
英特尔与宾夕法尼亚大学达成合作 采用具有隐私保护技术的AI识别脑肿瘤
英特尔和宾夕法尼亚大学佩雷尔曼医学院(宾夕法尼亚大学医学院)正在组建一个联盟,包含29家国际医疗和研究机构,使用一种叫做 “联邦学习”的隐私保护技术来训练可以识别脑肿瘤的人工智能模型。这项工作由美国国立卫生研究院(NIH)国家癌症研究所(NCI)的癌症研究信息技术(ITCR)项目资助,它将向宾夕法尼亚大学生物医学图像计算和分析中心(CBICA)的首席研究员Spyridon Bakas博士提供研究资金,为期三年总计120万美元。
“AI在脑肿瘤的早期检测方面大有可为,但要充分发挥全部潜力,将需要比任何一家医疗中心都要多的数据。借助英特尔软件和硬件以及一些英特尔顶尖人才的支持,我们正在与宾夕法尼亚大学和由29家协作的医疗中心组成的联盟展开合作,在保护敏感的患者数据的同时,促进脑肿瘤的识别。”——Jason Martin,英特尔研究院首席工程师
“机器学习训练需要大量和丰富多样的数据,这并不是某一单独的机构所能持有的,这点已被我们的科学界普遍认可。我们正在协调一个由29家相互协作的国际医疗和研究机构共同组成的联盟,该联盟能够使用包括“联邦学习”在内的隐私保护机器学习技术,将在此基础上训练最先进的AI医疗模型。今年,该联盟将开始开发识别脑肿瘤的算法,此算法的数据集来自于国际脑肿瘤分割(BraTS)挑战赛中大幅扩展的数据集版本。该联盟将允许医学研究人员访问比以往数量大很多的医疗数据,同时能够保护这些数据的安全。”——宾夕法尼亚大学Spyridon Bakas博士
这是如何做到的呢?宾夕法尼亚大学医学院与29家来自美国、加拿大、英国、德国、荷兰、瑞士和印度的医疗和研究机构,是使用“联邦学习”的技术来实现的。这种分布式机器学习方式,可以使得机构组织能够在不共享患者数据的情况下进行深度学习项目的协作。
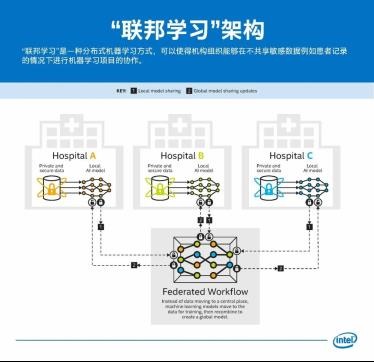
去年,宾夕法尼亚大学医学院和英特尔率先发表了有关医学影像领域“联邦学习”的论文,特别展示了“联邦学习”方法可以训练出一种模型,使其准确率达到传统无隐私保护训练准确率的99%以上。该论文最初在西班牙格拉纳达举行的2018年国际医学图像计算和计算机辅助干预会议(MICCAI)上发表。这项新工作将利用英特尔软件和硬件实现“联邦学习”,为模型和数据提供额外的隐私保护。
根据美国脑肿瘤协会(ABTA)的数据,今年将有近8万人被确诊患有脑肿瘤,其中儿童患者超过4600名。为了训练和建立一种检测脑肿瘤的模型,以帮助早期检测并获得更好的结果,研究人员需要获得大量相关的医学数据。然而,保持数据私密性并使数据受到保护至关重要,这正是采用英特尔技术的“联邦学习”的用武之地。通过这种方法,来自所有合作机构的研究人员将能够共同协作,构建和训练一种算法来检测脑肿瘤,同时保护敏感的医疗数据。
2020年,宾夕法尼亚大学医学院和29家国际医疗和研究机构将使用英特尔的“联邦学习”硬件和软件,在迄今为止最大的脑肿瘤数据集上进行训练来生成全新的具有最佳性能的AI模型, 而其中敏感的病患数据将单独保存在各个合作机构中。预计参与发起该联盟第一阶段工作的合作机构小组包括宾夕法尼亚大学医院、圣路易斯华盛顿大学、匹兹堡大学医疗中心、范德比尔特大学、皇后大学、慕尼黑技术大学、伯尔尼大学、伦敦国王学院和塔塔纪念医院等。
来源:业界供稿
好文章,需要你的鼓励


脑部植入物助瘫痪男子重获进食与饮水能力
一名因游泳事故导致胸部以下瘫痪的男子,通过脑植入芯片重新获得了自主进食和饮水的能力。研究人员为其安装了脑机接口,不仅帮助他重新活动手臂,还通过信号反馈重建了触觉感知。经过35周训练,其右臂力量提升86%,左臂提升62%。更令人惊喜的是,该技术似乎部分重塑了其神经系统,即使在系统关闭后,部分手部功能和感觉仍得以保留。

当AI变成“规则厨师“:奥地利与维也纳工业大学的研究团队如何让机器自动编写人类可读的“行事准则“
KR Labs与维也纳工业大学提出RuleChef框架,利用大型语言模型在学习阶段自动生成可读规则,推断时仅运行规则,兼顾透明性与高效性,在命名实体识别和意图分类任务上验证了有效性。

能源公司IPO融资创21世纪新高,押注AI基础设施热潮
受AI数据中心能源需求激增推动,能源企业IPO融资规模创本世纪新高。今年上半年,能源企业IPO融资达126亿美元,为1999年互联网泡沫顶峰以来最高水平,远超2025年全年的43亿美元。典型AI数据中心年均耗电约87.6万兆瓦时,美国电力需求预计在2026至2035年间增长39%。投资者正从芯片股逐步转向核能、地热等能源基础设施企业,看中其相对较低的市盈率(18倍,远低于科技股的40倍)。

腾讯混元推出“又快又强“的轻量级文字识别大模型HunyuanOCR-1.5
腾讯混元联合中科院与南开大学推出的HunyuanOCR-1.5,通过DFlash推测解码实现最高6.37倍推理加速,并用智能体数据构建框架显著增强古文字、低资源语言、多图问答等长尾OCR能力。
2020
05/22
11:08
分享
点赞

脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
Google AI模式新增应用集成功能,支持Instacart等多款常用应用
Beehiiv推出社区互动功能并上线AI写作助手
英国警方:两名黑客被捕重创知名黑客组织"散落蜘蛛"
谷歌将NotebookLM更名为Gemini Notebook,强化生态系统整合
NASA阿尔忒弥斯计划经验如何应用于AI基础设施规划
如何禁止AI聊天机器人收集你的数据用于模型训练
