
英特尔展示8核、528线程处理器,同时封装1TB/秒光学互连器件
在本周于加利福尼亚州举行的Hot Chips大会上,英特尔展示了一款搭载1 TB/秒硅光子互连器件的528线程处理器。该方案旨在最大程度提升分析类工作负载的处理能力,同时有效控制芯片功耗。
但请千万不要误会,这款芯片并非拥有超强并行能力的至强,甚至压根没有选择x86架构。
相反,它是专门为DARPA的分层身份验证漏洞(HIVE)项目所开发,采用的是自定义的RISC架构。美国军方的这项计划要求开发一种图形分析处理器,其流数据处理速度要比传统计算架构高出100倍,同时功耗还得有所降低。
图形分析技术的作用,就是处理复杂系统中的各数据点如何与其他数据点相连接。英特尔首席工程师Jason Howard在Hot Chips上的演示中列举了社交网络的例子,称可以通过图形分析工作负载来理解各成员之间的关系。
这个用例看似跟DARPA的需求八竿子打不着,但政府机构方面相信大规模图形分析能力在基础设施监控和网络安全方面同样有着重要意义。
该芯片是英特尔打造的首款网格到网格光子架构,此架构采用硅光子互连将多个芯片连接起来。但英特尔并没有选择使用铜线对双、四甚至是八插槽进行“缝合”,而是选择了共同封装的光学器件以实现数百、乃至数千芯片间的低延迟、高带宽网格连接。
当然,这一切目前仍处于原型设计阶段。
利用硅光子器件扩展图形分析能力
其目标是开发出可扩展技术,以支持各类超大规模图形分析工作负载。

中央计算芯片周围的四块小芯片,就是英特尔原型设计中的1 TB/秒光学带宽器件。
虽然这款芯片乍看之下仍遵循标准处理器设计,针脚齐备、甚至还有一个典型的BGA接口,但跟至强-D芯片上的接口不同,流入和流出芯片的大部分数据均采用光学传输。这里借助的,是英特尔与Ayar Labs合作开发的硅光子小芯片。
中央处理芯片周围的四块小芯片,负责将进出微处理器的电信号转换为由32根单模光纤承载的光信号。据我们了解,其中有16根光纤用于传输数据,另外16根用于接收数据。
根据英特尔的介绍,每根光纤都能在芯片内外以32 GB/秒的速率传输数据,由此提供总计1 TB/秒的带宽。但Howard也提到,团队在测试中发现实际速度只能达到理论数字的一半。
根据英特尔的设想,16块这样的芯片可以统一塞进一台开放计算项目(Open Compute Project)服务器当中,并以全对全的方式实现相互联网。此后,多台这样的服务器(最多可达10万台)又能再次以全对全方式继续联网。结果就是,任何一块芯片都能以极低的延迟与另一芯片进行通信,无论其具体处于哪台服务器内。
当然,芯片巨头在尝试引入光学器件时也遇到了不少挑战。Howard表示,除了传输带宽只能达到宣传数字的一半外,光纤还经常出现故障或损坏。
“每当我们把全部要素对齐到位并确保能正常工作,光纤都要闹出各种毛病。毕竟光纤都是脆性纤维,所以经常会突然脱落。我们还发现,在对整个封装进行回流焊接时,高温总会影响光纤器件的性能,最终导致器件良品率下降。”
Howard解释道,为了克服上述挑战,英特尔必须与合作伙伴共同开发出热故障率更低的新型材料。
为突破芯片瓶颈而生
之所以要设计这样一套新型系统,是因为英特尔的现有商用套件虽然也能加快图形分析工作负载的处理速度,但在扩展性方面却面临瓶颈。
Howard解释道,“至强处理器能够获取某一图形数据集并存储在缓存之内,之后快速浏览其中内容。”可一旦需要对这些数据集进行扩展,就会出现各种性能和效率瓶颈。
为此,该团队着手开发出一款针对图形分析做出优化的新型处理器,并很快发现了在芯片层面进行负载优化时的几种规律。
“我们立刻意识到这类工作负载是大规模并行的,甚至可以用极端并行来形容。因此,我们可以着力提升并行性以提高整体性能。”Howard还补充道,该团队还陆续发现了内存和缓存利用率等优化切入点。
“当我们把缓存线引入处理器时,往往只会使用到其中的8个字节,另外64个字节往往被最终丢弃、压根用不到。”Howard称这会产生一大堆无序管线,给系统带来不必要的压力。
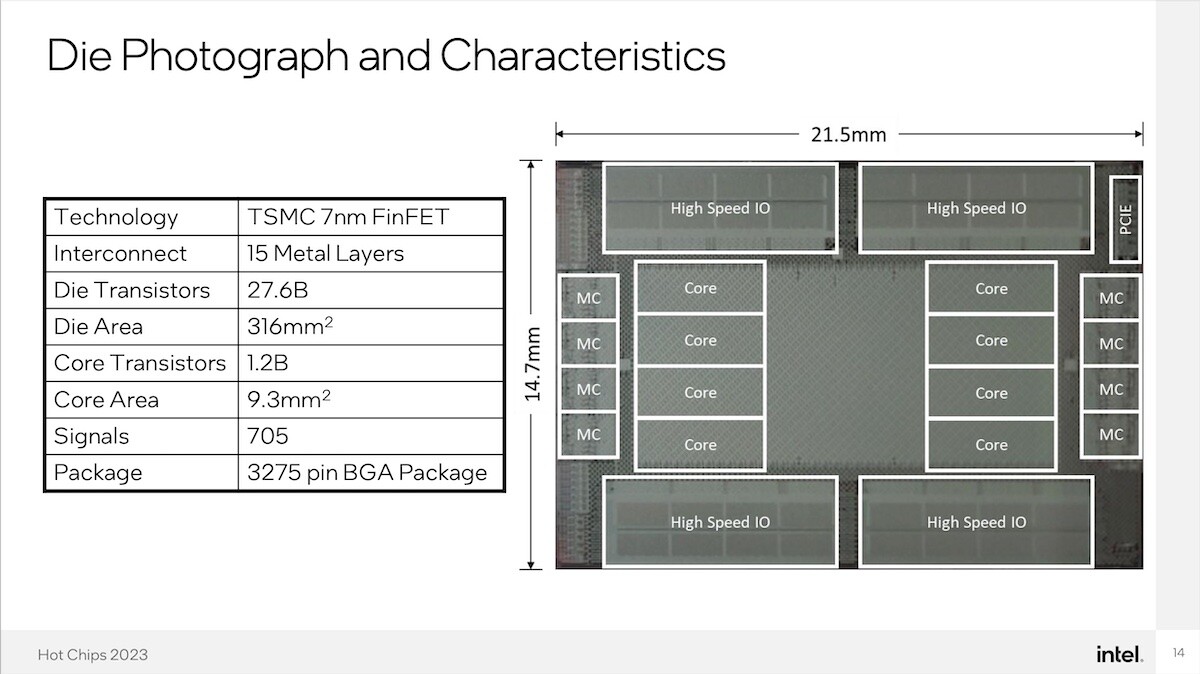
芯片中央的一块重要区域专门留给路由功能,用于控制从共同封装的光学器件处流入的数据流。
种种设计需求促使团队开发出了这款实验性处理器。此处理器由台积电的7纳米FinFET工艺制造(英特尔的大量非CPU产品多年来一直由台积电负责代工),拥有8核心、每核心66线程。
Howard解释道,这款芯片还采用了新颖的内存架构,这也是图形分析工作负载优化的重要方式。这些芯片搭载32 GB DDR5 4400MT/秒内存,其定制化内存控制器能够以8字节粒度进行访问。Howard称这种设计能保证“每当需要从内存中取出数据线时,都可尽量使用所有数据线,而不是将其中7/8白白丢弃。”
与主机系统的连接则采用8x PCIe 4.0通道。
英特尔还需要找到一种方法来处理出入计算芯片的巨大流量,理论上此流量可能高达1 TB/秒。根据Howard的介绍,正是为了满足这一需求,芯片上才预留了大量区域来封装路由器件。
对于这样一块线程和网络都相当密集的芯片,大家可能想当然认为它的发热量会非常惊人,但事实并非如此。这款芯片在1 GHz主频下的最高功率为75瓦。据英特尔介绍,16台服务器的整体配置总计可容纳8 TB内存、2048个核心、13.5168万个线程,而总功耗约为1.2千瓦。相比之下,拥有112个核心和224个线程的双插槽Sapphire Rapids系统自己就很容易达到这样的运转功率,所以原型设计的能效还算不错。
英特尔设想,这些芯片能够支撑起最高10万台服务器的网格计算体系当中,甚至为规模最大的图形分析工作负载提供近线性的性能扩展支持。但这一切目前都仅仅只是设想,毕竟英特尔迄今实际测试过的就只有此架构上的双芯片用例。
Howard解释道,这套设计方案能否商业化,还是要看客户们愿不愿意拿出真金白银来支持。“只要大家表现出积极的消费愿望,我们是非常乐意把它制造出来的。”
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
09/01
15:26
分享
点赞

NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
