
英特尔打造软件定义汽车,为行业提供卓越性能和超高效率
英特尔为汽车行业打造芯片级增强版硬件虚拟化功能,助力打造软件定义汽车
借助英特尔市场领先的芯片级增强版硬件虚拟化功能,英特尔汽车事业部旨在为行业提供具有卓越性能和超高效率的软件定义汽车(SDV)的架构方案,帮助用户获得99%的高效率和零延迟。这一高性能计算平台提供了足够的空间来处理多个软件工作负载,充分满足了汽车用户对高质量和个性化体验的期望。
英特尔院士、英特尔公司副总裁、汽车事业部总经理Jack Weast表示:“英特尔具备业界兼具强大功能和能效的虚拟化实施方案。缺乏这一能力,汽车制造商将难以打造他们所设想的下一代车载体验,无法为用户提供反应灵敏、性能强大的车载系统。”
英特尔推出全新软件定义汽车架构方案,以满足汽车行业的需求。汽车行业一直在朝着软件定义的未来迈进,并尝试借助虚拟机管理程序以实现软件虚拟化。但这也带来了一个瓶颈——它无法满足当今工作负载对性能不断增长的需求。英特尔的芯片级增强版分离方案打造了一个能够绕过虚拟机管理程序的直接路径,并在软件内为更高质量和新的工作负载提供了额外的性能,从而使消费者获得他们所期待的下一代功能和服务成为可能。
这一方案的工作原理是什么呢?大家可以将运行软件定义汽车(SDV)所需的算力想象成一台满电的电动汽车(EV)。大家普遍认为,如果车辆从家里(A点)直接到达预定的目的地(B点),它的性能是优化了的,如果有差别也仅在于不同车辆之间的差异。这正是英特尔芯片级增强版硬件虚拟化功能的工作原理,它能够让工作负载更为快速的抵达硬件层。但是,如果电动汽车被迫绕道到另一个地点(C点),那么它必须消耗更多的核心能源,行驶在路上的时间也会更长。这种被迫的“绕道”,与其它芯片供应商的做法颇为相似,也就是说,在工作负载抵达底层硬件之前,在软件层面上实施了过多的虚拟化功能,相当于多绕路走了一段到C点的路。这种绕路,最终会导致明显的性能衰减。
抛开汽车路程的类比,路径中的更多细节也能彰显英特尔市场领先的虚拟化功能所带来的诸多优势。这些优势是基于图形处理器(GPU)来实现的。
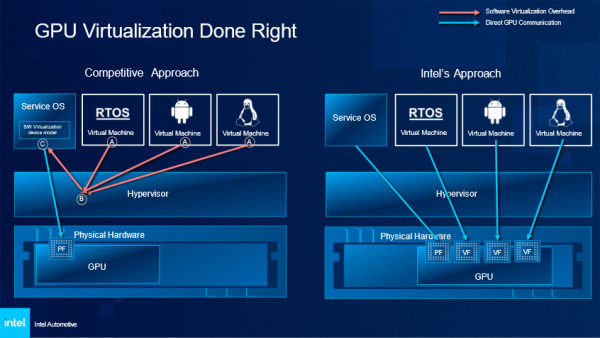
使用虚拟机管理程序的 GPU 软件虚拟化功能与英特尔基于硬件进行物理分隔的SDV之间的功能比较
上图显示了必须在软件中完成虚拟化,以及在芯片层面进行物理分隔所经过的不同路径。在图片左侧,想要通过虚拟机管理程序运行多个基于GPU的工作负载,虚拟机必须要先访问虚拟机管理程序,然后到服务操作系统(OS)层面,还需要额外的数百行代码,并使用宝贵的带宽,才能到达GPU。与之相对,当使用基于单根 I/O 虚拟化(SR-IOV)功能的英特尔SDV SoC时,每个工作负载都会被直接在GPU芯片层面分离,从而释放软件层,进而在零延迟的情况下实现更高的性能和功能。
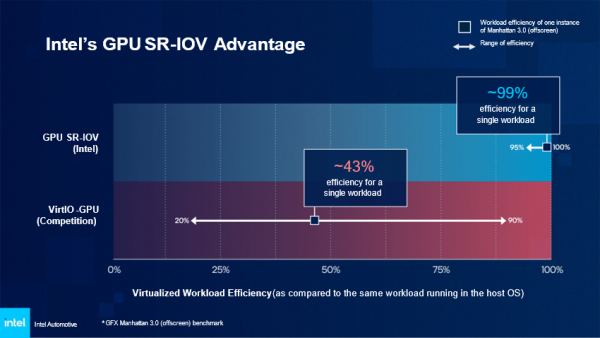
使用GFX Manhattan 3.0(离屏)的 SR-IOV和仅虚拟分离(VirtIO)的性能基准比较
第二幅图显示了英特尔SDV系统级芯片(SoC)与仅虚拟分离(VirtIO)方案相比下的效率优势。行业标准图形基准GFX Manhattan 3.0(离屏)的测试结果显示,在运行单一工作负载时,英特尔方案的运行效率可达99%,而竞争对手的运行效率约为43%。实际上,这意味着如果运行一个需要每秒100帧(FPS)的工作负载,使用英特尔解决方案,可以在零延迟的情况下获得99 FPS,而使用其他解决方案,只能获得43 FPS的速度,且还会遇到与工作负载相关的额外延迟。这个例子仅仅是英特尔市场领先的虚拟化功能的浅层优势。这些优势同样适用于基于AI的工作负载,甚至不使用GPU或AI加速器的无显示工作负载。
该方案的推出对于车载体验的提升有着非常重要的意义。虚拟化是开启用户所期待的下一代汽车体验的关键所在。有了它,驾驶员和乘客将体验到更灵敏、更强大的汽车,包括在玩游戏时获得更高的帧速率性能、体验到优美的3D地图应用程序而非继续使用2D地图,以及实现车内多个显示屏上的实时3D可视化,或通过实时AI 推理获得增强安全性等等。
这些功能的更新将通过便捷且稳定的OTA推送给用户。有了OTA,用户在汽车的整个生命周期内都能享受到最新的服务和功能。
来源:业界供稿
好文章,需要你的鼓励


维科精密泰国基地启动小批量生产,3.10亿元加码汽车电子精密部件
今天讲的出海案例是维科精密,这家汽车电子与功率半导体精密部件厂商正在泰国建设总投资3.10亿元的生产基地。

当AI的“记忆“在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

pgEdge推出ColdFront,加入OLTP与OLAP融合赛道以支持AI应用
随着AI智能体对实时数据访问需求激增,企业维护独立事务与分析系统的成本和复杂性日益凸显。Databricks、Snowflake、EDB等厂商纷纷推出融合架构。分布式PostgreSQL提供商pgEdge近日发布ColdFront测试版,采用冷热数据分层架构,自动将旧数据迁移至Apache Iceberg对象存储,同时保持PostgreSQL作为唯一应用接口。分析师指出,DuckDB正成为此类架构的事实标准嵌入式分析引擎,但由此产生的集中风险值得CIO关注。

AI代码修复工具真的需要每次都“跑一遍程序“吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。
2024
03/19
13:35
分享
点赞

pgEdge推出ColdFront,加入OLTP与OLAP融合赛道以支持AI应用
TabFM:面向表格数据的零样本基础模型正式发布
Netgear推出AI驱动网络管理平台,助力中小企业与服务商
旧笔记本、台式机与打印机该如何正确回收处理
美国NRC提出核废料处置新规,为长期搁置问题开辟出路
OpenClaw 智能体正式登陆 iOS 与 Android 平台
智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
