
英特尔首批Optane DIMM开始向谷歌交货,但需待配套CPU到位后方可正式使用
发展路线图正式曝光,但其中尚存大量不明之处。
尽管具备相关支持能力的至强CPU还没有推出,但英特尔方面已经开始将首款Optane DIMM交付至买家谷歌手中。
英特尔公司数据中心部门总经理兼执行副总裁Navin Shenoy在本周三的以数据为中心创新峰会上,正式开始将这一全新产品线成果交付至谷歌平台副总裁Bart Sano手中。
尽管此次舞台效果设计得不错,但仍然没有什么现实意义——毕竟能够支持Optane DIMM的至强SP(Skylake)处理器目前尚未正式推出。
另外,对于这款产品,还存在大量细节信息缺失:
- 延迟及其对DRAM缓存的影响
- 功耗与散热情况
- 使用寿命
- 价格
- 安全性与可维护性
- 虚拟化与多租户支持能力
除非谷歌方面获得对应的定制化至强处理器,否则Optane DIMM在此期间将只能被束之高阁。
尽管如此,英特尔公司仍然在努力宣传Optane DIMM的性能优势。利用Optane DIMM配合早期Cascade Lake至强处理器,SAP HANA工作负载的重启时间可以由数十分钟缩短至几十秒。好吧,这样的结果确实振奋人心。但问题是,大家显然极少对HANA进行重启。
基本上,我们无法掌握关于Optane DIMM的任何应用程序性能提升信息,因为目前还没有哪种生产级处理器能够与之相匹配。
Anandtech网站发现了一份英特尔高性能计算路线图演示资料,其中展示了处理器与DIMM的未来发展方向:
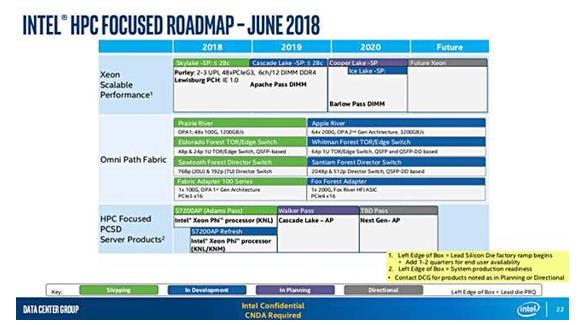
这份演示资料显示有Apache Pass DIMM——即英特尔Optane DIMM的代号——将于2019年发布,此外Cascade Lake至强处理器也将同步推出。
Cascade Lake是一款14纳米处理器CPU,采用至强Skylake的Purley微架构,其采用专注于人工智能的深度学习增强(简称DLBOOST)技术,能够提供11倍于至强Skylake的人工智能类负载性能提升。
该资料中还包括Cooper Lake CPU,其同样采用14纳米制程技术,将于2019年年底开始发货直至2020年。进入2020年,Ice Lake也将正式推出,其代表着英特尔长期承诺却一直未能实现的10纳米制程工艺。Barlow Pass DIMM也将在2020年与这款具有 里程碑意义的至强处理器共同亮相。
在资料下方,我们看到标有面向高性能计算的PCSD服务器产品部分,其中包含2019/2020年的Walker Pass DIMM,以及另一款将于2020/2021年推出的未命名DIMM。Walker Pass的推出时间与另一款Cascade Lake进阶处理器相同。
Anandtech网站猜测,Barlow Pass正是下一代3D XPoint DIMM。但我们还无从得知其在性能与规格方面同现有Apache Pass XPoint DIMM有何区别。
而The Next Platform网站则表示,Walker Pass将是“第二代Optane DIMM,且预计上市时间定于2019年5月左右。”
从演示资料中的时间顺序来看,Barlow Pass可能实际上代表着第三代Optane DIMM。
评论观点
我们认为英特尔公司不会允许AMD处理器轻松支持Optane DIMM。然而,目前美光已经在XPoint的开发工作上与英特尔分道扬镳。如果美光进行相关技术方案的批量生产(这简直是一定的),则预示着AMD方面很可能将通过美光Quantx DIMM支持XPoint DIMM。
很明显,Optane DIMM的正式使用必须等待英特尔Cascade Lake至强处理器的正式出炉。即使英特尔能够在今年年底之前发布第一款Cascade Lakes产品,其它受支持的衍生方案也需要再等一等,这意味着各服务器OEM厂商直到2019年才会全面发布自家相关产品。
考虑到产品细节信息的缺失——特别是在读取/写入延迟、功耗与使用寿命等方面,我们基本确信以下几项结论:1)其当前指标并不出色;2)英特尔仍在调整其Optane DIMM以进一步降低延迟与功耗并提升使用寿命。
与现有Apache Pass产品相比,Barlow Pass、Walker Pass以及另一款尚未命名的DIMM很可能拥有更高的层数与存储容量。
与以往一样,英特尔公司的Optane产品开发进度仍然令人沮丧,而其技术发展路线图资料也证明这一切恐怕要到2020年之后才会开花结果。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2018
08/13
10:14
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
