
英特尔:64核第五代至强芯片在AI基准测试上比AMD下一代128核EPYC不相上下
AI基准测试是客户进行芯片选型的重要评估手段。随着英特尔和AMD在CPU上运行的AI工作负载领域争夺领导地位,AI基准之战正在升温。
为了证明自己的产品在AI工作负载的表现,不管是英特尔还是AMD纷纷亮出自己在相关基准测试方面的结果。
前段时间,在COMPUTEX上,AMD的Zen 5 EPYC Turin在人工智能工作负载上比英特尔至强芯片快5.4倍。
但是近日,英特尔表示,正在上市的第五代至强芯片比AMD即将于2024年下半年上市的3nm EPYC Turin处理器更快。英特尔表示,AMD的基准对Xeon性能的描述“不准确”,并分享了自己的基准来反驳AMD的说法。
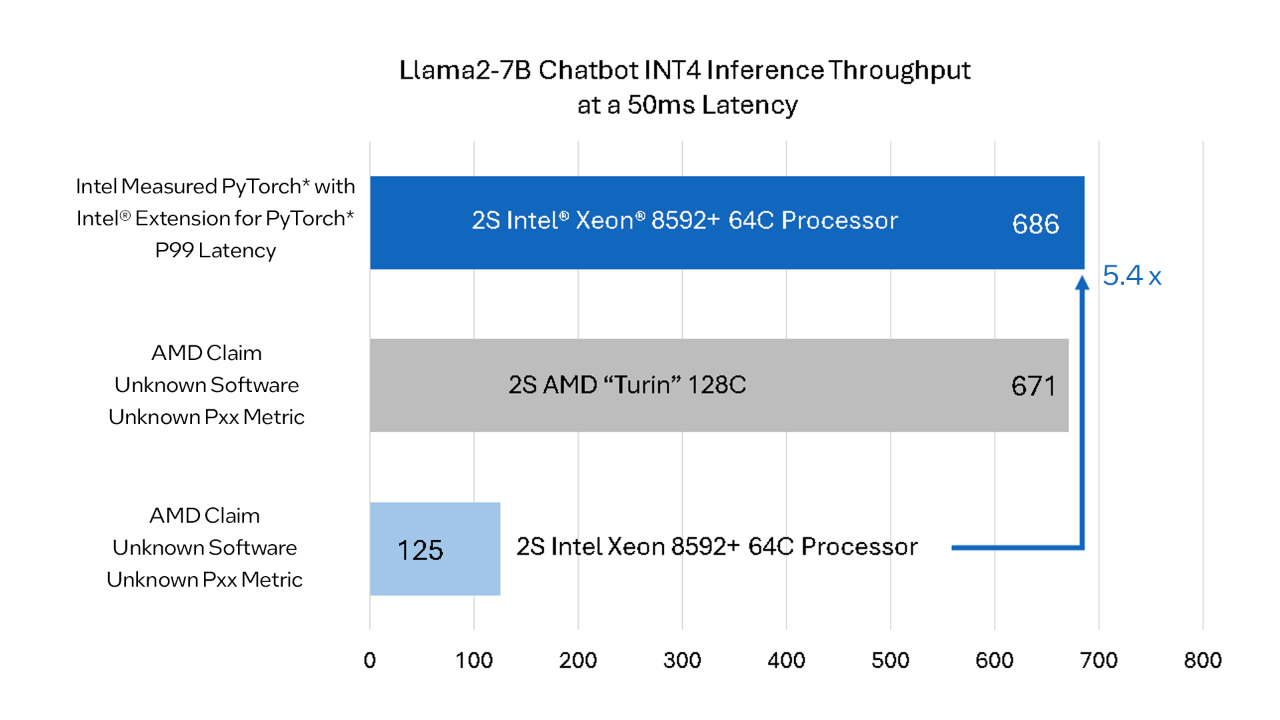
英特尔自己的内部测试结果显示,至强的性能表现并不逊色,比AMD的基准测试快5.4倍,这样比较起来,至强比EPYC Turin并不弱,这使得目前正在发售的64核Xeon相对于AMD未来的128核机型具有优势——这的确是一个相当令人印象深刻的说法,而且在性能上也有很大的变化。
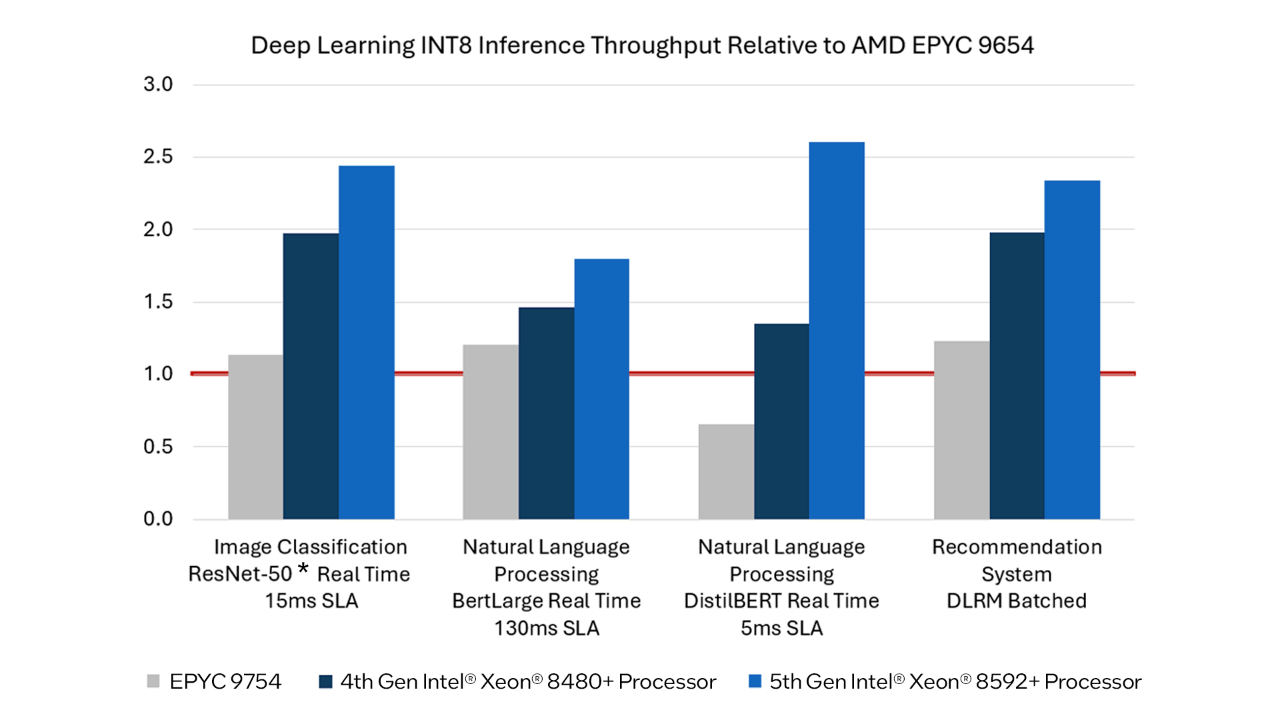
英特尔表示,AMD没有透露其用于基准测试的软件细节,也没有透露测试所需的SLA。AMD的测试结果与其内部广泛使用的开源软件(Intel Extension for PyTorch)并不匹配。
如果该基准测试代表真实性能,那么可能存在的差异是英特尔对AMX(高级矩阵扩展)数学扩展的支持。这些矩阵数学函数极大地提高了AI工作负载的性能,目前还不清楚AMD在测试英特尔芯片时是否采用了AMX。值得注意的是,AMX支持BF16/INT8,因此软件引擎通常会将INT4权重转换为更大的数据类型,以驱动AMX引擎。AMD的当前一代芯片不支持原生矩阵运算,目前还不清楚Turin是否也支持。
所以测试结果之所以出现这样的巨大差异,还是在软件调优。英特尔的硬件可利用软件框架和工具包进行加速,并获得出色的大模型推理性能,其中包括PyTorch和英特尔 PyTorch扩展包、OpenVINO工具包、DeepSpeed、Hugging Face库和vLLM。
来源:至顶网计算频道
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2024
06/14
17:28
分享
点赞

SpaceX疑似向投资者展示AI手持设备原型,马斯克否认
Meta计划对外出租AI基础设施,股价大涨近9%
Instagram算法定制功能升级,用户可更精准掌控内容偏好
AI时代Chiplet设计中不可或缺的可观测性层
从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
