
大胆拆分,英特尔代工业务反而可能迎来重振

对英特尔公司来说,现在似乎正是放弃代工业务的最佳时机。
尽管前任CEO Pat Gelsinger就先进半导体制造业务提出了令人信服的理由,但他的愿景从起步之初就存在缺陷。英特尔的代工业务就如同十年之前IBM公司的微电子业务一样,属于纯粹的负价值资产。但与此同时,维持这项负资产对于美国而言又属于在AI半导体竞赛当中保持竞争优势的战略之选,绝对不可动摇。如果当初经济危机下的金融机构有着大而不能倒的属性,那么英特尔的代工设施对于美国国家利益也是同样关键的基础能力且意义重大。
因此对于Intel Foundry Services(简称IFS)代工业务,以下几个核心问题必须找到答案:
- 先进半导体制造业对于美国国家安全及全球竞争力是否至关重要?
- 这部分制造能力是否需要由总部位于美国的企业所掌控?
- 如何有效为英特尔的代工业务拆分提供资金支持?
- 在拆分之后,哪些利益相关方对于代工实体的长期成功至关重要?
- 新的实体需要多长时间才能在市场上建立起竞争力?
本文将通过分析概述一项大胆计划,即拆分英特尔的代工业务,并依靠其他科技巨头、私募股权以及政府资金等多个利益相关方的投资,并与台积电或三星电子等行业领导者间建立起战略合作伙伴关系——这是因为目前只有台积电或三星拥有设计、建造以及运营现代代工设施,并在合理时间之内实现盈利所必需的专业知识。
拆分英特尔代工业务的理由
之所以做出拆分英特尔代工业务的决定,主要基于以下严酷的经济现实:
- 市场动向:
英特尔的x86业务是其晶圆产能的核心驱动力,但已经长期处于衰退状态。相比之下,台积电主导的Arm处理器至少拥有十倍于前者的晶圆需求量级。英特尔缺乏在先进半导体制造业维持生存的必要规模。
- 赖特定律与成本挑战:
根据赖特定律,随着累计产量的增加,制造成本也会随之下降。英特尔的晶圆产量较低,导致制造成本最多比台积电高出30%至35%。除此之外,英特尔在各个新的制程节点上实现有竞争力的产量方面也比台积电落后约一年。
- 难以承受的亏损:
英特尔的代工业务正在大量吞噬现金。截至今年4月,该公司报告称在190亿美元的收入之下 ,其运营亏损已经高达70亿美元,收入也同比下降31%。这样的财务状况根本无法持续。
- 竞争力不足:
随着制程节点变得越来越昂贵(例如,2纳米制程的晶圆单片价格已高达2.5万美元),英特尔的市场竞争力表现正在减弱。如果不加以干预,代工设施将继续拖累英特尔的整体业务,导致其他本应具有巨大发展潜力的业务分支被其榨干。
如何拯救美国的先进半导体制造产业
关键假设
- 美国制造能力至关重要:
在美国本土维持半导体制造能力,对于国家安全及经济韧性至关重要。
- 美国自主权至关重要:
必须坚持由总部位于美国的实体对关键知识产权的控制力,由此减轻地缘政治引发的风险。
建议的解决方案
英特尔董事会必须意识到其代工业务的负面价值并果断采取以下行动:
- 将IFS代工业务拆分为合资企业:
与台积电(或三星)合作,利用对方在先进半导体制造业方面的专业知识。
- 与战略利益相关方合作:
从美国各科技巨头(包括Alphabet、亚马逊、苹果、Meta Platform、微软以及英伟达等)以及CHIPS芯片法案及私募股权公司/公共基金处获取投资。我们认为埃隆·马斯克也应参与此项计划。
- 重新分配CHIPS芯片法案划拨的资金:
将为英特尔预留的80亿至100亿美元重新分配给多家利益相关合资企业,以确保美国先进半导体制造产业的长期可持续性。同时对其余部分的CHIPS芯片法案资金也应做重新统筹与划拨。
为拆分提供资金支持:多利益相关方参与方案
成功拆分英特尔代工业务,离不开各家不同利益相关方的协同贡献,具体如下表所示:
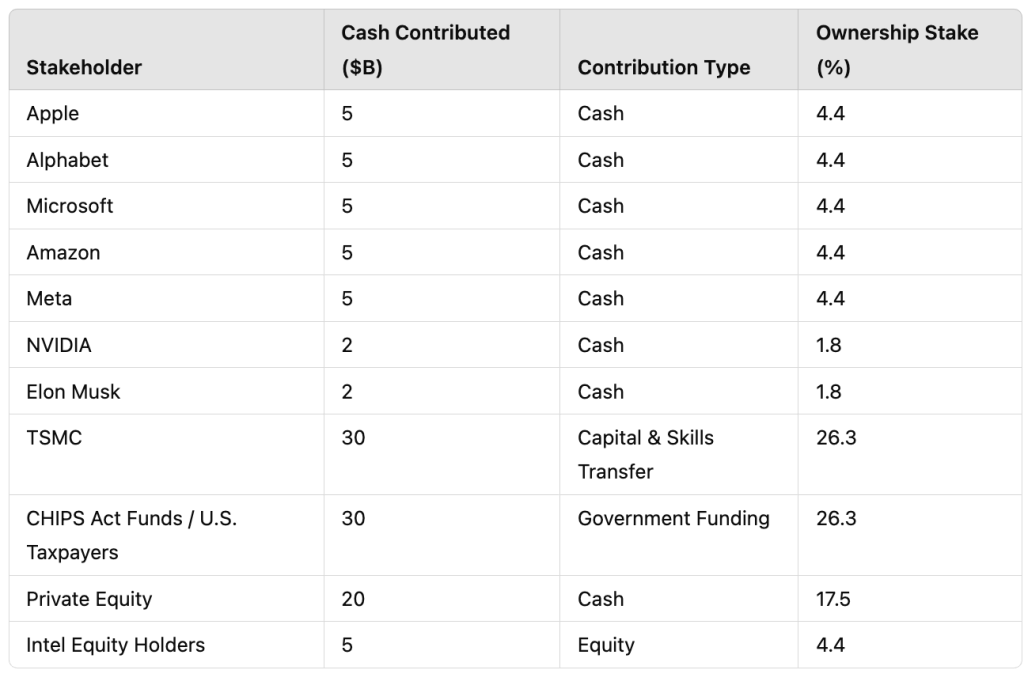
备注:苹果、Alphabet、亚马逊、微软、Meta以及英伟达目前资产负债表上的现金加流动证券的总金额超过5000亿美元。
结论
英特尔的代工业务对于这样一家净资产为负的公司来说已成一项关键、但不具备可持续性的业务。理想的解决方案并非直接放弃,而是通过协作方式对其加以改造。由各科技巨头、私募股权及美国政府战略投资共同支持的拆分实体,将创造出一股具备市场竞争力的独立半导体制造力量,维护美国在半导体领域的先进地位。
这样一家合资企业还须以联手台积电(或者三星电子)作为运营基础,借此确保获取成功所需的专业知识,同时减轻英特尔的财务负担。这条道路不仅有助于挽救重要国家资产,同时也符合更广泛的行业以及地缘政治需求。如果不果断采取行动,英特尔将面临破产风险,且最终也无法实现美国在半导体领域保持领先的愿景——这方面风险绝对不容忽视。
常见问题
- 英特尔为什么要放弃其代工制造设施,转而只在新的合资企业中占据少数股权?
- 采取这一措施的理由与IBM在2014年做出的决定完全相同。如今英特尔的代工业务已经裹挟并拖累了整个公司,而且我们认为如果英特尔试图与台积电争夺先进半导体代工产能,将必然陷入破产局面。每过一天,其蒙受更大损失的风险都会增加,也将导致复兴英特尔的计划不断延后。如果不推行彻底变革,该公司将根本拿不出足够的现金或者时间维持自身在先进半导体制造领域的生存。此外,我们认为英特尔在先进技术与半导体制造方面的投资属于负资产,且价值仍在缩水,这主要源自晶圆厂的建设与运营成本过高的基本事实。英特尔已经不可能挺得过与台积电竞争所需要的六年建设时间,以及接下来长达十年的盈利前过渡阶段。
- 美国政府为什么要支持这项举措?
- 因为其目前的计划过于依赖注定失败的英特尔代工业务,而且CHIPS芯片法案的资金划拨过于分散,无法产生可持续的影响。我们认为调整后的方案将大大增加其成功几率。
- 这家合资企业需要多长时间才能在市场上建立起竞争力?
- 至少需要十年。我们认为至少需要三家代工厂的建设与运营周期。每一家代工厂建立起切入点,第二家代工厂达到稳定状态,第三家代工厂实现盈亏平衡。每个周期将至少持续两年,还要额外再加上一年半或两年才能带来可接受的经济回报。根据我们最乐观的估计,这家合资企业也需要10到12年才可能成长为具备竞争力的市场参与者。
- 为什么科技巨头会愿意参与建立这家合资企业?
- 有两个原因:1)在美国本土保留可行的半导体供应源;2)作为参与并支持的回报,美国政府将同意为各家企业提供合理的方便之门,并停止对这些企业的拆分。为了摆脱美国政府的反垄断打击,各家科技巨头无疑会认真考虑加入。
- 台积电为什么会愿意与这家合资企业合作?
- 有三个原因:1)台积电将成为这家合资企业的最大股东;2)能够对冲迫在眉睫的地缘政治风险;3)让台积电更受美国政府乃至美国整体技术生态的青睐。
- 为什么私募股权公司会愿意为这一长期投资规划提供支持?
- Apollo及Brookfield等公司已经向英特尔代工业务投入了数十亿美元,他们不愿承受这些设施可能一文不值的风险。其他面向科技领域的私募股权公司也可能愿意参与这笔交易,在保护自身投资的同时为美国保留一家本地半导体供应商。
- 为什么埃隆马斯克会对于参股这家合资企业抱有兴趣?
- 马斯克比任何人都更清楚,技术产业的未来取决于稳定的芯片供应链。他拥有相应的财力,他辖下的企业、特别是特斯拉公司,对于半导体设计也抱有兴趣。另外通过这样的“小笔”投资,他也能更好地规避遗产税。
- 美国政府应当在其中持有大比例股权吗?
- 不应该。美国政府应当随时间推移剥离其头寸,并以减债形式将收益返还给纳税人。
- 是否还有其他利益相关方应该或者可能参与?
- 是的,有这种可能。鉴于IBM与GlobalFoundries间的合作及其深厚的研发专业知识,其同样能够为这家合资企业的健康发展贡献力量。应当鼓励IBM参与其中。
- GlobalFoundries或者其他美国晶圆厂(例如德州仪器或者美光科技)是否也应参与进来?
- 可能不会。阿联酋主权财富基金穆巴达拉投资公司是GlobalFoundries的最大股东,其面临的巨大争议可能并不适合参与。此外,德州仪器和美光科技主要专注先进程度不高的芯片制程技术,并在其专注的细分市场上表现良好。美光晶圆厂专注于内存研发,包括高带宽内存,这虽是推动AI发展的另一大关键组件,但对合资企业而言并不重要。
- 博通以及电子设计自动化领域的其他关键参与者是否适合介入?
- 可能适合,但这些企业不具备之前提到的各家科技巨头那庞大的资金储备。
- 美国国防部及北约是否适合参与?他们应该为合资企业提供资金支持吗?
- 是的,我们认为这将是行之有效的投资方向。
- 为什么不选择从零开始,在一张白纸之上建立“美国半导体公司”?
- 因为在我们看来,这将导致实现竞争力及盈亏平衡的时间周期将延长一倍。英特尔已经拥有实体代工设施,其资产负债表上约有价值1000亿美元的厂房、物业及设备(PPE)。从头开始建设这些资产将大大拉高成本。尽管英特尔面临困境,但其在先进半导体制造方面已经取得了重大进展,足以为这项计划提供良好的开端。
- 鉴于英特尔在厂房、物业及设备方面的贡献,为何不使其在新实体中掌握更高的股份比例?
- 也许可以。对于英特尔来说,代工业务拆分的真正价值在于摆脱沉重包袱,轻装上阵以专注于设计创新。与AMD相似,在摆脱代工拖累之后,英特尔将成为半导体设计领域的一股强大力量。但至少英特尔还可获得其他形式的利益,包括用自己的设施贡献换取晶圆代工厂的优先使用权以及一段时间内的价格优惠。
- 新实体应当采取怎样的治理结构?
- 在我们看来,经营结构及董事会层面的权力应当保持平衡。台积电负责贡献关键知识产权,因此必须保证其对合资企业的运营方式拥有发言权。与此同时,合资企业将是一家美国公司,所以应当拥有一支致力于让美国半导体制造业重夺竞争优势的高管团队与独立董事会。任何单一利益相关方都不应独自掌握过大的权力,以避免其改变这家合资企业的既定使命与发展愿景。
好文章,需要你的鼓励



一个模型,随心切换延迟——英伟达与中研院联手打造的万能语音净化引擎
英伟达与台湾中研院提出一种实时通用语音增强框架,单模型支持30种延迟配置,通过并行卷积层和早退机制分别控制算法与计算延迟,性能接近专用模型。

家用储能电池如何在飓风与极端高温中支撑电网稳定运行
随着飓风、热浪等极端天气频繁冲击美国电网,家庭储能电池与虚拟电厂(VPP)正成为维持电网稳定的关键手段。数千名户主将家用电池和电动车电池接入电网,在用电高峰期协同削减数千兆瓦负荷。特斯拉Powerwall年产量近70万台,其加州VPP容量已超100MW,2024年累计向用户支付约990万美元。分析预测,2028年前住宅储能装机将达10GW,VPP模式有望降低电网扩容成本并推动能源去碳化。

Meta开发的AI编程助手,真的懂你吗?还是需要你反复“纠正“它才能干活?
Meta团队推出SWE-Together评测框架,将真实用户与AI编程的多轮对话转化为可复现的测试题,首次将"用户需要纠正AI多少次"纳入评分体系。
2024
12/19
15:10
分享
点赞

瑞士巴塞尔大学研发微型口腔牙科机器人可自动钻牙
我如何整理散落在网络各处的数千张照片和视频
极端高温考验电网,电动校车"反向充电"成救星
OpenAI拟向美国政府出让股权,科技巨头争相布局AI云服务
恒帅股份美国汽车微电机工厂投产,1500万美元基地承接39.34%境外收入
阿里云百炼推出Agentic RAG服务,让AI的知识检索和回答更精准
聚焦全球化增长赛道, Unity 再度登陆 2026 ChinaJoy BTOB
5060 Ti 16GB 跑本地 AI,真不如加钱买二手 3090?
家用储能电池如何在飓风与极端高温中支撑电网稳定运行
散热为什么成了AI算力的“阀门”?
亚马逊 Mechanical Turk 将停止接受新用户注册
量子力学百年演进:从费解理论到改变世界的技术基石
