
Jetson Nano 2GB 系列文章(16):10 行代码威力
在上一篇文章中,我们为大家介绍了 Hello AI World 环境安装,本篇文章将会带着大家感受 10 行代码的威力。
要感受这个项目的效果,最好的方式就是先体验一下它能带来的好处。因此一开始我们就为大家提供一个比较经典的范例,只用 10 行的 python 代码,实现对 90 种类别的深度学习物件检测(object detection)识别,在 Jetson Nano 2GB 上达到 10+FPS 性能。
对于不了解深度学习物件识别的初学者来说,可能不会有太多感受,但是稍微了解这个应用的人就会很清楚,即便非常优秀的 YOLOv4 算法或者 SSD-Moblienet 算法,在 Jetson Nano 2GB 上,能做到 4~6FPS 已经不容易了。但是在这里我们不去探索这些算法的内容,因为研究算法需要比较深厚的数学基础才行。
现在我们就来看看 Jetson-inference 这个开源项目是如何做到这个结果的,这里将代码呈现给大家,直接解说每一行的用途。详细的代码如下:

在说明代码之前,建议先把这段代码敲进你的 Jetson Nano 2GB 设备里,当然这个代码也适用于 Jetson 全系列产品,自行取个文件名,例如 “10lines.py” ,可以在设备中的任何一个位置。
这里唯一要先说明的地方就是第二行的蓝色部分,这里演示的摄像头是 CSI,所以蓝色参数部分用 “csi://0”,如果您只用 USB 摄像头,只需把这个地方根据您实际的摄像头编号,改成 “/ dev / video0” 即可。
假如没有 USB 摄像头,还需找到通用格式的视频文件,把参数部分改成视频文件的完整路径名,或者把视频文件复制到这个代码的位置。最简单的视频文件可以在你 Nano 上的 “/ usr / share / visionworks / sources / data ” 下面。
其他地方无需修改。存档后执行以下指令:

第一次执行时,系统会为我们选择的神经网络模型(这里是第 5 行的 “ssd-mobilenet-v2”)去生成对应的 NVIDIA TensorRT 加速引擎,这个过程大约需要 10 分钟的时间,因此并不是当机,还请耐心等候,以后再执行相同模型时,就只需要十多秒就可以了。
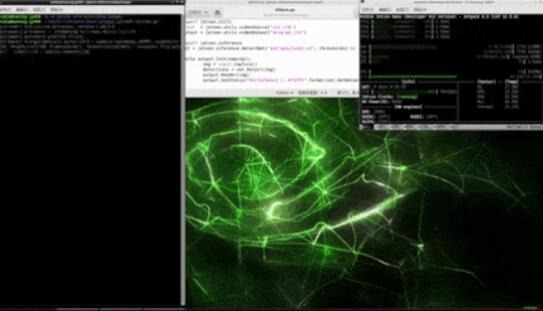

如何,是不是很神奇呢?只用 10 行的 Python 代码就能实现这样的功能!
接下来就解密一下这些代码的内容,让大家体会一下 jetson-inference 为大家所打造的一个非常强大的深度学习工作环境,主要包括 “视觉深度神经网络库(Vision DNN Library)” 与 “ 工具库 (Utilities Library)”。
代码第一行 “import jetson.utils” 就是导入工具库模块,接下去透过 videoSource() 建立 input 对象、videoOutput() 建立 output 对象,关于这两部分的细节,将在接下来的文章中进一步说明。
第四行 “import jetson.inference” 就是载入本项目最重要的 “深度学习推理应用” 的模块,然后用 detectNet() 建立 net 对象,处理后面的 “物件检测推理识别” 物件检测推理识别的任务,这部分至少需要给定 “模型代号” 变数以及作为检测最低要求的阈值(threshold)。
本系统最贴心的地方,就是为每个参数值都提供一个预设值,如果你忘记了给定设定值,系统还可以正常执行。
在 while 循环里,第 7 行从数据源读取一帧图像,然后到第 8 行用一个非常简单的 net.Detect(img) 函数,就能把这张图像中满足阈值的物件找出来,存放到 detections 数组中,这是非常亮眼的一个功能。
而让我们觉得更为惊奇的是,这么一道简单指令,在我们看到的地方,已经非常紧密地集成了 NVIDIA 非常强大的 TensroRT 加速引擎,立即将性能提升了数倍以上。
很多熟悉 NVIDIA 深度学习的人,都知道 TensorRT 的性能是多么令人惊羡,但集成过程又是那么地让人揪心,如今在这个项目中,初学者完全不必面对调用 TensroRT 的艰难,却能立即享受到如此优异的性能。
接下来,还有令人惊喜的地方,第 9 行这么简单的 “output.Render(img)” 指令,可以将 detections 数组里所有检测到的物件,包括框 / 颜色、类别名称、置信度这些数据,全部叠加到图像上,并且显示到画面上。
没错,就是这么一道短短的指令,居然做了这么多的事情。如果自己写过代码去将这些数据全部叠加在一起,就非常清楚这个步骤需要花费多少代码去执行。
最后,利用一个 “net.GetNetworkFPS()” 函数就轻松获取这一帧图像的计算性能,然后用 output.SetStatus() 将这些数据在显示框顶上实时更新。
如何,这样一个 10 行 Python 代码是不是很厉害呢?这里先让大家感受一下这个开源项目的厉害之处,后面的文章将带着大家深入学习几个最重要、最常用的函数内容,让读者可以循序渐进地用这些资源,开发出自己专属的应用。
来源:业界供稿
好文章,需要你的鼓励


Google Health 5.0 正式推出,安卓端新增数据统计小组件
Google Health 5.0作为Fitbit应用的更新版本正式推出。在安卓端,新版本引入了主屏幕快捷访问小组件,取代原有的圆形步数小组件,可显示最多六项健康指标,支持自定义缩放。点击小组件可跳转至完整统计页面,左上角心形图标可快速打开应用,右侧可直达Health Coach功能。此次更新还启用了全新Google Health图标,移除Fitbit品牌标识。安卓版已于5月19日开始推送,5月26日前全面覆盖。

当电脑学会用尺规作图:中国科学院团队让AI真正“画“出几何题
中科院团队发现顶级AI在几何作图上成功率不到6%,推出PAGER系统将精度提升4.1倍,揭示AI能力评估的关键盲点。

奥迪A2 e-tron入门级电动车将为品牌注入新活力
奥迪宣布将推出入门级纯电动车型A2 e-tron,旨在降低豪华电动车的拥有门槛。该车型基于大众最新MEB平台打造,预计提供50kWh、58kWh和79kWh三种电池选项,续航最高可达630公里。目前原型车正在瑞典北部极寒环境及巴伐利亚道路进行测试,重点验证热管理与电池性能。新车预计售价约4万美元,将于今年秋季正式亮相。

浙江大学联手京东研究院:让AI视频训练快6倍的“闪电秘诀“
浙江大学等机构提出Flash-GRPO视频AI训练新方法,通过同时段分组和梯度校正两项创新技术,实现训练速度提升6倍且质量更优。
2021
04/26
16:44
分享
点赞

AI落地深水区的技术账本:软件质量治理如何破解工程化瓶颈
Google Health 5.0 正式推出,安卓端新增数据统计小组件
周中绿色优惠:Juiced Scrambler电动自行车、Lectric XPress2及多款储能产品特惠来袭
NAMUGA机器人视觉业务向"头部"延伸,加速布局高端机器人解决方案
AMD Silo AI与博洛尼亚大学携手开展空间AI合作,聚焦机器人与自动驾驶领域
Remepy混合疗法帕金森治疗方案即将进入三期临床试验
Exa Labs完成2.5亿美元融资,估值达22亿美元
派拉蒙CIO规划AI规模化路径,CTO即将卸任
量子计算面临安全威胁与人才短缺双重挑战
IrisGo:由吴恩达投资的AI桌面智能体,让工作流程自动化成为现实
OpenAI宣称用AI推翻了一个困扰数学界近80年的猜想
Linus Torvalds坦言对AI又爱又恨:工具有用,但挑战真实存在
