
探索“绿色计算”前沿技术,清华AIR、英特尔联合发力
在建设“数字中国”的过程中,作为算力基础设施之一,数据中心起着重要的支撑作用。为了满足不断增长的算力需求,数据中心的数量逐渐增加,规模不断增长,能耗和碳排放也在攀升。如何建设绿色数据中心,助力中国达成在2030年前“碳达峰”,在2060年前“碳中和”的“双碳”目标,已成为行业普遍关注的焦点。
为了推动绿色计算的发展,英特尔正在和清华大学智能产业研究院(清华AIR)开展合作,结合清华AIR先进的AI算法研究,和英特尔在数据中心领域的深厚技术积累和广泛的生态系统伙伴,共同研发新的绿色数据中心解决方案。同时,双方也致力于和更多的合作伙伴共同探索数据中心的可持续发展,3月6日,在英特尔和清华AIR联合举办的“双碳”背景下的“绿色计算”暨数据中心能耗优化研讨会上,来自产业界和学术界的专家学者们就围绕这一热点话题进行了全面而深入的交流。

清华AIR院长张亚勤开场
在开场环节,清华AIR院长张亚勤介绍,“清华AIR的一个重要的研究方向就是解决我们行业产生的碳排放问题,包括通信的高能耗,如何用AI让计算、存储、传输工具变得越来越高效、越来越绿色,对产业、对我们整个社会,都是一个大的课题”。英特尔公司高级副总裁、英特尔中国区董事长王锐也在致辞中表示:“对英特尔而言,减碳是我们一个非常重要的使命。英特尔在积极推动学术界、研究机构的成果在产业界、在整个生态落地,让节能算法真正能有益于整个社会。”

英特尔公司高级副总裁、英特尔中国区董事长王锐致辞
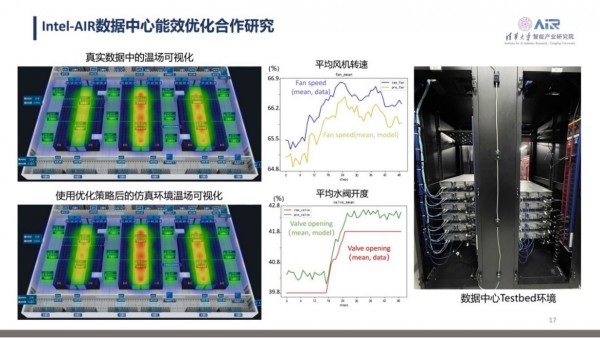
降低数据中心的能耗,原理上需要解决大量的决策优化问题,以离线强化学习为代表的新兴数据驱动决策优化方法,在解决真实复杂系统决策优化问题方面具有巨大的潜力。清华AIR助理研究员詹仙园在题为《面向真实场景的数据驱动决策优化》的报告中,分享了清华AIR在高性能、高泛化以及不完美奖励下的离线策略优化方面的最新算法研究成果,也介绍了离线强化学习方法在火力发电燃烧控制优化,以及与英特尔合作的数据中心能耗优化合作中的进展,最后基于“AI+IoT”技术在绿色计算方面的潜力进行了展望。
英特尔和清华AIR的数据中心能效优化合作研究,探索了如何把数据驱动决策优化的方法应用到高能耗数据中心联合优化中。因为系统本身非常复杂且数据量巨大,双方采用了一套分层离线强化学习框架去解决问题,在上层会着重考虑IT系统能耗方面的优化,在下层则去构建冷却系统跟上层的IT系统调度进行匹配,在满足负载要求的情况下,实现冷却系统本身的节能优化。研究结果显示,使用了新模型进行控制之后,数据中心温场的变化相对平稳很多。
英特尔中国绿色数据中心与可持续发展项目组经理彭振飞则介绍了英特尔中国可持续发展框架,在2022年,为减少数据中心服务器在使用过程中产生的碳排放,英特尔面向中国市场发布了“英特尔中国绿色数据中心技术框架1.0”,从XPU层、服务器层、机架基层和数据中心层,以及高能效与高功率密度、先进的散热技术及基础设施智能化等12种维度,帮助合作伙伴和客户让数据中心变得更加“绿色”。
液冷技术有助于帮助数据中心进一步降低PUE(电源使用效率),英特尔和21家上下游合作伙伴共同发布了《绿色数据中心创新实践——冷板液冷系统设计参考》,希望通过标准化降低整个生态的入门门槛,让解决方案加速落地,同时,英特尔还推出了DC-MHS服务器行业设计标准和开放通用服务器平台(OCSP)标准,可以简化设计降低成本,实现灵活配置。

此外,英特尔数据中心平台及架构事业部主任工程师周绍荣介绍了英特尔联合产业伙伴共同开发的冷板式液冷关键部件的四个标准,以及浸没式液冷OCP规范;清华大学能源经济研究所副教授张达则就数据中心纳入全国碳排放市场的交易机制发表了报告,研究了数据中心纳入全国碳市场后的碳排放配额分配方法、碳排放核算方法、数据质量控制与绿色电力交易等管理机制,并提出纳入全国碳市场的数据中心责任主体与规模边界建议;亚信科技CTO欧阳晔也围绕“算力内生网络”的话题进行了分享。

英特尔研究院副总裁、英特尔中国研究院院长宋继强发表总结
最后,英特尔研究院副总裁、英特尔中国研究院院长宋继强就本次“双碳”背景下的“绿色计算”暨数据中心能耗优化研讨会发表了总结。宋继强表示,绿色计算是一场马拉松,作为数字化转型中“基石”型的半导体企业,英特尔会保持与时俱进,致力于在节能减排上提供更多新方法,并继续聚集产业界和学术界多方面力量,与清华AIR等伙伴保持长期的通力合作,持续为“双碳”做出贡献。
来源:业界供稿
好文章,需要你的鼓励


Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
超过140家金融、支付及科技公司,包括Visa、Stripe和贝莱德,联合支持推出名为Open USD(OUSD)的新稳定币,直接挑战市场领导者Tether和Circle。OUSD由独立机构Open Standard LLC运营,主打零费用、无限额铸造与赎回,且储备收益大部分归合作伙伴所有,而非由发行方独占。Mastercard、美国运通、谷歌、Shopify、Coinbase等巨头均已加入。Circle股价在消息公布后下跌约13%。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Anthropic正式推出中端大语言模型Claude Sonnet 5,其编程能力在SWE-Bench Pro和Terminal-Bench 2.1两项基准测试中分别提升5.1%和13.4%。该模型具备更强自主性,能主动核查输出结果,并在抵御恶意请求和提示注入攻击方面表现更优。Sonnet 5将成为Claude免费版和Pro版的默认模型,定价为每百万输入token 3美元。此外,此前因美国出口管制而暂停推出的Mythos 5和Fable 5模型,管制已解除,将于近期恢复访问。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2023
03/10
09:04
分享
点赞

从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
