
具有完美内存带宽的计算野兽,会是个什么样子?

很多用例受内存带宽束缚久矣,相信不少朋友都被这方面问题引发的应用程序性能低下搞得头痛欲裂。解决之道也分为两条:用户端可以认真挑选芯片,保证在CPU核心与内存带宽的比例之间求取平衡;供应端则由芯片制造商和系统集成商提供针对性改进。
更有趣的是,我们不妨畅想如果CPU的内存带宽、甚至是内存容量如果不再受限,那么HPC和AI计算将会展现出怎样的新面貌。这话看似是在幻想,但其实质就是把内存资源的成本控制在远低于计算资源的水平。所以在等待芯片厂商和系统集成商拿出更好方案的同时,我们也不妨尽自己的力量做点尝试。
必须承认,用户端的调整只能算是“头痛医头、脚痛医脚”,但效果提升毕竟是实实在在的。如果买家能够在这方面下点心力,至少能让每个核心所分配到的内存带宽更加均衡。
几十年来,算力与内存带宽间的失衡一直在持续恶化。去年图灵奖获得者、行业大牛Jack Dongarra也在主题演讲中强调了这个问题。
行业发展也印证了这条路线的重要性。IBM早在2019年8月就预览了Power 10处理器,并表示预计将推出高带宽版Power 9(即Power 9「prime」版,但一直没有实际交付)系统。蓝色巨人在2019年10月的采访中,介绍了这套高内存带宽系统(由于始终没有正式推出,本文暂且称其为Power E955)。IBM表示系统将采用OpenCAPI内存接口(OMI)以及与Power 10共同发布的配套内存,下图所示为IBM当初计划为单Power芯片插槽配套的各项具体技术:
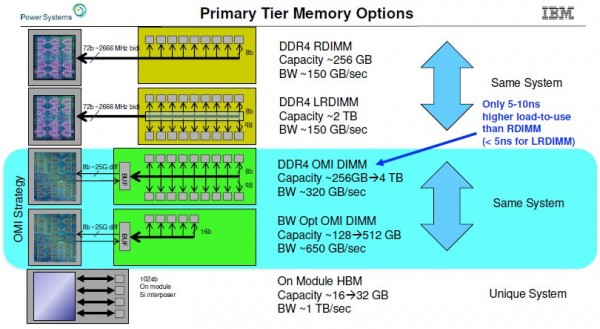
IBM的OMI差分DDR内存采用串行接口与SerDes,本质上等同于处理器上用于NUMA、NVLink和OpenCAPI端口所使用的“Bluelink”信号,而与普通的并行DDR4接口区别很大。无论是DDR4还是DDR5,这些DDR协议都位于内存条的缓冲芯片上;而从内存条到CPU的接口,则采用更通用的OMI协议。
这种早在2019年就在开发的OMI内存能够提供单插槽256 GB到4 TB的容量,以及每秒约320 GB的传输带宽。通过带宽优化版本,其能够将内存模块数量减少四分之一,提供每插槽128 GB到512 GB的DDR4容量,并在Power 9芯片上将内存带宽提升至每秒650 GB。当时IBM估计,随着2021年Power 10服务器的推出,时钟速率更快的DDR 5内存将把传输带宽进一步提高到每秒800 GB。
与此同时,对于计划在2020年交付的Power 9系统,IBM估计在使用HBM2堆栈内存的情况下,其容量将在16 GB到32 GB之间,每插槽的传输带宽大概在每秒1 TB左右。可以看到,每插槽的内存带宽非常恐怖,但内存容量却不是太大。
无论从哪个角度来看,这样的产品都不具备很强的竞争力。这可能跟蓝色巨人当时的晶圆代工合作伙伴Global Foundries遭遇技术和法律瓶颈有关。受此影响,构想中的带宽优化版Power 9系统(可能采用四插槽设计,每插槽采用双芯片模块)从未真正面世。
但“带宽野兽”的想法很有价值,并在2022年7月被归入Power E1050,成为Power 10中端系统中的一分子。
2020年8月,IBM公布了“Cirrus”Power 10处理器规格,并表示该芯片内每核心的峰值内存带宽为每秒256 GB,每核心持续内存带宽则为每秒120 GB。Power 10裸片包含16个核心,但为了保证新代工合作伙伴三星能在7纳米工艺上实现更好的良品率,其中最多只有15个核心被实际激活。在去年7月推出的入门级和中端Power 10设备上,SKU堆栈分别提供4、8、10和12核心,而15核版本仅在16插槽的高端“Denali”Power E1080系统中有所应用。目前还不清楚这些峰值与持续内存带宽数据是否适用于DDR5内存,但估计应该可以。IBM还推出了以DDR4内存为基础的OMI内存的Power E1050(及其他Power 10设备),并在演示中称如果升级至DDR5内存,则Power 10的内存传输性能将达到DDR2内存的2倍。
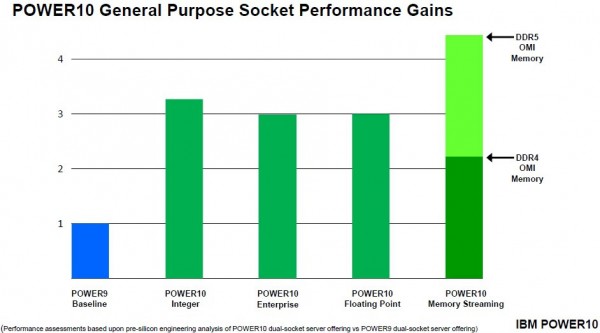
以上比较,针对的均为单芯片Power 10模块。在双芯片模块这边,数字直接加倍,再根据等同于单芯片模块的发热量进行时钟速率下调即可得到性能结果。
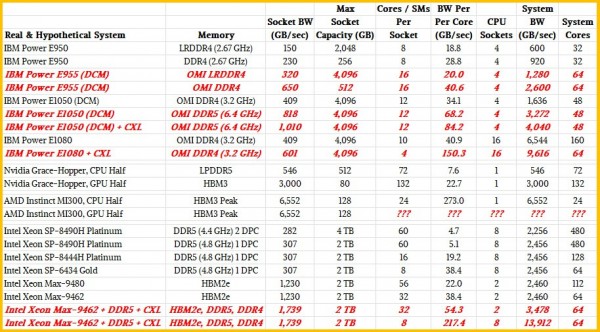
在Power E1050设备上,服务器最多可搭载四个Power 10 DCM,总核心数为96个。这八块小芯片共有八个OMI内存控制器,支持最高64个差分DIMM,DDR4内存运行频率为3.2 GHz,因此各核心间的总传输带宽为每秒1.6 TB。也就是说,当系统处于峰值传输带宽时,则96核Power 10中每信核心分配到的内存带宽为每秒17 GB。下面,我们将从两个方面做点调整和试验。
首先,我们尝试削减核心数量。Power E1050的胖配置采用12核Power 10芯片,但也有采用六核芯片的48核变体版本(没错,这种配置的Power 10核心收益率仅为37.5%)。在后一种情况下,每核心的带宽翻了一番,达到每秒34 GB。而如果我们选择使用运行频率达6.4 GHz的DDR5内存(这种内存价格昂贵,因此使用范围有限),则可让每核心获得高达每秒69 GB的内存带宽。
理论上,如果搭配使用CXL内存扩展器,那么Power E1050还能走得更远。我们可以使用CXL内存让每插槽上全部56条PCI-Express 5.0通道中的48条发挥作用,再加上六个独立传输带宽为每秒32 GB的x8 CXL内存扩展器,由此获得额外的每秒192 GB内存带宽(当然,延迟也会随之增加)。如此一来,总传输带宽将高达每秒1.8 TB,每核心分配到的带宽也将达到每秒38 GB。很明显,如果IBM在每个Power 10小芯片上减少核心数量,那么每核心所对应的内存带宽就将有所提升。在每芯片四核心、每系统总计32核心的情况下,每核心的内存带宽将高达每秒57.1 GB。而在转向DDR5内存再加上CXL扩展之后,每核心的传输带宽将增长至每秒84 GB。
再来看混合计算引擎
上述方案当然成本不菲,但对于某些工作负载,仍然要比把代码移植到GPU或即将推出的CPU-GPU混合计算引擎(包括AMD的Instinct MI300A、英伟达的Grace-Hopper,以及来自英特尔的Falcon Shores)靠谱一些。这是因为混合计算引擎虽然每核心内存带宽很高,但内存容量却非常有限。相比之下,IBM的Power 10和英特尔“Sapphire Rapids”Max系列CPU可以更灵活地采用HBM2e/DDR5混合内存。
先来看英伟达Grace芯片,其拥有72个核心和16个LPDDR5内存组,总容量为512 GB,单插槽内存带宽为每秒546 GB。这相当于单核心拥有每秒7.6 GB内存带宽。Hopper GPU拥有132个流式多处理器——类似于CPU上的一个核心,其HBM3堆栈内存的最大传输带宽为每秒3000 GB(在H100加速器上共有五个堆栈,可提供80 GB容量)。就是说,每个GPU核心分配到的传输带宽为每秒22.7 GB,这里我们暂时将其作为参考架构。如果将Grace上的所有LPDDR5内存都看作某种类CXL内存,则可以将CPU-GPU混合体的内存容量提升至592 GB,总内存带宽则可提升至每秒3536 GB。我们可以随心所欲调整核心和流式多处理器的传输带宽比例,比如将GPU当成各CPU核心的高成本快速内存加速器,这样就能让Grace的每个核心拥有每秒49.3 GB内存带宽,每个Hopper流式多处理器的内存带宽则为每秒26.9 GB。
前文提到的Power 10系统也大体在这个范围内,并不存在显著的工程差异。
至于AMD Instinct MI300A,我们知道它通过八条内存提供128 GB的HBM3堆栈容量,负责支持六个GPU和两个12核Epyc 9004 CPU小芯片。但我们不清楚其确切传输带宽,也不知道MI300A封装的六块GPU小芯片上的流式多处理器数量。但我们可以对总带宽做出有根据的推测:HBM3是以每引脚6.4 Gb/秒的速率提供最多16通道信号传输。根据堆栈中的DRAM芯片数量(四到十六个)及其具体容量(每堆栈4 GB到64 GB),即可计算出多种容量和带宽组合。如果使用16 Gb DRAM,则初始HBM3堆栈预计可提供每堆栈819 GB/秒的传输带宽。就目前看,AMD很可能采用八个16 Gb芯片堆栈,每堆栈最多八芯片,因此总内存容量为128 GB。再结合去年4月公布HBM3时披露的规格,则预计总传输带宽为6552 GB/秒。我们预计MI300A封装内的Epyc 9004裸片将包含16个核心,但出于良品率的考虑,其中只有12个实际可用。因此在搭载HBM3内存时,Epyc的每核心内存带宽将达到惊人的273 GB/秒。我们很难判断这六个GPU小芯片上包含多少个流式多处理器,但与之前的AMD与英伟达GPU加速器相比,每个流式多处理器的传输带宽可能非常高。不过老问题还在——虽然传输带宽非常富裕,但每计算引擎128 GB的总内存实在有些寒酸。
另外请大家先别激动。考虑到散热等原因,AMD可能没办法发挥DRAM堆栈及/或HBM3内存的全部速度优势,所以前面公布的预计带宽数字肯定要打个折扣。但即使每个CPU核心的带宽只有一半,也同样令人印象深刻。另外,对于纯CPU类应用场景,很难想象用户愿意选择GPU这种非常昂贵的附加组件。
再有,在处理器上挂载额外的CXL内存确实有助于提升容量,但无法进一步增加每核心或流式多处理器的传输带宽。
至于英特尔Falcon Shore CPU-GPU混合引擎,因为我们掌握的信息不足,所以无法进行任何预测和计算。
HBM加NUMA够不够救场?
聊到这里,有些朋友可能想到了配备HBM2e内存的英特尔Sapphire Rapids,它能同时支持HBM2e和DDR5内存的模式。没错,我们也很关注Sapphire Rapids,这一方面是因为它的某些版本支持HBM2e堆栈内存,同时也因为它的其他版本甚至支持八路NUMA扩展。
我们认为可以构建一套支持HBM的八路系统,配备DDR5与CXL主内存。下面,咱们就从最常规的Sapphire Rapids至强SP CPU说起。
据我们所知,Sapphire Rapids至强SP上的八条DDR5内存通道可以在插槽上提供略高于307 GB/秒的内存带宽。每个通道对应一个DIMM,运行频率为4.8 GHz,最大容量为2 TB。如果每通道对应两个DIMM,则每插槽的容量又能增加一倍,最高可达4 TB。但这时运行速率会较慢,因为频率只有4.4 GHz,相当于每插槽内存带宽为282 GB/秒(后一种明显属于内存容量型设计,而非内存带宽型设计)。在top-bin至强SP-8490H上,每通道对应一个DIMM,共有60个核心,运行频率为1.9 GHz,因此可以算出每核心的传输带宽仅为可怜的5.1 GB/秒。而如果使用至强SP-8444H处理器,由于其只有16个核心且运行频率为2.9 GHz,因此相当于放弃一些核心来换取传输资源,其每核心带宽为19.2 GB/秒。
如果想让插槽上各核心的内存带宽更进一步,则可以转向至强SP-6434。它只有八个核心,运行频率为3.7 GHz。在搭配4.8 GHz DDR5的情况下,其每核心传输带宽将增加一倍,达到38.4 GB/秒。这款处理器上的活动UltraPath互连(UPI)链路要少一条,所以双路服务器的耦合效率会稍低一些,延迟与带宽也都更低。总体来看,这跟使用3.2 GHz DDR4内存的六核Power 10芯片处于同一水平,也基本相当于Grace Arm服务器CPU配合本机LPDDR5内存的每核心性能表现。
现在,我们再来看看Sapphire Rapids的HBM变体。Top-bin Max系列CPU包含56个核心,四个HBM2e堆栈提供64 GB容量和1230 GB/秒的总传输带宽。这相当于每核心22 GB/秒内存带宽。Low-bin部分同样提供1230 GB/秒总带宽,但对应32个核心,相当于每核心38 GB/秒。如果在插槽上添加DDR5内存,则可再增加307 GB/秒;如果添加CXL内存扩展器,则可额外增加192 GB/秒。在满配情况下,32个核心的总内存带宽可达1729 GB/秒,相当于每核心54 GB/秒。
现在我们再考虑一点极端配置——利用NUMA互连将八个Sapphire Rapids HBM插槽接起来(请注意,英特尔并不允许这样设置),再把每插槽的4 GHz核心减少到八个。如此一来,我们就获得了总计64个4 GHz主频的核心,其性能要比Sapphire Rapids 60核至强SP-8490H更强大。在这样的配置下,再添加HBM、DDR5与CXL内存,就能将八插槽设备的总内存带宽提升至13912 GB/秒,相当于每核心拥有217.4 GB/秒带宽。
这样的配置当然不便宜,但话说回来,Power E1050也跟便宜二字沾不上边。
当然,如果IBM在Power E1080上减少核心数量并添加CXL扩展器,也能让这套16插槽系统更加强大。接入16个插槽的OMI内存将提供6544 GB/秒带宽,再加上由六个CXL内存模块在PCI-Express 5.0总线上贡献的另外3072 GB/tit 带宽,总计就是9616 GB/秒。在这套系统中,各位需要多少个核心?每个Power 10 SCM提供四个核心,总计64个核心,相当于每核心主内存带宽为150 GB/秒。
关键在于,这确实是一条让服务器节点上各个核心获得更高内存带宽的可行路线,使其更适合加速某些类型的HPC和分析类工作负载,甚至能在部分AI训练负载中大显身手。但随着内存容量或者内存带宽的提升,算力资源也在随之下降,所以在设计具体搭配时必须非常小心。算力过强而内存容量/带宽不足虽然不行,但内存容量/带宽冗余而算力有限同样无法发挥最佳性能。
顺带一提,我们也不太确定这种带宽野兽式的配置思路到底能不能加速AI训练——也许只适用于不断调优的预训练模型。我们有种预感,GPU核心与附带的HBM2e/HBM3堆栈内存带宽间也存在着均衡性关系,所以实际组合永远不可能达到理论意义上的峰值计算效率。
而且请务必意识到,以上提到的所有方案都不便宜。但好消息是,GPU加速设备的价格同样夸张。至少对于某些工作负载,更好地在计算、内存带宽和内存容量间寻求平衡点,可能要比把内存分成几块、把数据集分布在数十个CPU上效果更好。我们得承认,只有以针对性的方式推动负载加速、跨内存层次结构进行编程,才有机会真正突破性能极限。
这也是思想实验的意义所在。
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2023
01/26
16:07
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
