
HPE计划在2025年全面升级超级计算机阵容
 如果大家有意采购百亿亿次超级计算机,或者购买其中一部分以实现资源扩展,那其实可供选择的厂商并不太多。毕竟没有多少公司拥有足够庞大的资产负债表来储备制造系统所需的全部配件。
如果大家有意采购百亿亿次超级计算机,或者购买其中一部分以实现资源扩展,那其实可供选择的厂商并不太多。毕竟没有多少公司拥有足够庞大的资产负债表来储备制造系统所需的全部配件。
除此之外,多年以来高性能计算领域的定价竞争也限制了买家的选择范围。由于在高性能计算领域占很大一部分收入流的这类超大规模设备几乎没有多少利润空间,所以能够继续坚守下来的这几十家公司几乎是在“用爱发电”。对于他们这种毫不利己,专门利高性能计算系统的行为,请允许我们表达深切的敬意。
在美国、欧洲、日本、南美以及中东,HPE的身影可谓随处可见。这家年轻的公司汇聚了Cray、Silicon Graphics、Convex、康柏以及惠普的优良传统。主要面向欧洲、南美、非洲以及亚洲市场的Atos Eviden部门,其历史则可以追溯到Groupe Bull,再往前看甚至跟IBM和NEC颇有几分相似。富士通的业务明显集中在日本,而且凭借着多年前与西门子IT部门的合并,其在欧洲也拥有一席之地。联想的业务范围横跨中国和美国,得益于同IBM以及各超级计算机中心建立的长期合作关系,联想从十年前从蓝色巨人手中买来的System x服务器部门让这位中国巨头在欧洲保留了业务基础。而在作为大本营的中国,联想在中国与浪潮、曙光等本地供应商合作组装超算系统。戴尔明显也在百亿亿次系统之外做了不少业务,这使其无需收购Cray或者SGI就能移居全球第二大本地高性能计算设备供应商。而对于各位超大规模基础设施运营商或者云服务商,Supermicro、Quanta、富士康以及Invensys等大型ODM厂商都很乐意为其构建一套性能突破天际的超级计算系统。
下图所示,为Hyperion Research对2023年本地高性能计算服务器市场的份额划分,其中还专门囊括了Supermicro以及其他由非传统供应商制造的高性能计算设备:
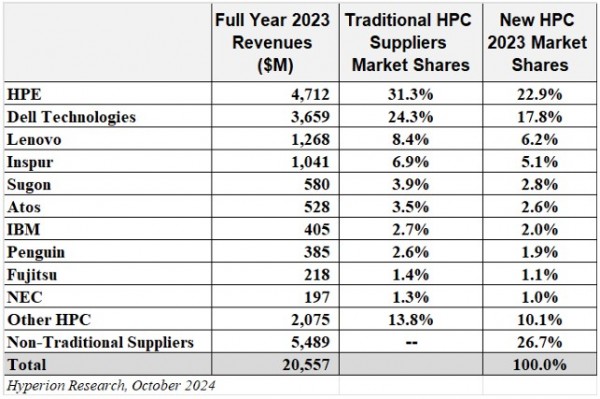
这些非传统供应商大体上都是在构建“AI超级计算机”,这部分业务的茁壮成长也让他们占据了略高于四分之一的市场份额。至于HPE,其凭借一己之力以略低于四分之一的市场份额占据绝对主导的地位——这在很大程度上要归功于Cary在美国和欧洲签订的几份准百亿亿次系统订单,外加在美国建造百亿亿次系统的巨额合约。
要想在高性能计算领域求得生存,必然意味着不断使用新的网络、计算和存储技术升级系统。HPE就在本届SC24超级计算大会上,展示了其为明年准备的超级计算机系统升级预案。
按照惯例,让我们先从网络聊起。随着替代方案InfiniBand以及商用级以太网稳定在400 Gb/秒的性能基础之上逐渐升级到800 Gb/秒的速度,第一代“Rosetta”Slingshot交换机ASIC和“Cassini”Slingshot网络接口ASIC那200 Gb/秒的性能表现明显有些过时。后两种接口于2019年底交付应用,并于2022年随着橡树岭国家实验室“Frontier”超级计算机的建立而经历一波全面升级。Rosetta和Cassini代表的是一种专为高性能计算用例调优的新型以太网,因此需要更长的时间才能将其推向市场并在更多系统中发挥作用。

在商业网络业务层面,以太网的升级每两年就会进行一次,而这也是英伟达对其以太网及InfiniBand网络设定好的迭代周期。我们将对此拭目以待。毕竟按以往的情况看,InfiniBand的升级节奏时好时坏,更多会与超级计算机的升级周期保持同步。而超算的升级往往相隔三到四年。Cray互连的升级周期则在不同代际间表现出巨大的差异,比如“SeaStar”XT3互连诞生于2004年,“SeaStar2”XT4互连是2006年,用于XT5的“SeaStart2+”互连亮相于2007年,用于XK7的“Gemini”互连是2010年,用于XC的“Aries”则是2012年。
就在Aries与Rosetta这段巨大的空窗期内,英特尔收购了Gemini和Aries的底层技术,并试图将其与InfiniBand的变体合并以建立Omni-Path。当发现计划未能取得预期效果时(随后由Cornelis Networks从英特尔手中收购了Omni-Path,并对其进行合理化调整和改造),Cray决定建立Rosetta并借此重返高性能计算互连市场。这一次,Cray选择了以太网作为基础协议。
我们在2002年1月曾经详细介绍过Rosetta ASIC拥有32个SerDes块,在每通道27 Gb/秒的原生信号基础上进行PAM4多级调制,因此可以提供高达56 Gb/秒的吞吐量。(PAM4每信号提供2比特,而之前的NRZ调制每信号仅提供1比特。)Rosetta芯片采用台积电公司的16纳米制程工艺,运行功率约为250瓦,能够以200 Gb/秒的速率支持64个端口。(在去除数据编码开销之后,每端口拥有4条PAM4通道,速度为50 Gb/秒。)
而在Cray(现在归HPE所有)的Slingshot家族这边,首选的是所谓“蜻蜓拓扑”设计。其中Rosetta-1芯片(也就是人们常说的首款Slingshot ASIC)能够在三级网络(即顶架、聚合与主干)中支持最多27.9万个端点。当然,除了蜻蜓之外,Rosetta还支持胖树、环面、扁平蝴蝶及其他多川网络拓扑选项。
依托于Cassini 1 NIC芯片,HPE创建了一款200 Gb/秒的适配器,其注入带宽约为28 TB/秒,二分带宽约为24 TB/秒。Cassini-1网卡应用到大量巧妙的负载移交设计,旨在尽可能提升高性能计算负载的运转性能。

这不禁让我们想到了所谓Slingshot 400,其将从明年秋季起通过“Shasta”Cray EX系统进行交付,具体包括一款新的“Rosetta-2”交换机ASIC和新的“Cassini-2”网络适配器ASIC。这些设备的完整馈送与速率数据尚不明确,但我们推测HPE已经将工艺升级至台积电的7纳米制程,借此降低两款ASIC的运行功耗。看起来Rosetta SerDes上的本机信号将被加倍,每通道可达56 Gb/秒和112 Gb/秒。因此在可用SerDes数量和端口数量相同的情况下,每端口的速度将倍增至最高400 Gb/秒。Cassini-2的速度可能也会以同样的方式迎来倍增。如果Slingshot 400在明年的这个时间点上市,并附带一系列针对交换机和NIC的超级以太网功能,也完全在情理之中。
我们还推测,HPE正按照计划在未来的Slingshot 800(可能于2027年秋季推出)中实现800 Gb/秒的速度,而更远之后的Slingshot 1000(可能在2029年秋季推出)的速度将达到1.6 Tb/秒。第一步飞跃相对容易,只需要将本机信号速度加倍即可。但很难想象如果不增加每条通道的端口数量并尽可能降低速度,要如何实现每端口1.6 Tb/秒的速度。实际结果可能是每个端口的通道数量增加一倍,速度为800 Gb/秒,因此信号增强后的实际速度为1.6 Tb/秒。我们唯一可以确定的是,随着AI爆发推动高端系统的销售势头,以太网必然成为未来的行业标准,意味着HPE早晚会与博通、英伟达以及思科在交换机和适配器ASIC市场上展开带宽军备竞赛。
未来一年的计算升级路径
说完了网络,接下来咱们再聊聊计算。Cray EX和ProLiant XD(此前曾用名为Cray XD)明年都将迎来计算引擎增强功能。
Cray Shasta系统已经存在了好几年,其以HPE的Slingshot互连为主干,提供多种计算引擎选项。高性能计算中心能够以混搭的方式利用这些选项来支持各种工作负载。例如,劳伦斯利弗莫尔国家实验室的2.79百亿亿次“El Capitan”超级计算机就是由Cray EX4000机箱构建而成。事实上,2024年11月全球超算Top500榜单中排名前十的超级计算机中,有七台都基于Cray EX平台;排名前二十的机器中则有十台基于Cray EX。考虑到欧洲高性能计算中心向来不愿在欧盟以外采购产品,能达成这样的比例无疑相当令人瞩目。
美国劳伦斯伯克利国家实验室的“Perlmutter”系统使用Cray EX235n刀片服务器。该款刀片服务器混合了AMD“Milan”Epyc 7763处理器以及英伟达A100 GPU加速顺。美国洛斯阿拉莫斯国家实验室的“Venado”系统和瑞士 CSCS 的“Alps”系统均采用基于英伟达“Grace”CG100 CPU和“Hopper”H100 GPU的Cray EX254n刀片服务器。美国橡树岭国家实验室的“Frontier”系统、意大利能源集团Eni的“HPC6”系统以及芬兰科学计算中心的“Lumi”系统均采用基于定制款“Trento”Epyc CPU和“Aldebaran”MI250X GPU的Cray EX235a计算刀片。当然,也有美国阿贡国家实验室的“Aurora”超算系统选择了英特尔的定制款刀片服务器,其上装有两块带有HBM内存的“Sapphire Rapids”至强9470 CPU和六块“Ponte Vecchio”Max GPU。据我们所知,这些刀片都没有产品编号,因此无法从HPE处直接订购。最后,劳伦斯利弗莫尔的 El Capitan 和它的兄弟机型、来自桑迪亚国家实验室的“El Dorado”机器均基于混合MI300A计算引擎。该引擎将AMD“Genoa”CPU芯片同“Antares”GPU芯片混合在同一封装之内,每台Cray EX255a刀片安装有八个封装单位。
2025年,EX4000机柜将推出两款Cray EX计算刀片:

有趣的是,HPE为即将推出的Cray EX4252 Gen2计算刀片选择了“Turin”Zen 5c芯片,而非缓存容量更大的普版Zen 5,也就是旗舰级Turin处理器的变体。HPE为其即将推出的AMD计算刀片选择的Epyc 9965 CPU拥有192个Zen 5c核心,基础时钟速率为2.25 GHz,而HPE没有选择的Epyc 9755则拥有 128个Zen 5核心,运行速率为2.7 GHz。很多朋友可能认为在高性能计算场景中时钟速率才是最具决定意义的因素,但根据我们的估计,前一款芯片的整数与矢量计算性能要比后者高出约四分之一,而且这款性能更高的芯片在性价比方面也比后者高出8.6%。
如此看来,HPE的CPU选择其实相当明智。
总而言之,每块刀片服务器上安装有8块Epyc 9965,一台EX400机柜中可以容纳64块刀片,也就是说单台液冷机架内总计可容纳98304个核心。根据我们的计算,按照基础时钟速率为2.25 GHz来考虑,每个插槽将具备2.345造成万亿次性能。如果是按纯CPU形式来配置,那么每台EX4000机柜的基础性能仍然保持在1.77千万亿次;如果按全部核心超频计算,则该机柜的峰值理论性能可达到2千万亿次。在500机柜的配置下,即可构建起全CPU的百亿亿次超级计算机。拥有10.51千万亿次算力的K超级计算机可说是有史以来最令人印象深刻的纯CPU机器,其位于日本理化研究所,在2011年全面建成时拥有800台机柜。
但现在已经是2024年,现在只要5台AMD CPU机架(总计49.1520万个核心)即可与当初的800台Sparc64-VIIfx处理器机架(总计8.8128万个核心)相媲美。K计算引擎显然采用高度矢量化设计,而且需要消耗大量电力——但其在当时的先进性仍不容置疑。
说回正题,EX4252 Gen 2计算刀片将于2025年初投放市场。
到2025年底,HPE计划发布EX154n计算刀片,明显是与英伟达的Grace-Blackwell GB200 NVL4计算系统板的上市时间对标。(图表中显示的是145n,但正确名称应该是154n。)后续我们会另开专题,单独讨论英伟达的NVL4单元。简单来讲,它就是两块Grace CPU加四块Blackwell GPU,共同使用单一系统板上的NVLink端口在六路共享内存集群内实现互连。我们猜测官方会称其为“超级芯片”……
GB200 NVL4系统板将允许HPE将224张Blackwell GPU放入单一EX400机柜中的56块刀片之内。Grace-Blackwell综合体则因太过宽大且发热量惊人,因此Ex4000机柜必须空出八个计算插槽。可即便如此,满满一机柜的配置也只能将性能提升至略高于10千万亿次,搭配42 TB HBM3E堆叠内存。再加上另外52.9 TB的LPDDR5内存和8064个Arm架构“Demeter”Neoverse V2核心,即可在NVL4系统板上的连贯NUMA空间内执行计算任务。
就是说仅靠100台满载NVL4系统板的机柜,我们就能在FP64精度下突破百亿亿次的浮点算力大关。这相当于AMD Turin Epycs计算密度的五倍。但也别高兴得太早,二者在FP64算力性价比方面的差距其实相当有限。
咱们来做一点简单计算。英伟达Blackwell GPU在以2:1的比例匹配Grace CPU时,其成本可能在4万美元左右;Epyc 9965的采购成本则仅为14813美元。一整套塞满Epyc 9965处理器(共计192块)的EX4000机架将花费大约272万美元,而英伟达B200机架将花费大约900万美元。可以肯定的是,性能提升了5倍但价格仅提高至3.3倍绝对是种改进。但跟CPU相比,GPU计算引擎的性价比仅仅高出了35%——即Blackwell的每万亿次浮点运算成本为889美元,而Turin每万亿次浮点运算成本为1362美元。
HBM内存的高成本,也至少在原始FP64计算性能方面进一步缩小了CPU跟GPU间的性价比差距。所以问题在于,我们到底能不能发挥出全部性能,又该为其匹配什么样的工作负载?为了找出问题的答案,必然需要自主运行基准测试来一探究竟。
除了Cray EX系列的网络和计算升级之外,机器中使用的闪存也得到了相应提升:
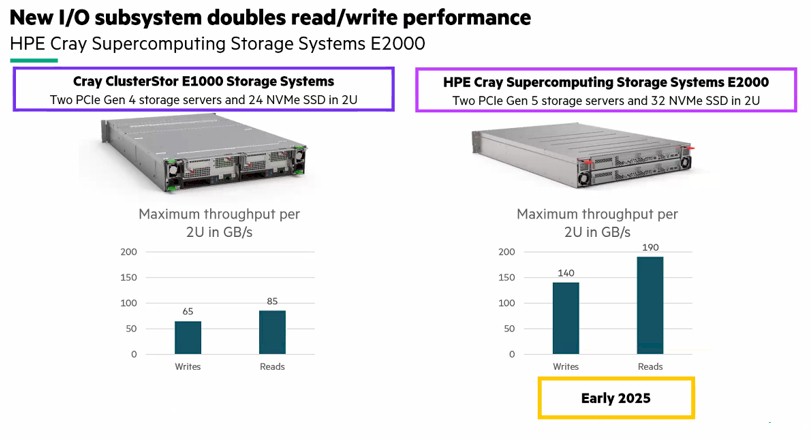
新款Cray E2000全闪存阵列拥有32块NVM-Express闪存驱动器和两台配备PCI-Express 5.0插槽的存储服务器,其读写性能达到前代E1000系统的两倍以上。
最后让我们来看ProLiant XD系列设备,这些机器主要面向习惯于使用基板管理控制器(在HPE的产品线中对应iLO,即Integrated Lights Out卡)的AI服务提供商和大型企业客户,而且不需要过度追求机器密集度或者液冷设计。(当然,ProLiant XD还是为机箱中的关键组件提供了液冷配置。)
HPE近期正在筹备两款新的ProLiant XD八路加速系统:

其中ProLiant XD680搭载两块“Emerald Rapids”至强SP处理器与八块Gaudi 3加速器,CPU与GPU均来自英特尔。这款产品将在今年年底前上市。这也不难理解,毕竟英特尔自己也承认市场对Gaudi 3的需求低于预期,所以供应量应该是相当充足。
ProLiant XD685则在主分区上配备两块AMD Turin Epyc CPU,同时提供八块英伟达Hopper/Blackwell GPU或者八块AMD“Antares”MI300X/MI325X GPU的选项。该机器将提供风冷和液冷两个版本,计划于2025年年初投放市场。
好文章,需要你的鼓励


OpenAI发布ChatGPT Work平台并扩大GPT-5.6部署范围
OpenAI推出企业级智能体平台ChatGPT Work,可跨应用自动执行多步骤工作任务,生成文档、演示文稿及电子表格等业务内容。同步推出的GPT-5.6系列模型涵盖Sol、Terra、Luna三档,主打"更低成本、更强性能"。Sol在编码、网络安全及复杂推理基准测试中表现突出,定价为每百万输入tokens 5美元。新模型还支持Microsoft 365、Google Drive等企业应用集成,并引入max与ultra两种推理模式以应对复杂工作负载。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

DJI发布AP100降落伞,为Matrice 400无人机提供紧急安全保障
大疆发布AP100降落伞,专为旗舰级Matrice 400企业无人机设计。该配件重约935克,支持自动与手动两种部署方式,可在600毫秒内触发展开,将无人机下降速度控制在每秒5米以内。AP100作为独立安全模块运行,配备独立飞控、传感器及备用电容,断电后仍可持续工作一小时。此外,内置飞行终止系统可在展开前切断电机,防止螺旋桨缠绕。该配件还支持欧盟EASA和英国CAA的C5/C6等级合规认证,适用于超视距飞行任务,防护等级IP55,适应-20°C至50°C宽温环境。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2024
12/02
10:24
分享
点赞

DJI发布AP100降落伞,为Matrice 400无人机提供紧急安全保障
什么是纯内存VPN服务器?它真的更安全吗?
Anthropic即将为Claude Cowork推出移动端远程控制功能
Meta利用CXL技术将旧DDR4内存回收再利用,服务器数量减少25%
Vercel v0 无代码开发平台深度评测
IBM Bob升级:从代码生成扩展至全软件开发生命周期管理
美国电动车快充进入"充电2.0"时代意味着什么
拇指大小的闪存,或将解决AI内存瓶颈难题
NordVPN混淆服务器切换至自研NordWhisper协议,速度更快覆盖更广
OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
HPE Gen12:英特尔至强6加持,数据中心和边缘计算的“新宠”
据报道,慧与同埃隆.马斯克的X公司签署价值10亿美元的人工智能服务器大单
HPE谈2025年合作伙伴激励包:Alletra MP、Private Cloud AI、VM Essentials均属于最高倍薪酬类别
小型超算中心基础设施电气设计要点
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
HPE CEO谈超算优势、VM Essentials市场机会和财报业绩
HPE计划在2025年全面升级超级计算机阵容
直击SC24:NVIDIA发布AI突破性进展 催化多行业再度“进化”
HPE发布用于AI和高性能计算的新超级计算机平台和服务器
从“夕发朝至”到“智算为王”:智算平台成企业“大模型”时代成功关键
