
Triton推理服务器05-安装服务器软件
在前一篇文章已经带着读者创建一个Triton的推理模型仓,现在只要安装好服务器端与用户端软件,就能进行基本的测试与体验。
为了简化过程,我们使用NVIDIA Jetson AGX Orin设备进行示范,所有步骤都能适用于各种基于NVIDIA Jetson智能芯片的边缘设备上,也适用于大部分装载Ubuntu 18以上操作系统的x86设备上,即便设备上没有安装NVIDIA的GPU计算卡也能使用,只不过上我们的提供的内容都是基于GPU计算环境,对于纯CPU的使用则需要用户自行研读说明文件。
现在就开始安装Triton服务器软件,NVIDIA为Triton服务器提供以下三种软件安装的方式:
- 源代码编译:
这种方式需要从https://github.com/triton-inference-server/server下载源代码,然后安装依赖库,再用cmake与make工具进行编译。通常会遇到的麻烦是步骤繁琐,并且出错率较高,因此并不推荐使用这个方法。
有兴趣者,请自行参考前面下载的开源仓里的docs/customization_guide/build.md文件,有关于Ubuntu 20.04、Jetpack与Windows等各种平台的编译细节。
- 可执行文件:
Triton开发团队为使用者提供编译好的可执行文件,包括Ubuntu 20.04、Jetpack余Windows平台,可以在https://github.com/triton-inference-server/server/releases/ 上获取,每个版本都会提供对应NGC容器的版本,如下图:

然后到下面的“Assets”选择合适的版本:
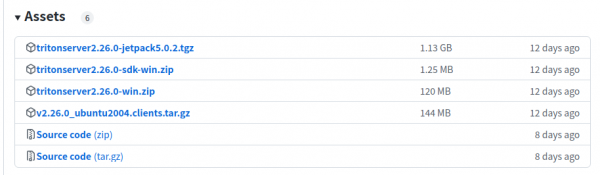
以装载Jetpack 5的Orin为例,就下载tritonserver2.26.0-jetpack5.0.2.tgz(1.13GB) 压缩文件到本机上,然后解压缩到指定目录下就可以,例如${HOME}/triton目录,会生成<backends>、<bin>、<clients>、<include>、<lib>、<qa>等6个目录,可执行文件在<bin>目录下。
在执行Triton服务器软件前,还得先安装所需要的依赖库,请执行以下指令:
|
$ $ |
sudo apt-get update sudo apt-get install -y --no-install-recommends software-properties-common autoconf automake build-essential git libb64-dev libre2-dev libssl-dev libtool libboost-dev rapidjson-dev patchelf pkg-config libopenblas-dev libarchive-dev zlib1g-dev |
现在就可以执行以下指令启动Triton服务器:
|
$ $ |
cd ${HOME}/triton bin/tritonserver --model-repository=server/docs/examples/model_repository --backend-directory=backends --backend-config=tensorflow,version=2 |
如果最后出现以下画面并且进入等待状态:
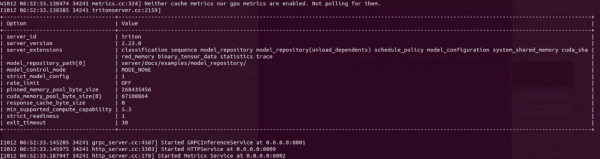
现在Triton服务器已经正常运行,进入等待用户端提出请求(request)的状态。
- Docker容器:
在NGC的https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags可以找到Triton服务器的Docker镜像文件,每个版本主要提供以下几种版本:
- year-xy-py3:包含Triton推理服务器,支持Tensorflow、PyTorch、TensorRT、ONNX和OpenVINO模型;
- year-xy-py3-sdk:包含Python和C++客户端库、客户端示例和模型分析器;
- year-xy-tf2-python-py3:仅支持TensorFlow 2.x和python后端的Triton推理服务器;
- year-xy-pyt-python-py3:仅支持PyTorch和python后端的Triton服务器;
- year-xy-py3-min:用作创建自定义Triton 服务器容器的基础,如Customize Triton Container(自定义Triton容器)说明文件所描述的内容;
其中“year”是年份的数字,例如2022年提交的就是“22”开头;后面的“xy”是流水号,每次往上加“1”,例如2022年10月4日提交的版本为“22-09”。
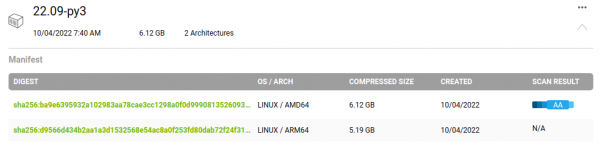
NVIDIA提供的Triton容器镜像是同时支持x86/AMD64与ARM64架构的系统,以22.09-py3镜像为例,可以看到如下图所标示的“2 Architectures”:

点击最右方的“向下”图标,会展开如下图的内容,事实上是有两个不同版本的镜像,不过使用相同镜像名:
因此在x86电脑与Jetson设备都使用相同的镜像下载指令,如下:
|
$ |
docker pull nvcr.io/nvidia/tritonserver:22.09-py3 |
就能根据所使用设备的CPU架构去下载对应的镜像,现在执行以下指令来启动Triton服务器:
|
$
$ |
# 根据实际的模型仓根目录位置设定TRITON_MODEL_REPO路径 export TRITON_MODEL_REPO=${HOME}/triton/server/docs/examples/model_repository # 执行Triton服务器 docker run --rm --net=host -v ${TRITON_MODEL_REPO}:/models nvcr.io/nvidia/tritonserver:22.09-py3 tritonserver --model-repository=/models |
如果执行正常,也会出现以下的等待画面,表示运行是正确的:
以上三种方式都能在计算设备上启动Triton服务器软件,目前看起来使用Docker镜像是最为简单的。当服务器软件启动之后,就处于“等待请求”状态,可以使用“Ctrl-C”组合键终止服务器的运行。
有一种确认Triton服务器正常运行的最简单方法,就是用curl指令检查HTTP端口的状态,请执行以下指令:
|
$ |
curl -v localhost:8000/v2/health/ready |
如果有显示“HTTP/1.1 200 OK”的信息(如下图),就能确定Triton服务器处于正常运行的状态:
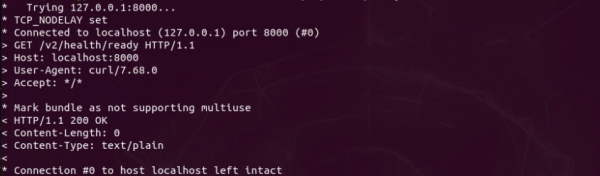
接下去就要安装客户端软件,用来对服务器提出推理请求,这样才算完成一个最基础的推理周期。【完】
来源:业界供稿
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2023
01/03
16:55
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
