
直击SC24:NVIDIA发布AI突破性进展 催化多行业再度“进化” 原创
实时流体动力学模拟的流畅性,计算化学的精密度,天气预测的准确性,药物开发的突破......这些领域都正充分发挥利用AI的潜能。
最近的SC24大会上,NVIDIA 创始人兼 CEO 黄仁勋和加速计算副总裁 Ian Buck 共同发布了一系列全新的工具和框架,以提高各类复杂任务的运行效率。借助这些新产品,科研人员能够在实验室里更快地推演流体的运动规律,化学家们能够更高效地理解分子的相互作用,气象学家们能够更精确地预判天气变化,制药专家们则可以更迅速地进行药物筛选.....

可以说,这些AI驱动的新工具正在重新定义人与世界的关系。在参与科学探索的叙述之中,人类正蜕变为与未知对话的“共鸣者”,而AI正承担着将科学从孤立的抽象推理转变为一种更具连结性、更多维度的耦合作用。
CUDA-Q攻坚“量子壁垒”
量子计算是信息科技领域的一次重大跃迁,被视为解锁复杂科学与技术难题的关键。从药物设计到气候模拟,再到精密的金融分析,量子计算的潜力几乎无处不在。通过这种先进的计算技术,科学家和工程师可以更快地解析复杂的化学结构,预测全球气候变化的趋势,以及优化全球金融市场策略。
然而,量子计算的实现面临诸多挑战,其中之一便是在量子计算器件的设计与开发方面。量子比特的稳定性和噪声控制是设计过程中的关键难题。量子比特极其敏感,任何微小的环境变化都可能导致误差,严重限制量子运算的持续时间和准确性。此外,量子硬件的可扩展性也是一大挑战,需要在保持量子态稳定的同时,扩大系统以支持更多的量子比特。这些技术需求不仅难以克服,而且涉及巨额的计算资源和资金投入。

此次,NVIDIA 与谷歌量子AI展示了新的突破。通过利用 NVIDIA 的 CUDA-Q 平台,谷歌量子AI 在NVIDIA Eos超级计算机上使用 1024 个 NVIDIA Hopper Tensor Core GPU,以极低的成本进行世界上最大、最快的量子器件动态模拟。这一进展显著提高了模拟的规模和效率,大幅降低了成本。据了解,借助 CUDA-Q 平台,原本需要数周才能完成的复杂噪声模拟,现在仅需很短时间即可完成。

谷歌量子 AI 的研究科学家 Guifre Vidal 表示:“要想开发出商用的量子计算机,就必须能够在控制噪声的情况下扩展量子硬件规模。借助 NVIDIA 加速计算,我们正在探索越来越大的量子芯片设计中噪声的影响。”
通过CUDA-Q和 Hopper GPU,谷歌量子AI 可以进行包含40量子比特的大规模量子器件的全面模拟,这是同类模拟中规模最大的。这种模拟能力极大推动了量子计算技术的进步,为量子计算器件的设计和优化提供了有力的支持。
Omniverse Blueprint开创实时数字孪生工作流
对于航空航天、汽车、制造、能源等行业来说,保证工程进度和精度是对项目的重要考量标准。在工程设计环节中,仿真起到了至关重要的作用。它通过在虚拟环境中对设计方案进行测试与优化,可以帮助工程师在早期发现潜在问题,降低开发风险。
然而,由于仿真设计的迭代周期较长,工程师通常需要数天甚至数周才能获得仿真反馈,严重拖慢了开发进度,导致错失市场机会。同时,仿真模型的复杂性和计算资源的限制也使设计的精度难以保障,导致后期可能发现设计缺陷,从而增加了返工和修改成本。
事实上,传统仿真一般依赖于有限元方法(FEM)和有限体积方法(FVM),计算时间长且资源消耗大,尤其在处理非线性问题时效率低下。此外,由于跨部门协作受阻,缺乏实时的有效交互,导致数据传递滞后,影响了整体协同工作效率,拖慢了整体的工程进度。
从仿真精度层面看,随着制造、能源等行业对精密度和效率的需求日益增长,大规模数据激增导致需要大量的高效并行计算,而传统的仿真工具难以在短时间内完成多次迭代,且无法快速响应复杂的设计,导致精度下降,从而降低了工程的开发效率和竞争力。
其实,随着实时的物理数字孪生技术(实时仿真技术)的发展,为工业设计、工程和仿真带来了全新的可能性。
NVIDIA 最新发布的NVIDIA Omniverse Blueprint(以下称“蓝图”)正凭借先进的计算流体动力学(CFD)仿真能力,让传统需要数周乃至数月的工程设计优化过程得以在实时环境中完成,极大缩短了开发周期。
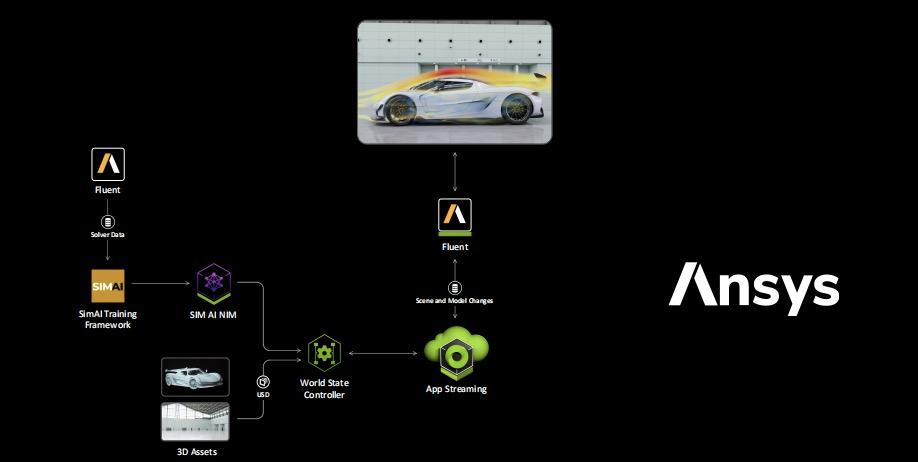
该“蓝图”通过整合 NVIDIA CUDA-X 库、NVIDIA Modulus 物理 AI 框架,以及 Omniverse API,构建了一个完整的实时物理求解和可视化解决方案,帮助开发者实现实时物理仿真与大规模数据集的实时渲染。不仅可以整体集成到现有工具中,也可以作为模块化组件使用,使企业更灵活地实现数字孪生系统的构建。
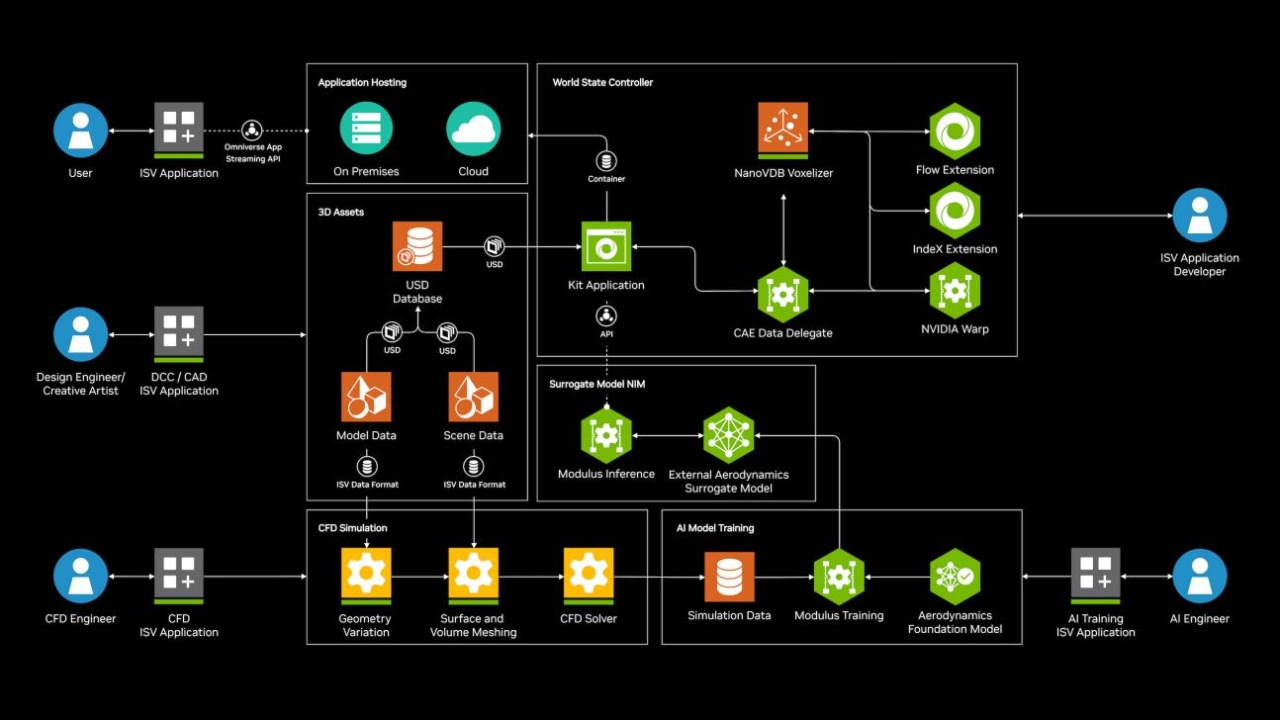
实时数字孪生不仅在性能上带来了巨大提升,更在设计创新中扮演了重要角色。通过实时反馈的闭环设计过程,从仿真 AI、求解器计算到分析可视化,再到设计优化,工程师们能够不断调整和改进设计,以前所未有的速度推动工程创新。
在 SC 24大会上,NVIDIA 与 Luminary Cloud 联合展示了“虚拟风洞”案例,这一创新案例可以实现对流体动力学的实时交互式仿真和可视化,甚至支持用户动态更改风洞内的设计模型。

例如,Ansys 已率先将 Omniverse Blueprint应用于其 Fluent 流体仿真软件,在 Texas Advanced Computing Center 的 NVIDIA Grace Hopper 超级芯片上实现了大规模加速仿真。这使得原本需要近一个月的仿真任务得以在短短六个多小时内完成,显著提升了高保真 CFD 分析的可行性。
NVIDIA Omniverse Blueprint 正在引领这一革命性变革,让实时设计成为驱动未来工程创新的重要引擎。
“我们构建Omniverse是为了让万物都能拥有数字孪生。Omniverse Blueprint是打通NVIDIA Omniverse与AI技术的参考管线。借助该蓝图,领先的CAE软件开发商能够构建出开创性的数字孪生工作流,为全球各大行业实现从设计、制造到运营的工业数字化转型。”NVIDIA创始人兼首席执行官黄仁勋说。
BioNeMo 优化科研效率
在药物研发领域,生物信息学和人工智能在生命科学领域的应用逐渐成为变革的关键驱动力。传统的药物研发过程犹如漫长的马拉松,平均需要耗费十年以上的时间和数十亿美元的资金,这一过程不仅充满了挑战,还伴随着巨大的不确定性。为了应对这些挑战,越来越多的企业和研究机构正转向人工智能和高性能计算的帮助,希望借助科技的力量,以前所未有的速度和精度加速药物研发的进程,降低高昂的开发成本,推动创新药物的诞生。

NVIDIA 此次推出的全新一代 BioNeMo 平台,面向生命科学,旨在加速药物研发和分子设计,通过提供多样化的 AI 模型和高效计算工具,极大优化了药物开发的效率和成本。
BioNeMo 平台包括三大核心组件:BioNeMo 框架、BioNeMo NIM 微服务和 BioNeMo Blueprints。BioNeMo 框架是一套免费使用的编程工具和软件包,研究人员可以借此访问和定制生物分子模型,探索分子生成、蛋白质结构预测等任务,
NIM 微服务则专注于企业级推理,适合需要稳定、高效推断的生产场景,如化合物筛选和蛋白质预测,让推理工作流如流水线般顺畅、高效。
BioNeMo Blueprints则提供了针对湿实验室和计算工作流的优化参考设计,帮助企业简化药物研发中的复杂流程,特别是虚拟筛选和小分子设计等应用,让整个研发过程如同搭积木般灵活、简单。
BioNeMo 平台的推出为研究人员提供了从模型开发到推理部署的端到端支持,缩短了药物研发时间,并降低了成本。借助 BioNeMo 平台,研究人员可以共享和复用 AI 模型与工作流,促进跨领域的协作和知识共享,激发更多未知的探索。NVIDIA 还发布了适用于 BioNeMo 的一系列经过优化且易于使用的全新 NIM 微服务。无论是在本地数据中心还是云端,这些微服务都能与现有 IT 基础设施无缝集成,为整个生物制药行业提供更高效的计算能力和推理支持,推动创新药物的诞生。
此外,为了提升研究者的工作效率,NVIDIA还发布了 cuPyNumeric 加速计算库,旨在帮助科学家在不修改现有 Python 代码的情况下,利用 GPU 加速提高数据处理能力。这一库使得科研人员能在从笔记本电脑到超级计算机的任何设备上快速运行数据分析,极大地缩短了从数据到发现的时间。
目前,澳大利亚国立大学、洛斯阿拉莫斯、斯坦福大学、印度国家支付公司等多个国家级研究机构已经开始利用这一新工具,提升其研究效率。
引领TOP500榜单
在本次SC24会议上,TOP500组织公布了全球最强超算TOP500榜单,再次引发全球业界热议,NVIDIA成为瞩目焦点。
在此次TOP500榜单中,384套系统由NVIDIA技术驱动。而新增的53套系统中,有87%采用了 NVIDIA 加速技术,其中85%采用了NVIDIA Hopper GPU。
自2006年发布CUDA以来,NVIDIA不断推动AI与加速计算技术的发展,今年的TOP500榜单再次证明了其在超级计算领域的卓越成就。NVIDIA的加速计算平台不仅在数量上具有显著优势,其性能表现也十分亮眼。平台提供超过190艾级浮点运算的性能,并在单精度(FP32)和双精度(FP64)领域分别实现了17艾级和4艾级浮点运算的突破,充分展现了平台在多样化计算需求中的高效性和灵活性。
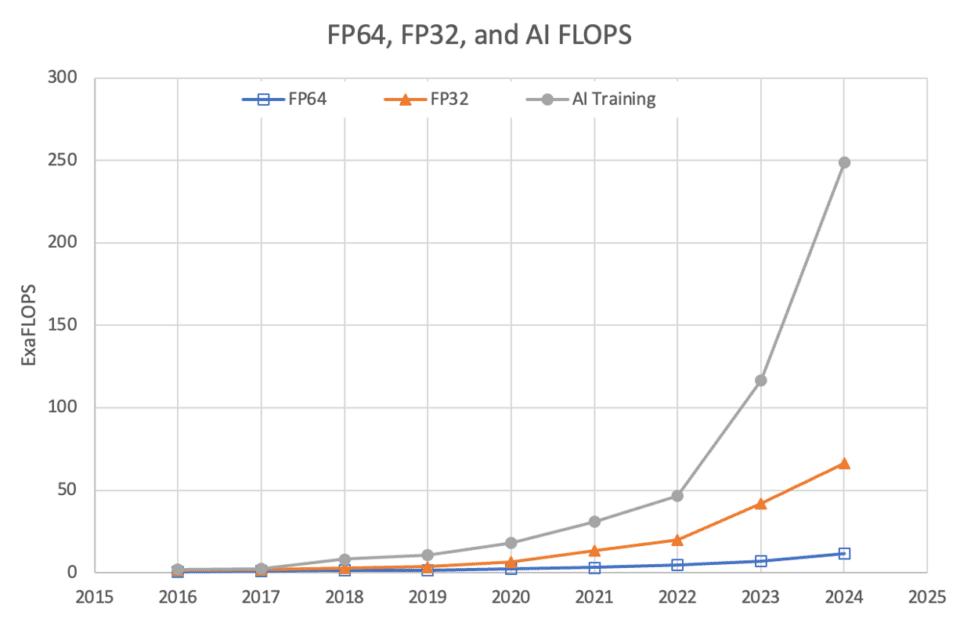
此外,NVIDIA在可持续、绿色计算方面展现了卓越的能力。随着计算需求增长,可持续性成为不可忽视的课题。在Green500榜单中,前10名中有8个系统由采用NVIDIA加速计算的系统占据,进一步凸显了其在性能与能效兼顾方面的领先优势。其中,尤利希超级计算中心的JEDI系统,以每瓦72.7千兆浮点运算的表现成为性能与可持续性的典范。
从TOP500榜单中的加速系统占比到Green500的能效表现,NVIDIA正重塑超级计算未来的新定义。在气候预测、药物研发、量子模拟等领域,NVIDIA Hopper GPU和加速计算平台正为科学界和工业界提供更快、更高效的工具。通过持续创新,NVIDIA不仅推动AI与加速计算从尖端研究走向行业应用,也为超级计算在性能和可持续性之间找到平衡提供了更多可能性。
值得注意的是,NVIDIA在超级计算,更是取得了诸多社区的认可。荣获11项HPCwire读者与编辑选择奖,。这些奖项涵盖了最佳AI产品、最佳HPC互连产品、最佳HPC服务器等多个领域。
NIM突破性进展,助力材料研发与天气预测
此次,NVIDIA还推出了一系列创新性的NIM 微服务。这些微服务在推动可持续材料研发和改善气象预报技术方面显示出巨大潜力。
ALCHEMI NIM 微服务是为助力化学模拟设计的 AI推理工具,通过优化模拟流程,显著加速了材料科学研究。在新材料的研发过程中,ALCHEMI NIM可大规模模拟化合物和材料的稳定性,大幅降低成本和能耗,同时提高研发速度。据了解,运行NVIDIA高性能GPU上的 MACE-MP-0 模型,在模拟潜在混合物的长期稳定性时,这项全新的 NIM 微服务可以实现高达 100 倍的评估速度提升。使用 NVIDIA Warp Python 框架进行高性能模拟时实现了 25 倍的加速,而并行批处理实现了 4 倍的加速。
据测算,完成评估 1600 万个结构曾经需要几个月的时间,而借助 NIM 微服务则只需几个小时即可完成。

ALCHEMI NIM 不仅能加快材料的发现过程,还可以实现从实验室到生产线的转换。其为材料的生产和实际应用提供了前所未有的支持,如电池、太阳能电池板和其他重要工业组件的生产。
与 ALCHEMI NIM 同时发布的还有基于 NVIDIA 的数字孪生云平台 Earth-2 的全新 NIM 微服务—— CorrDiff NIM、FourCastNet NIM 。 CorrDiff NIM 和 FourCastNet NIM能够分别针对高分辨率和中期粗分辨率天气预报进行了优化,大幅提升气候模型的运算速度,使气象预报的精确度和效率达到质的飞跃。

CorrDiff NIM 微服务利用生成式 AI 模型实现了公里尺度的超高分辨率天气预报,极大地提高了对极端天气事件的预测能力。这对于准确预测降雪、结冰和冰雹等事件至关重要,特别是在灾害管理和应急响应领域。与传统的高分辨率数值天气预报系统相比,CorrDiff NIM 微服务的运算速度提高了 500 倍,能效提升了 10000 倍。
FourCastNet NIM 微服务则提供了全球范围内的中期粗分辨率天气预报,通过 AI 技术实现了前所未有的速度和规模。该服务能在极短的时间内处理大量数据,生成未来两周的天气预报,其速度比传统数值天气模型快 5000 倍,极大地提升了气候技术提供商的服务能力和响应速度。
好文章,需要你的鼓励


西班牙病毒如何将谷歌带到马拉加
33年后,贝尔纳多·金特罗决定寻找改变他人生的那个人——创造马拉加病毒的匿名程序员。这个相对无害的病毒激发了金特罗对网络安全的热情,促使他创立了VirusTotal公司,该公司于2012年被谷歌收购。这次收购将谷歌的欧洲网络安全中心带到了马拉加,使这座西班牙城市转变为科技中心。通过深入研究病毒代码和媒体寻人,金特罗最终发现病毒创造者是已故的安东尼奥·恩里克·阿斯托尔加。

多伦多大学发现:聊天机器人的“嘴巴“影响它们的智商
这项由多伦多大学领导的研究首次系统性地揭示了分词器选择对语言模型性能的重大影响。通过训练14个仅在分词器上有差异的相同模型,并使用包含5000个现实场景测试样本的基准测试,研究发现分词器的算法设计比词汇表大小更重要,字符级处理虽然效率较低但稳定性更强,而Unicode格式化是所有分词器的普遍弱点。这一发现将推动AI系统基础组件的优化发展。

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
人工智能安全公司Cyata发现LangChain核心库存在严重漏洞"LangGrinch",CVE编号为2025-68664,CVSS评分达9.3分。该漏洞可导致攻击者窃取敏感机密信息,甚至可能升级为远程代码执行。LangChain核心库下载量约8.47亿次,是AI智能体生态系统的基础组件。漏洞源于序列化和反序列化注入问题,可通过提示注入触发。目前补丁已发布,建议立即更新至1.2.5或0.3.81版本。

北大研究团队颠覆视频AI训练新方法:让机器像人类一样“预测下一帧“学习世界
北京大学研究团队提出NExT-Vid方法,首次将自回归下一帧预测引入视频AI预训练。通过创新的上下文隔离设计和流匹配解码器,让机器像人类一样预测视频下一帧来学习理解视频内容。该方法在四个标准数据集上全面超越现有生成式预训练方法,为视频推荐、智能监控、医疗诊断等应用提供了新的技术基础。
2024
11/22
14:27
分享
点赞

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
Mill如何与亚马逊和全食超市达成合作协议
TechCrunch创业大赛中的9家顶尖生物技术初创公司
2025年印度科技领域十大重要发展
中科大发布Live Avatar:AI数字人无限聊天不翻车
从软件定义汽车到AI驱动质控:Testin云测助力车机测试数智化价值落地
无需Linux即可运行自由开源软件
超越 SEO:AI 引擎优化如何改变在线可见性格局
新Mac必装应用:五款提升工作效率的神器推荐
DXC蒲公英计划:为神经多样性IT专业人士赋能
AMD Strix Halo与Nvidia DGX Spark:哪款AI工作站更胜一筹?
类人机器人投资热潮涌现但商业化仍需数十年
