
第一时间适配!英特尔锐炫GPU在运行Llama 3时展现卓越性能
在Meta发布Llama 3大语言模型的第一时间,英特尔即优化并验证了80亿和700亿参数的Llama 3模型能够在英特尔AI产品组合上运行。在客户端领域,英特尔锐炫™显卡的强大性能让开发者能够轻松在本地运行Llama 3模型,为生成式AI工作负载提供加速。

在Llama 3模型的初步测试中,英特尔®酷睿™Ultra H系列处理器展现出了高于普通人阅读速度的输出生成性能,而这一结果主要得益于其内置的英特尔锐炫GPU,该GPU具有8个Xe核心,以及DP4a AI加速器和高达120 GB/s的系统内存带宽。
英特尔酷睿Ultra处理器和英特尔锐炫显卡在Llama 3模型发布的第一时间便提供了良好适配,这彰显了英特尔和Meta携手为本地AI开发和数百万设备的部署所做出的努力。英特尔客户端硬件性能的大幅提升得益于用于本地研发的PyTorch和英特尔® PyTorch扩展包等丰富的软件框架与工具,以及用于模型部署和推理的OpenVINO™工具包。
在内置英特尔锐炫显卡的英特尔酷睿 Ultra 7上运行Meta-Lama3-8B-Instruct
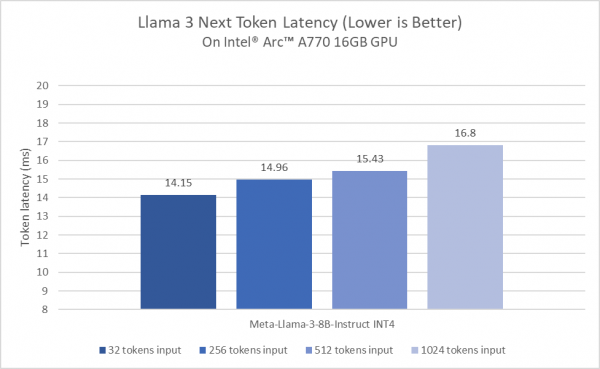
在英特尔锐炫A770上运行Llama 3的下一个Token延迟
上图展示了在搭配PyTorch框架和针对英特尔GPU的优化后,英特尔锐炫A770显卡在运行Llama 3模型时表现出卓越的性能。除此之外,英特尔锐炫显卡亦支持开发者在本地运行包括Mistral-7B-Instruct LLM、Phi2、Llama2等在内的大语言模型。
基于相同的基础安装,开发者可以在本地运行多种模型的主要原因,可以归功于IPEX-LLM,即一个针对PyTorch的大语言模型库。它主要基于英特尔® PyTorch扩展包打造,涵盖时下最新的大语言模型优化和低比特数据压缩(INT4/FP4/INT8/FP8),以及针对英特尔硬件的大多数最新性能优化。得益于如锐炫A系列显卡等英特尔独立显卡上的Xe核心XMX AI加速功能,IPEX-LLM能够显著提高性能,其支持在Windows子系统Linux版本2、原生Windows环境和原生Linux上的英特尔锐炫A系列显卡。
由于所有的操作和模型均基于原生PyTorch框架,开发者可以非常方便地更换或使用不同的PyTorch模型以及输入数据。而上述模型和数据不仅能够在英特尔锐炫显卡上运行,开发者亦能享受到英特尔锐炫显卡加速带来的性能提升。
产品和性能信息
英特尔®酷睿™Ultra处理器:
在英特尔酷睿Ultra 7 155H平台(MSI Prestige 16 AI Evo B1MG-005US)上进行测试,使用32GB LP5x 6400Mhz总内存,英特尔显卡驱动101.5382 WHQL,Windows 11 Pro版本22631.3447,平衡操作系统电源计划,最佳性能操作系统电源模式,极限性能MSI Center模式,已启用核心隔离,基于英特尔2024年4月17日的测试。
英特尔锐炫™A系列显卡:
在英特尔锐炫A770 16GB显卡上进行测试,使用英特尔酷睿 i9-14900K、华硕ROG MAXIMUS Z790 HERO主板、32GB(2x 16GB)DDR5 5600Mhz,Corsair MP600 Pro XT 4TB NVMe。软件配置包括英特尔显卡驱动101.5382 WHQL、Windows 11 Pro版本22631.3447、性能电源策略和核心隔离禁用。基于英特尔2024年4月17日的测试。
注释:
性能因使用情况、配置和其他因素而异。可在性能指数网站上了解更多信息。
性能结果基于所示日期的配置测试,可能不反映所有公开可用的更新。请参阅附件以了解配置详情。没有任何产品或组件可以绝对安全。
基于预生产系统和组件的结果,以及使用英特尔参考平台(内部新系统的内部示例)、英特尔内部分析或架构模拟或建模估算或模拟的结果,仅供参考。结果可能会因将来对任何系统、组件、规格或配置的更改而变化。
成本和结果可能会有所不同。
英特尔技术可能需要启用硬件、软件或服务进行激活。
来源:业界供稿
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

蚂蚁集团打造的AI“安全警卫“:当智能助手学会看图识险,多模态内容审核迎来新突破
蚂蚁集团AI安全实验室开发的SingGuard是一套多模态内容安全审核系统,能同时理解图片与文字的组合意图,并支持运行时动态传入自定义规则,实现策略自适应的安全判断。


Upstage AI研究员揭示:当AI被要求填写一张完整的表格,它究竟在哪里翻车了?
Upstage AI构建韩语宽度搜索基准KO-WIDESEARCH,测试20个AI系统填写完整结构化表格的能力,揭示AI善于找成员却难以填对每格的核心缺陷。
2024
04/23
16:50
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
