
英伟达“GRACE”ARM CPU在HPC领域力压X86

从种种方面来看,英伟达打造的“Grace”CG100服务器处理器都堪称其首款真正的服务器级CPU,也成为扩展“Hopper”GH100 GPU加速器(专为HPC仿真与建模工作负载而设计)内存空间的重要方案。目前,多家主要超级计算实验室都在对Grace CPU进行HPC测试,下面我们一起来看这些有趣的早期结果。
Grace CPU拥有相对较高的核心数量和相对较低的发热量,同时配备低功耗DDR5(LPDDR5)内存组(常见于笔记本电脑,但配合纠错机制来达到服务器应用级别)。目前常见的单节点内存容量通常在256 GB到512 GB之间,基本可以满足HPC工作负载的需求。
将两个Grace CPU组合成一个Grace-Grace超级芯片,即可获得一种使用NVLink芯片间互连的紧密耦合封装,能够在LPDDR5内存组之间保证内存一致性,且运行功耗仅为500瓦左右。这样的方案对HPC受众来说颇具吸引力,因为其能提供144个基于Armv9架构的Arm Neoverse“Demeter”V2核心,外加1 TB物理内存与1.1 TB/秒的峰值理论带宽。但出于某种原因,可能是LPDDR5内存为了保证更好的良品率,这样的组合只能实际提供960 GB内存容量和1 TB/秒的内存带宽。而如果愿意,英伟达完全可以创建一个四路Grace计算模块,整体包含288个核心和1.9 TB内存,同时提供2 TB/秒的聚合内存带宽。这样的四路处理器也许能卖出与上代或者上上代GPU相媲美的价格……
作为参考,我们在2022年3月刚发布时就对Grace芯片做过初步分析,并在2022年8月深入研究了Grace芯片架构(当时还没人确定英伟达到底使用怎样的Arm核心)。到2023年9月Arm发布架构详细信息之后,我们又对采用新架构的Demeter V2核心做过认真剖析。这里不再赘述,概括来讲,英伟达为Grace采用了Arm V2核心(而非自研核心),其中包含四个128位SVE2矢量引擎,基本相当于英特尔至强SP架构中使用的双AVX-512矢量引擎,因此可以用于运行经典的HPC工作负载、一部分AI推理工作负载(规模不能太大)、甚至可用于对中等规模的AI模型进行重新训练。
巴塞罗那超级计算中心同纽约州立大学石溪分校/布法罗分校最近公布的数据,也再次证实了这一判断。两个研究小组都发布了在各类HPC与AI基准测试中使用Grace-Hopper与Grace-Grace超级芯片的性能结果,也基本符合我们之前做出的猜测:从发热量和使用成本角度看,Grace CPU确实能够在HPC领域表现出一定的竞争力。
两个研究小组也都在上周于日本名古屋召开的HPC Asia 2024大会上发表了相关论文。巴塞罗那超级计算中心方面的文章题为《英伟达Grace超级芯片在HPC应用中的早期评估》(https://dl.acm.org/doi/abs/10.1145/3636480.3637284),石溪与布法罗分校研究小组的文章则题为《英伟达Grace CPU超级芯片与英伟达Grace Hopper超级芯片的科学工作负载初探》(https://dl.acm.org/doi/abs/10.1145/3636480.3637097)。两篇论文都介绍了如何在Grace-Grace与Grace-Hopper超级芯片上实际执行关键HPC应用程序。相对来说,纽约州立大学研究人员的论文更有指导意义,这主要得益于小组汇总了来自多家HPC中心和一家云服务商的性能数据,具体涵盖石溪分校、亚马逊云科技、匹兹堡超级计算中心、得克萨斯高级计算中心和普渡大学的性能数据。
巴塞罗那超级计算中心则将英伟达Grace-Grace与Grace-Hopper超级芯片(属于其MareNostrum 5系统实验集群的一部分)与上代MareNostrum 4超级计算机中的x86 CPU节点进行了性能比较,后者采用两块24核“Skylake”至强SP-8160 Platinum处理器,运行主频为2.1 GHz。以下是MareNostrum 4节点与Grace-Hopper与Grace-Grace节点的简单结构比较:
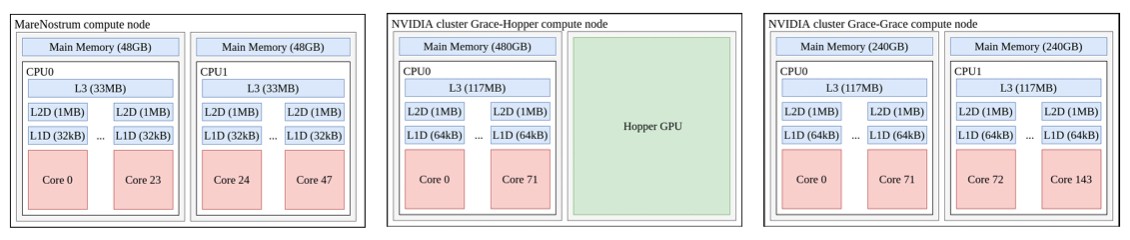
在Grace-Hopper节点上,巴塞罗那超级计算中心仅在超级芯片的CPU部分上测试了各类HPC应用程序。石溪分校团队则对比较了早期英伟达系统中的CPU-CPU与CPU-GPU组合。
以面来看巴塞罗那超级计算中心给出的汇总表格,其中比较了三套测试系统的各自架构:
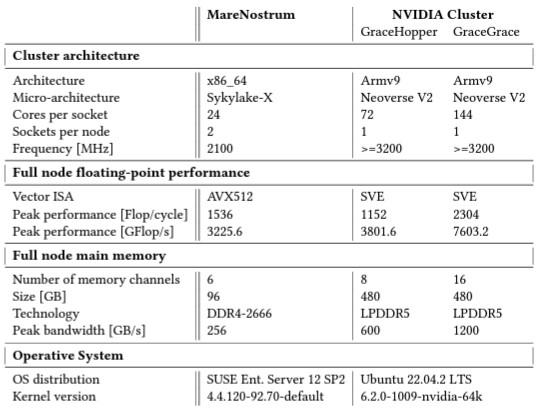
巴塞罗那超级计算中心称,Grace处理器早期版本中的CPU主频已下降至3.2 GHz,且内存带宽也低于英伟达当初公布的完整生产单元。虽然具体数字尚难以最终确定,但Grace CPU受测设备的实际运行主频约为3.2 GHz。
在应用程序运行性能上,巴塞罗那超级计算中心在三类节点上分别运行了自主开发的Alya计算力学与OpenFOAM计算流体力学代码、NEMO海洋气候模型、LAMMPS分子动力学模型以及PhysiCell多细胞模拟框架。以下是Grace-Grace节点与上代MareNostrum 4节点之间的性能比对。这里我们跳过了Grace-Hopper节点,因为其中并没有用到GPU,所以性能只相当于Grace-Grace节点的一半左右。下面来看相同数量CPU核心条件下的加速结果:
- 在Alya应用程序中,Grace-Grace的速度达到1.67倍至18.1倍。
- 在OpenFOAM上,Grace-Grace的加速效果约为4.49倍。
- 在NEMO上,加速比为2.78倍。
- 在LAMMPS上,当使用相同数量核心时(1到288个),加速比为2.1倍至2.9倍。
- 在PhysiCell上,同样使用48核心节点时的加速比为3.24倍。
很明显,Grace-Grace单元拥有3倍核心数量,因此节点层面的比较也应照此比例。
前文已经提到,石溪分校的论文还包含一系列基准测试,并整理了其他机构的性能结果。下表所示为运行HPC Challenge(HPCC)基准测试时各节点的相对性能,其中分别提取Matrix、LINPACK与FFT元素进行比较:
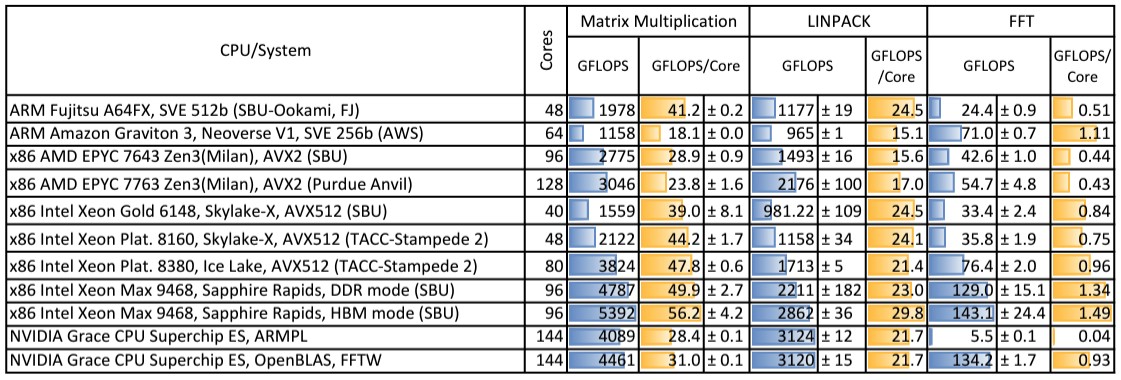
我们已经很长时间没看到这种带有误差范围的基准数据了,由于监控难度较大,多数测试并不提供误差参考。总而言之,以单一插槽为基础,Grace-Grace超级芯片的性能介于英特尔“Ice Lake”与“Skylake”至强SP之间,但高于“Milan”与“Rome”AMD EPyc处理器。
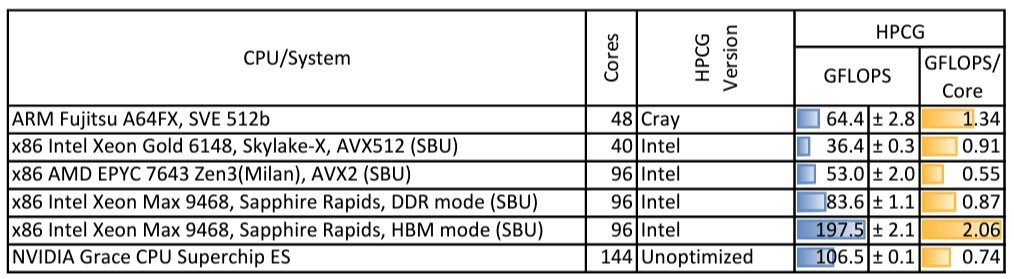
而在更严格的高性能共轭梯度(HPCG,主要强调计算与内存带宽之间的平衡,很多超级计算机在此测试中得分不高)测试中,Grace-Grace超级芯片带来了如下性能表现:
再来看Grace-Grace在OpenFOAM上的性能表现,测试使用MotoBikeQ在全部硬件上模拟1100万个细胞:
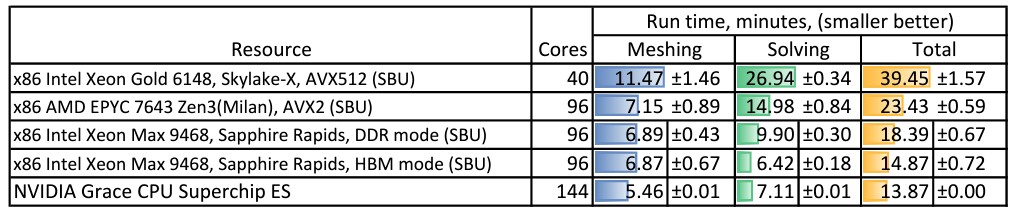
我们本以为Grace-Grace单元能在这项测试中表现更好,但很遗憾……
最后来看Gromacs分子动力学基准测试在各节点上的运行得分,包括CPU-GPU和纯CPU变体:
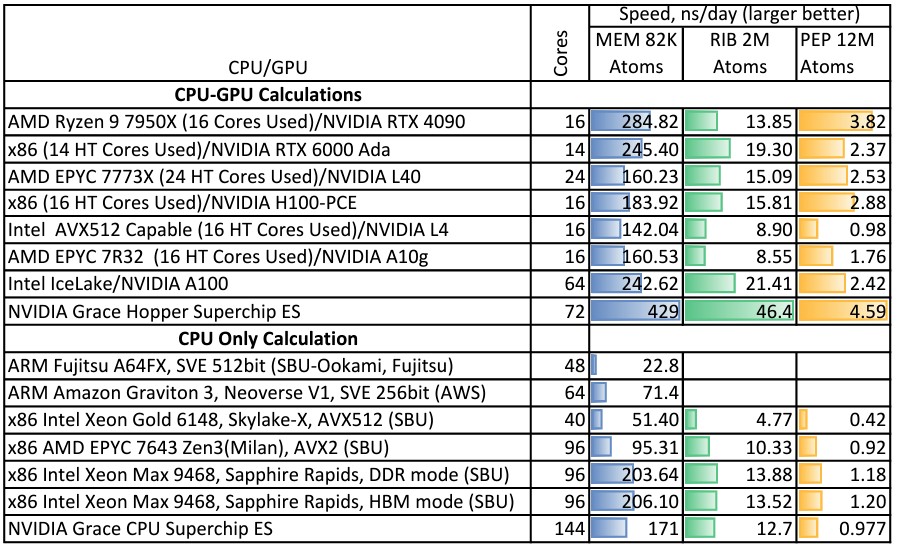
看来最终的优胜者已经出现了!Grace-Hopper组合明显表现更佳,但其他CPU配合Hopper GPU也能达到类似的效果。而在仅采用CPU的Grace-Grace单元上,Gromacs的性能则与双“Sapphire Rapids”至强Max系列CPU基本相当。值得注意的是,该芯片上的HBM内存似乎并没有给Gromacs负载带来什么性能提升。
总而言之,这就是我们目前掌握的Grace CPU在HPC工作负载上的实际表现与相关结论。石溪分校的论文中还列举了其他基准测试,欢迎感兴趣的朋友自行查看。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

康奈尔大学造出“会看图纸的AI设计师“:一张照片,自动还原可编辑的3D场景
康奈尔大学提出SEIG框架,让视觉语言模型通过分阶段重建几何、材质、构图和灯光,从单张图片自动生成可编辑的Blender 3D场景。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

AI会写3D建模代码了?谷歌DeepMind等机构推出首个专业评测平台,结果出人意料
谷歌DeepMind等机构推出3DCodeBench,评测12款顶级AI用代码生成3D模型的能力,揭示当前AI在几何推理上的核心短板与改进方向。
2024
02/09
07:57
分享
点赞

Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
Infineon Live Lab正式发布:全球首个实时云端实体硬件评估平台
Serve Robotics携手NoScrubs,自主配送机器人跨界拓展洗衣服务
Workr Robotics CEO:工业机器人自动化应按小时付费
专访CreateMe CEO:从缝纫到粘合,实体AI如何重塑服装制造
AI浪潮为集成商带来全新连接挑战
