
英伟达“GRACE”ARM CPU更多细节浮出水面

如今,游戏市场和加密货币挖矿行业的双重萎缩已经给英伟达沉重一击。不知道如果英伟达能够早点推出“Grace”Arm服务器CPU,是不是有机会规避当下的尴尬局面。
有时候,最微小的变化也会对CPU市场产生重大影响。
例如,最近人们总说AMD有多么幸运。他们当初果断抛弃了“本为同根生”的晶圆代工衍生公司Global Foundries,转而正确选择了台积电作为其唯一的Epyc服务器芯片制造商。
这种架构层面的正确选择,让AMD近年来大获成功,而继续信任Global Foundries的IBM却倒了大霉——由于前者无法按时将10纳米与7纳米制程工艺推向市场,蓝色巨人的Power 9和Power 10产品线可谓深受其害。去年,就在这家由AMD、IBM和Chartered Semiconductor代工厂共同组建的企业决定通过上市筹措资金的几个月前,IBM终于忍无可忍、决定对Global Foundries提起诉讼。
在AI浪潮席卷超大规模计算机、云服务商涌入企业数据中心之前,英伟达其实也对服务器CPU很有想法,一直想把自家的数据中心业务从边缘角色培养成体量最大、最具盈利能力的部门。
2011年1月,英伟达刚刚开始尝试用GPU加速HPC模拟和建模工作负载,而那时候的机器学习革命仍在纯学术环境下孕育。在这样的背景下,英伟达公布了Denver项目,也就是自己的Arm服务器CPU开发计划。三年之后,坊间传闻英伟达提出了自己的CPU指令集架构(ISA),并以此为基础尝试模拟Arm ISA和英伟达X86 ISA。之后,英伟达和英特尔就知识产权问题打了一场官司。虽然真实结果无人知晓,但如果传言可信,那英伟达永远不能在CPU上进行X86仿真。于是,显卡巨头的第一次服务器CPU试水就这么胎死腹中了。
直到几年之前,英伟达再次发现了垂直集成中的漏洞,即可以通过收购Mellanox Technology尝试开发Arm服务器CPU。虽然历史容不得假设,但如果英伟达在四年之前就推出了这款10纳米制程的CPU,再配合Grace芯片的内存一致性功能,选项登陆IBM的Power9处理器,而后通过NVLink让“Volta”GV100和“Ampere”GA100 GPU与之融合……那可能就真没AMD“Rome”Epyc 7002和英特尔“Ice Lake”至强SP处理器什么事了。
如果这是真的,那英伟达本来可以早早在CPU市场占据重要份额,对抗已显颓势的英特尔和尚未恢复元气的AMD。可惜这一切都只是假设,但老话说得好,“种一棵树最好的时机是十年前,其次是现在。”
结合这样的历史背景,我们再来看英伟达最近在Hot Chips 34大会上发布的Grace CPU消息。虽然内容不多,但好在英伟达杰出工程师兼Grace芯片架构负责人Jonathan Grace又做了补充演讲,也让我们对英伟达的Grace设计思路有了一定了解。
首先一点,跟我们之前的预期一样,Grace将采用基于2021年3月发布的Armv9规范的核心。

Grace核心还将支持向量数学单元,这些单元遵循Arm和富士通为HPC领域制定的SVE2第二代向量数学标准,而且已经充分兼顾到机器学习时代迫切需要的混合精度和矩阵运算。虽然官方没有具体说明这些向量的宽度,但我们预计Arm目前“Perseus”Neoverse N2核心中的双128位SVE2向量应该还不够。根据定义,我们知道Grace用的也不是Arm在“Zeus”V1核心中使用的双256位SVE向量,因为其并不属于SVE2向量。所以根据猜测,我们认为英伟达很可能会使用Arm接下来发布的“Poseidon”Neoverse N3和V2核心(这是我们按命名方式推断出的名称)来创建Grace核心及其向量。Grace的核心很可能采用双128位或双256位向量,但使用双512位向量的可能性不大,毕竟英特尔在至强SP设计中使用的双512位AVX-512向量就不太成功。根据今年3月的预估,Grace的运行主频应该在2 GHz到2.3 GHz之间,而且在使用双256位向量配合72个活动核心的情况下,应该能够达到每秒2.3到2.65万亿次的峰值算力。
英伟达也要求确保Grace能支持一切Arm服务器标准,具体包括:
- Arm服务器基础系统架构(SBSA)
- Arm服务器基础启动要求(SBBR)
- Arm内存分区与监控(MPAM)
- Arm性能监控单元(PMU)
如此一来,英伟达就能保证为其他Arm芯片编写的操作系统和应用软件,也能在Grace上顺畅运行。考虑到之前已经吃过大亏,英伟达应该不会再冒险讨论Grace处理器要不要支持X86 ISA了——除非英特尔那边口风有所松动,掌门人Pat Gelsinger愿意网开一面帮自己再增加点收入。但这事还真的说不好,也许Grace或者未来的英伟达Arm服务器芯片会以某种形式重现X86仿真模式,让咱们拭目以待。
英伟达反复强调,Grace将是一款72核处理器。但如果认真观察芯片照片,就会发现上面其实有84个核心,而且整个布局只要再加一排就能轻松扩展到96个核心。而且加上之后才更对称,所以我们猜测英伟达是给Grace预留了96核心的扩展空间。与此同时,考虑到Grace超级双芯片的设计需求加LPDDR5内存的运行功率必须保持在500瓦以下,所以英伟达也确实一时没法把空间用尽。很明显,要想在不影响主频、不突破功率上限的前提下实现96核心,英伟达需要台积电的3N制程工艺,也许2024年推出的Grace 2芯片就是这么个升级思路。
Grace芯片上那额外的12个核心(英伟达并没有提及)应该是为了提高良品率,当初英伟达的GPU就永远不会用尽所有流式多处理器。有时候,额外的核心或者流式多处理器永远都派不上用场,毕竟利用率不可能达到100%。如果要进一步增加核心数量,英伟达可能需要设计纵深更大的针脚排布。
Grace CPU将采用台积电的定制化4N工艺,跟即将推出(很可能会在今年9月的秋季GTC大会上)的“Hopper”GH100 GPU相同。4N工艺其实是经过改进的5纳米工艺,只是对晶体管体积和开关性能做出额外调整。
而且从Grace身上可以看到的是,它肯定是双芯片复合体的组成部分。单Grace只是暂时的,未来肯定会出现Grace-Grace或者Grace-Hopper的组合。Grace芯片上的NVLink四端口具有900 GB/秒的总传输带宽,该接口能够以每比特1.3皮焦耳的能源效率传输数据。据称,其能效将达到PCI-Express的5倍,并提供7倍于PCI-Express 5.0 x16链路的传输带宽。
在Grace和Hopper之间架起这么宽的数据通道,意味着CPU和GPU几乎可以直接使用对方的内存。所以从某种意义上讲,Hopper上的80 GB HBM3内存也可以作为CPU的高带宽内存,而Grace上的512 GB LPDDR5内存则GPU的胖辅助内存。双方内存之间将设有一个共享的虚拟地址空间,让GPU可以访问可分页内存,在设备间共享内存页表,同时也让CPU架构中的malloc和memap指针可以直接访问GPU内存。这不禁让我们好奇,对于想要让Hopper GPU获得更大内存的用户,英伟达会不会提供特殊的无核心Grace CPU作为内存扩展选项。
下面来看Grace芯片核心的可扩展网状连接架构(SCF):
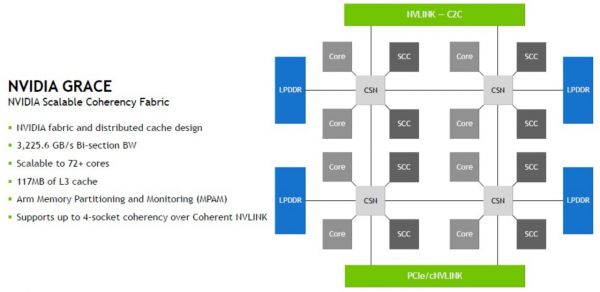
图中显然并未包含Grace芯片上的所有核心,只展示了各核心间的链接、主内存控制器、可扩展相干高速缓存(SCC)及其互连结构的性质。在即将上市的Grace版本中,这些SSC共配备177 MB的总L3缓存。
“CPU核心和SCF缓存分区,也被称为SCC,分布在整个网格当中。缓存交换节点(CSN)通过该结构写入数据,并充当核心、缓存和芯片其余部分之间的接口,由此实现Grace那令人难以置信的高带宽吞吐量。Grace-Hopper超级芯片还支持多插槽一致性,最多可以用四块芯片创建一个四超级芯片一致性节点。”
听起来很酷。虽然从拓扑结构上看,Grace SCF似乎跟Arm的片上网状或环状互连没啥关系,但英伟达却表示SCF确实基于Arm互连方案。
下面来看Grace单元框图:
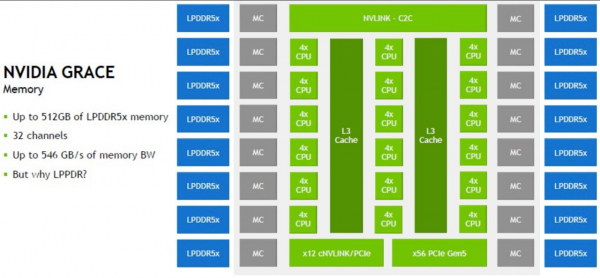
Grace芯片搭载16个内存控制器和16级低功耗LPDDR5主内存,跟大家在笔记本电脑和其他嵌入式设备中使用的一样。其中还有一个900 GB/秒的芯片到芯片(C2C)链接,以及形似两个PCI-Express 5.0控制器的元件。一条包含56路常规PCI-Express 5.0的通道,以及一条似乎同样使用PCI-Epxress协议的12路NVLink通道(上图中的cNVLink部分)。后者用于将Grace-Grace超级芯片接入Hopper GPU及其他设备。
至于为什么要用LPDDR5内存,英伟达用下表回答了这个问题:
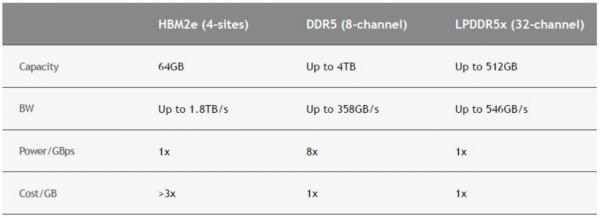
凭借32条内存通道与每通道单内存块,英伟达能够为512 GB主内存带来546 GB/秒的传输速率,而且继续保持容量虽大但却速度较慢的常规DDR5主内存的成本水平。英伟达明显打算用硬接线连通LPDDR5内存,这种粗暴消除内存或带宽扩容的作为可能会苦恼某些客户,但显卡巨头其实也有自己的苦衷。
英伟达举了个很有说服力的例子:假设我们想对包含1750亿个参数的自然语言处理模型GPT-3进行训练和推理。如果想要提高效率,则可以在8位、四倍精度的FP8浮点模式下执行数据处理。
要对内存中的模型执行推理,总共需要175 GB内存容量,这明显超出了Hopper的80 GB内存极限。但Grace 512 GB内存就能把它轻松吃下,而且在整个组合内存体系中,Grace还能贡献余下的417 GB容量。
而在训练方面,体量恐怖的GPT-3共需要2.5 TB内存。如果是在Hopper GPU上使用HBM3内存,那么至少需要32个GPU才能把GPT-3训练集装入内存。但如果选择Grace-Hopper超级芯片,那四个组合单元就能提供2.3 TB内存,使用五个单元的话还有不少余量。英伟达的图表证明,八个Grace-Hopper超级芯片才是最佳答案,余下的内存还可以执行管理任务并运行Linux操作系统。
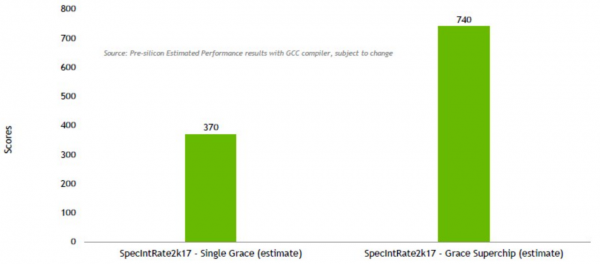
下面来看估算得出的GraceSPEC整数运算性能:
以下是使用部分STREAM基准测试得出的,单一Grace芯片上的内存带宽性能估计值。在Hopper到Grace内存性能方面,英伟达进行了一项自主测试,显示读取速度为429 GB./秒,写入速度为407 GB/秒,读写组合速度为506 GB/秒。很明显,我们可以看到英伟达在本地HBM3和CPU LPDDR5内存的混合读写操作中优化了连续内存性能,一举在CPU内存上获得了相当于92.7%的理论峰值带宽。虽然还比不上纯HBM3的3 TB/秒,但这毕竟是在大内存、快内存、可制造和成本可负担几个方面找到的平衡点,已经非常难得了。
顺带一提,以上数据均为模拟结果,并非早期芯片的实际测试成绩。目前还不清楚台积电什么时候能把芯片样品交付给英伟达。
好文章,需要你的鼓励


腾讯企业微信推出AI智能体“大员“,基于DeepSeek大模型构建
腾讯宣布将在其企业协作工具"企业微信"中推出AI助手"大元",该助手基于国内AI厂商DeepSeek的最新大语言模型构建。用户只需在企业微信中向左滑动即可唤醒大元,它能智能识别当前界面、理解用户需求并高效解决问题。凭借庞大的企业用户基础,腾讯在AI企业市场具备显著优势,此举也是腾讯持续加码AI布局、与国内外竞争对手争夺市场的重要举措。

华科大与阿里通义联手:让AI图像生成更“聪明“地分配算力,关键细节不再被噪声埋没
SharpMoE是华科大与阿里通义联合提出的扩散模型MoE后训练框架,通过引入干净潜变量指导路由,解决噪声导致的算力分配失准问题。

在美国制造、为美国制造:NVIDIA与合作伙伴携手共建
英伟达及其合作伙伴正大力投资美国制造业、供应链、能源电网与技术人才,以推动美国建设AI时代所需的核心基础设施。这一进程涵盖先进半导体、封装技术、电力系统、冷却设备及云计算容量等关键环节,旨在推动医疗、科学研究、工业生产及全球科技领域的持续发展。

调准“食谱“而非换“厨师“——Sakana AI证明,线性模型经过精心调校后能击败复杂的深度学习预测器
研究证明,对岭回归这样的简单线性模型进行精心的数据预处理调校(回看窗口、归一化方式、数据增强),即可在六个主流数据集上超越复杂的Transformer等深度学习预测模型。
2022
08/31
10:28
分享
点赞

Neo:印度科技大亨自掏3000万美元,打造微软Office的AI替代品
AI数据中心如何获得电网接入资格?公用事业公司的规划逻辑解析
Brookfield与Bloom能源将融资规模扩至250亿美元,押注AI数据中心独立供电
当CIO的技术提案遭到否决,该如何应对?
这款谷歌实验室 AI 应用如何成为我每日必用的工具
起亚EV5推出Storm特别版并新增全轮驱动选项
Meta效仿SpaceX,将过剩AI算力变现
Gemini Spark智能体登陆Mac,新增多项功能升级
Venice AI完成6500万美元A轮融资,估值达10亿美元
Anthropic Claude模型解除出口限制,全球发布重启
自动驾驶热潮卷土重来,Humble Robotics剑指货运领域
Deno 2.9发布:简化桌面应用开发,性能全面提升
