
英特尔至强6性能核处理器性能显著提升
随着企业数字化转型进程的加速及新兴技术的大规模应用,业界对多元化、高质量和绿色算力的需求与日俱增。近期,英特尔发布的英特尔® 至强® 6性能核处理器,凭借创新的微架构、显著提升的核心数量、双倍内存带宽,以及对PCIe 5.0和CXL 2.0等最新技术的支持等领先特性,实现了整体性能的显著提升,能够应对边缘、数据中心、云环境的严苛挑战,是数据中心的理想选择。
在云计算领域,相比上一代处理器,至强6性能核处理器能够提供多达2倍的每路核心数,并实现平均单核性能提升1.2倍、每瓦性能提升1.6倍,且帮助云服务提供商(CSP)在同等性能水平下实现平均30% TCO的显著下降。在科学计算中,至强6性能核处理器则凭借MRDIMM实现更强存力,并通过英特尔® AVX-512输出更高算力,从而实现2.31倍NEMO geomean代际性能提升、2.43倍OpenFOAM geomean代际性能提升,以及2.5倍HPCG代际性能提升。
现阶段,以深度学习、机器学习等算法为代表的AI技术正步入高速发展时期,对计算资源的需求急剧增加。而得益于内置的AI加速功能——英特尔® 高级矩阵扩展 (AMX) 和专门面向AI优化的英特尔® AVX-512提高性能与效率,至强6性能核处理器凭借在运行AI工作负载上展现出的卓越性能,已成为数据中心和CSP的优选机头。
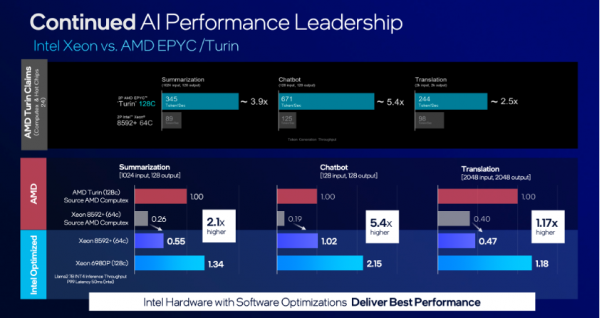
值得注意的是,在软件优化的加持下,至强6性能核处理器能够在运行多元化AI工作负载时展现出最佳性能。如在运行7亿参数的Llama2 INT4推理任务时,至强6性能核处理器提供了比AMD Turin 128核处理器更高的吞吐量。而在诸如文本摘要、聊天机器人和翻译这类生成式AI应用中,至强6性能核处理器分别展现出了约2.1倍、5.4倍及1.17倍的性能提升。
此外,在最新的MLPerf推理v4.1基准测试中,至强6性能核处理器与第五代至强处理器相比,实现了AI性能约1.9倍的几何平均值提升。特别是在自然语言处理任务BERT上,其相比第三代至强处理器性能提升高达17倍,而在计算机视觉任务ResNet50上,性能提升也高达15倍。而这主要得益于至强6性能核处理器的先进架构,包括对英特尔AMX的支持,以及优化的内存带宽等创新。
现阶段,以至强6900P系列处理器为代表的至强6性能核处理器已上市,并被诸多CSP广泛应用至实践中。面对AI时代对算力多元、高效的需求,英特尔通过持续加速创新,打造包括至强6处理器在内的领先硬件,以及开发者首选的软件工具、开发套件和优化库,从而助力生态伙伴以提升的性能拓展新商机,并实现关键业务成果。
好文章,需要你的鼓励



一个模型,随心切换延迟——英伟达与中研院联手打造的万能语音净化引擎
英伟达与台湾中研院提出一种实时通用语音增强框架,单模型支持30种延迟配置,通过并行卷积层和早退机制分别控制算法与计算延迟,性能接近专用模型。

家用储能电池如何在飓风与极端高温中支撑电网稳定运行
随着飓风、热浪等极端天气频繁冲击美国电网,家庭储能电池与虚拟电厂(VPP)正成为维持电网稳定的关键手段。数千名户主将家用电池和电动车电池接入电网,在用电高峰期协同削减数千兆瓦负荷。特斯拉Powerwall年产量近70万台,其加州VPP容量已超100MW,2024年累计向用户支付约990万美元。分析预测,2028年前住宅储能装机将达10GW,VPP模式有望降低电网扩容成本并推动能源去碳化。

Meta开发的AI编程助手,真的懂你吗?还是需要你反复“纠正“它才能干活?
Meta团队推出SWE-Together评测框架,将真实用户与AI编程的多轮对话转化为可复现的测试题,首次将"用户需要纠正AI多少次"纳入评分体系。
2024
10/22
12:46
分享
点赞

瑞士巴塞尔大学研发微型口腔牙科机器人可自动钻牙
我如何整理散落在网络各处的数千张照片和视频
极端高温考验电网,电动校车"反向充电"成救星
OpenAI拟向美国政府出让股权,科技巨头争相布局AI云服务
恒帅股份美国汽车微电机工厂投产,1500万美元基地承接39.34%境外收入
阿里云百炼推出Agentic RAG服务,让AI的知识检索和回答更精准
聚焦全球化增长赛道, Unity 再度登陆 2026 ChinaJoy BTOB
5060 Ti 16GB 跑本地 AI,真不如加钱买二手 3090?
家用储能电池如何在飓风与极端高温中支撑电网稳定运行
散热为什么成了AI算力的“阀门”?
亚马逊 Mechanical Turk 将停止接受新用户注册
量子力学百年演进:从费解理论到改变世界的技术基石
