
英特尔携手德尚韵兴,为医疗创新注入智能动力
德尚韵兴医疗科技有限公司(德尚韵兴)正在应用英特尔®软件保护拓展(英特尔®SGX)和英特尔®oneAPI数学核心函数库(oneMKL),在边缘的医疗设备上保护其医疗人工智能算法和知识产权。作为中国人工智能超声技术研发的领导者,德尚韵兴采用其自主开发的深度学习框架DE-Light,在开源框架下该框架展现出了卓越的性能,将甲状腺结节检测的准确率提高了30-40%。
英特尔公司市场营销集团副总裁兼中国区行业解决方案部总经理梁雅莉表示,“基于医疗行业的特点,很多时候人工智能厂商不得不在客户端部署其解决方案,因此对厂商的核心智力资产——人工智能模型进行保护,已成为迫切需求。基于英特尔 SGX 技术的可信执行环境技术已成为性价比最高、能提供运行时保护的可行解决方案。在英特尔的支持下,德尚韵兴将 SGX 技术战略性地应用在包括其超声人工智能产品在内的一系列人工智能产品上,大大提升了其市场竞争力和创新能力。”
现阶段,超声波成像诊断和分析被广泛使用,是医疗诊断和治疗的重要组成部分。但影像检查和分析在很大程度上取决于医生的经验,且效率较低。
而人工智能在医学中的最大价值在于其能够快速分析大量数据并获得准确结果。通过使影像诊断智能化,诊断与分析中的AI技术正在帮助医疗机构加速检测和治疗。医生可以提高读片效率,降低误诊的可能性并获得诊断辅助,而患者则可以获得更准确的诊断建议和个性化的治疗建议。
德尚韵兴的AI医疗应用产品已成功在国内400多家医院中部署,并计划在未来一年中于1000多家医院中进行推广和部署。
德尚韵兴推出了用于超声成像的AI-SONIC™计算机辅助诊断系统,还开发了更多使用英特尔SGX来保护算法的人工智能产品。在超声AI模型解决方案中,为了确保英特尔SGX中的算法可以充分利用英特尔®处理器的计算能力,项目团队在利用英特尔® C++ 编译器的基础上,亦人工优化了在oneMKL上构建的算法浮点矩阵乘法的核心计算。
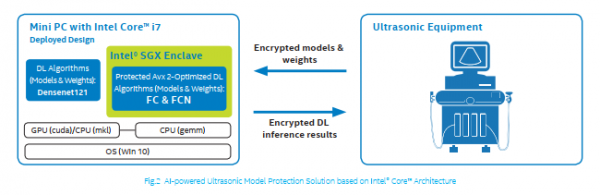
oneMKL是针对英特尔及其兼容处理器进行高度优化的并行数学函数库。在不同的操作环境中,oneMKL可以进行自动运行时处理器检测,从而对不同的处理器运行不同的优化版本的程序,从而保证其能在所运行的处理器上都能获得较好的性能。英特尔®oneAPI数学核心函数库(oneMKL)和英特尔®oneAPI深度神经网络库(oneDNN)为常用深度学习框架和众多自行开发的AI应用提供基础支持。
英特尔软件保护拓展是一个指令集,可提高应用程序代码和数据的安全性,更好地防止它们泄露或被修改。开发者可以将敏感信息划分到基于硬件的可信执行环境(TEE)或安全区域中,即内存中安全保护级别更高的区域。该技术有助于确保信任源仅限于中央处理单元硬件的一小部分,从而更好地保护代码和数据的机密性和完整性。
来源:业界供稿
好文章,需要你的鼓励


三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
今天讲的出海案例是三祥科技,这家汽车流体管路厂商拟由北美子公司出资1100万美元,购买美国俄亥俄州代顿工业厂房。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

斯巴鲁新款电动SUV销量已超越Solterra
斯巴鲁今年推出了两款全新电动SUV——Trailseeker和Uncharted,上市仅数月便已超越老款Solterra的销量。2026款Solterra也经历大幅升级,续航提升至288英里,新增14英寸触控屏及电池预热系统,寒冷天气下可在35分钟内从10%充至80%。Trailseeker起售价39,995美元,功率达375马力,可拖拽3,500磅;Uncharted起售价34,995美元,定位更紧凑运动。三款车型均基于斯巴鲁与丰田的合作平台开发。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2021
02/24
11:55
分享
点赞

三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
烛光映红土,科技启童心——中国电子学会科技志愿服务活动江西行
斯巴鲁新款电动SUV销量已超越Solterra
SpaceX疑似向投资者展示AI手持设备原型,马斯克否认
Meta计划对外出租AI基础设施,股价大涨近9%
Instagram算法定制功能升级,用户可更精准掌控内容偏好
AI时代Chiplet设计中不可或缺的可观测性层
从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
