
英特尔:2030年前将实现一个芯片封装上集成1万亿个晶体管
英特尔的研究人员近日透露了一些技术创新和概念,包括改进封装让计算机芯片性能达到当前最先进芯片的10倍。
据英特尔称,这项最新研究将为2030年前实现芯片可容纳一万亿晶体管铺平道路,从而显着扩展摩尔定律。
计算机芯片行业长期以来一直遵循着摩尔定律,该定律最早是由英特尔联合创始人、前首席执行官Gordon E. Moore在1965年提出的。摩尔定律主要是被芯片制造商提及的,是指出微芯片上的晶体管数量随着芯片制造技术的进步,每两年翻一番。因此,我们可以预期新计算机的速度和功能每两年就会提高一次,同时成本也会更低。
几十年来摩尔定律一直被证明是正确的,但是最近几年有多家芯片制造商发出警告说,他们很难跟上摩尔定律的速度。今年早些时候,Nvidia公司首席执行官黄仁勋坚称现在摩尔定律已经失效。
但是,英特尔并不服输。近日在2022年IEEE国际电子设备大会上,英特尔提交了最新的研究报告,重点介绍了英特尔计划在2030年之前利用一系列工艺、材料和技术交付基于小芯片的万亿晶体管处理器。
英特尔之前曾做出过类似的承诺,并表示,跟上摩尔定律的步伐对于满足全球永无止境的计算需求来说是至关重要的。英特尔指出,数据的消耗和人工智能的进步,导致全球比以往任何时候都需要更多的计算能力。
英特尔新的晶体管和封装研究集中在几个不同领域,包括加速CPU的性能和效率,以及缩小传统单芯片处理器与小芯片设计之间的距离。
英特尔展示的其中一个概念可以大大减少小芯片之间的差距以提高性能,另一个概念则展示了晶体管即使在断电后也能保持状态。英特尔还研究了可以提高芯片整体性能的“可堆叠内存解决方案”。
英特尔的技术进步体现在多个领域。例如,英特尔最新的混合键合研究比去年提高了10倍。英特尔还提交了关于使用厚度小于三个原子的新材料设计,以及对可能影响数据存储和检索的界面缺陷的更深入分析。
这些新想法来自英特尔的组件研究和设计支持团队,该团队是英特尔内部最重要的研究机构之一,团队中工程师和设计师的任务是发明和开发新材料和方法,以支持半导体制造商把计算机芯片技术缩小到原子尺度的探索。
例如,组件研究团队开发了英特尔的极紫外光刻技术,该技术可以继续缩小节点尺寸,同时提高半导体的性能。
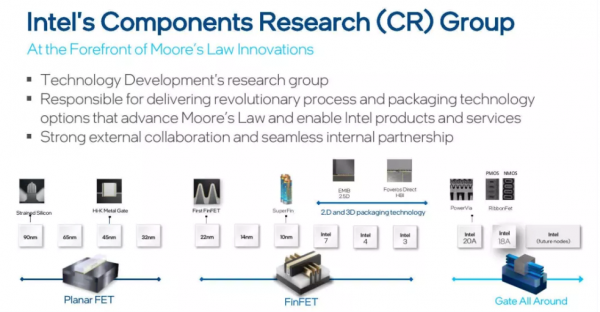
这个团队的研究工作通常要比商用技术领先5到10年,因此目前正在研究的技术和流程很可能帮助英特尔实现2030年的目标。
Constellation Research分析师Holger Mueller认为,如果英特尔能够兑现最新的这项承诺,那么关于晶体管和摩尔定律终结的说法似乎又一次被夸大了。“当然,这是一个雄心勃勃的目标,但如果英特尔能够成功的话,对所有企业来说都是个好消息。企业需要更高的计算能力来支持新的人工智能工作负载,并最终支持深度学习。如果英特尔取得成功,则意味着未来实现创新将面临更激烈的竞争和更高的成本效益。”
英特尔副总裁、组件研究集团总经理Gary Patton表示:“自晶体管发明75年以来,推动摩尔定律的创新不断地满足全球对计算呈指数级增长的需求。在IEDM 2022大会上,英特尔展示了突破当前和未来障碍所需的前瞻性和具体研究成果,以满足这个永无止境的需求,并在未来几年保持摩尔定律的活力。”
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2022
12/06
13:32
分享
点赞

NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
