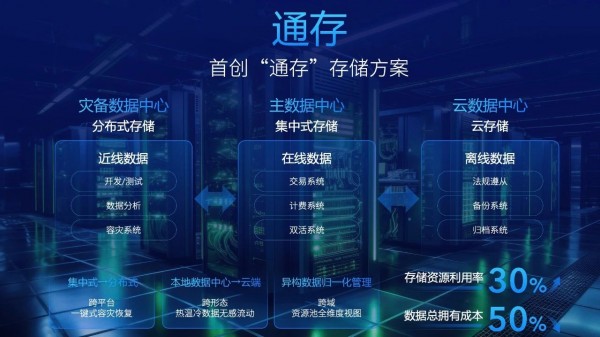
曙光存储首创“通存“方案
20年来,曙光存储自强不息,在时代召唤下诞生,在产业需求中前行,以“强者恒存”的理念精神,做先进存力先锋探索者。曙光存储也期待赋能更多伙伴取得业务成功,成为时代“强者”。

目前,曙光存储已与运营商、AI、科教、金融、医疗、政府、能源、制造等国家重点领域客户达成深度合作,携手突破业务发展面临的数据存储挑战。
来源:业界供稿
好文章,需要你的鼓励


阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
AI代码编辑器开发商Cursor完成23亿美元D轮融资,估值达293亿美元。Accel和Coatue领投,Google、Nvidia等参与。公司年化收入已突破10亿美元。Cursor基于微软开源VS Code打造,集成大语言模型帮助开发者编写代码和修复漏洞。其自研Composer模型采用专家混合算法,运行速度比同等质量模型快四倍。公司拥有数百万开发者用户,将用新资金推进AI研究。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2024
06/26
14:22
分享
点赞

Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
Infinidat G4系列升级重新定义高端企业存储格局
Druva扩展Microsoft云保护产品线
