
英特尔首届AI开发者大会:秀出AI芯片和AI能力
英特尔今日在美国旧金山举行了首届Artificial Intelligence (AI) Developers Conference人工智能开发者大会,向800名AI极客和媒体等观众展现了自己在该领域的领导力、技术和赢得的客户。现在英特尔拥有丰富的人工智能技术产品组合,特别是在收购了Movidius和MobileEye获得实时处理能力,收购Altera获得可重新编程的FPGA加速硬件,以及收购Nervana可训练由NVIDIA GPU提供动力的工作服在。英特尔专注于训练在生产环境中使用训练过的神经网络的推理处理,这是一个很好的策略,因为推理处理可能会成为未来几年训练细分领域中一个规模越来越大的市场。虽然英特尔尚未在其产品组合中使用强大的ASIC来构建人工智能网络,但它可以在推理方面创造出相当强大的市场地位,和苹果、高通、Xilinx和NVIDIA等公司匹敌。
也就是说,英特尔并没有放弃AI训练这个市场——NVIDIA在这个市场中取得了巨大的成功,年运营率达到了30亿美元。在这次大会上,英特尔强调了至强处理器在训练方面的优势,同时指出未来希望利用Nervana更直接地与NVIDIA芯片竞争。不幸的是,对于英特尔来说,Nervana现在似乎至少需要18个月的时间——这是我的预测,需要更大规模重新设计的时间。
英特尔人工智能高级副总裁Naveen Rao在主题演讲中阐述了英特尔的人工智能战略:从根本上说,英特尔要为优化开发软件统一化的套件提供全面的人工智能通用设备和专用设备。正如Rao所指出,运行人工智能应用并不是一个适合所有人的市场,而且英特尔的产品提供了进行推理处理所需的性能、延迟和功率。

图1:英特尔高级副总裁Naveen Rao拉开了这次面向人工智能应用开发者的大会的帷幕,英特尔最大的一些客户在他的主题演讲中露面。
英特尔还通过这次大会分享了一些关于客户在英特尔面向人工智能硬件方面所取得的进展,包括Google、亚马逊、微软、Novartis和Facebook。Novartis是一个很好的例子,在这个例子中如果不在HBM和CPU控制的DDR4内存之间来回切换,GPU内存可能不足以处理大型数据集。这也突显了英特尔一直在抱怨的基准测试问题。具体来说,如果你(像Novartis一样)正在处理分辨率为1024x1280x3的位图像,那么芯片在训练ImageNet数据库(图像仅为224x224x3位)时的性能就是无关紧要的。Novartis最近还使用OmniPath将其人工智能训练扩展到8个节点,将训练时间从11小时减少到仅31分钟。英特尔指出,Skylake至强处理器具有特定的指令(例如降低精度的数学运算),从而有助于提高至强处理器面向人工智能任务的性能。
Facebook分享了一些有趣的数据,表明Facebook使用(至强)CPU进行所有推理工作并选择训练任务,而使用GPU用于训练Convolutional Neural Networks (CNNs)针对图像处理,以及Recurrent Neural Networks (RNN)用于语音和语言翻译。英特尔需要Nervana用于像这样的工作负载。从图2中可以看出,Facebook一部分使用了CPU是因为自己已经有数百万了CPU了。
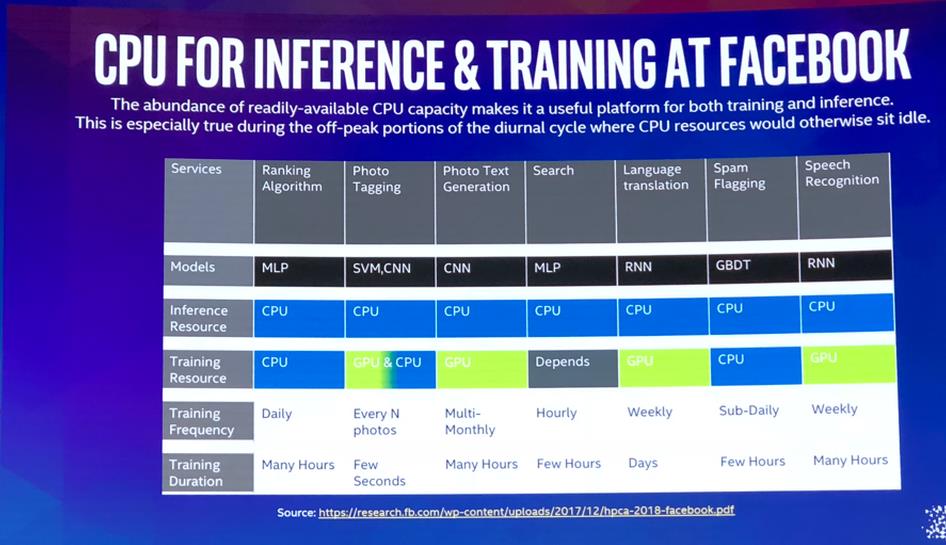
图2:Facebook发表了一篇博客,第一次展示了在哪些方面使用CPU,以及如何使用GPU(绿色)进行广泛的人工智能处理。
英特尔指出,大多数企业的CPU容量是过剩的,特别是在夜间。英特尔缓解了针对很多机器学习工作服在使用现有资源所带来的软件负担。正如Rao所说,企业现在可以在他们现有的芯片上运行人工智能。
在笔者看来,这次活动最大的新闻是备受期待的Nervana神经网络处理器(NNP)路线图更新了。在被英特尔收购之前,Nervana曾预计将交付一款可支持框架的NNP加速器,该加速器可能会以10倍的速度击败某些GPU。英特尔一直在向主要的一些人工智能客户提供第一代芯片样品,并将这些客户的反馈和增强需求融入到第一代NNP中,预计2019年年底推出。我曾预测Nervana会在去年发布首款商用产品,但是现在看起来似乎还需要时间打磨这款产品。在图3和图4中,英特尔透露的一些信息,让我们可以用来对NNP进行一些预测。

图3:英特尔留下一些信息,让我们可以用来预测NNP L-1000 AI加速器的最终性能
在图3中,英特尔提到了“Chip X”,笔者认为这可能是NVIDIA Volta GPU,大幅度地夸大了其性能。英特尔在这里可能是想表达一些观点,但笔者要指出的是,125 TOPS这个数据仅与NVIDIA TensorCore指令执行的4x4矩阵操作有关。没有TensorCores,Volta V100可能会是在30-40 TOPS范围内。这与英特尔声称Lake Crest芯片的吞吐量大致相当,因此英特尔决定推迟第二代商用产品的原因就显而易见了。请注意图3最右侧的说明,该图表明最初的Nervana结构在<800 ns的延迟时间下提供了2.4TB的带宽。这个说法令人印象深刻,而且非常重要,因为低延迟网络对于训练大型神经网络中的横向扩展并行处理来说至关重要。
图4显示了英特尔希望Spring Crest产品的落点在哪,它将目前的NNP的性能提高了3倍,使其与NVIDIA Volta GPU具有相当的竞争力。如果NVIDIA的下一代芯片不能提供更通用的TensorCore功能,我会感到非常意外,但此时NVIDIA尚未提供任何关于下一代芯片的信息。

图4:英特尔预测Spring Crest芯片相比Lake Crest的性能提高3-4倍。
结论
英特尔知道抓住人工智能机遇的战略重要性,并将专注于数据中心和边缘的推理处理上。为了训练大型模型以及对网络要求苛刻的大容量内存,英特尔力推至强处理器,当然这是因为英特尔主要产品就是至强。英特尔已经决定等到2019年年底推出第二款Nervana芯片,试图追上甚至赶超NVIDIA。重要的是,英特尔将在人工智能生态系统投资10亿多美元,并为全球100多所大学的研究和教育项目提供资金。英特尔已经为至强处理器增加了统一的软件和人工智能功能,同时利用FPGA、MobileEye和Movidius以满足应用特定的需求。因此,英特尔拥有相当强大的人工智能组合,除了大型设备训练之外。
这是令人印象深刻的进步,笔者也将密切关注接下来接下来英特尔如何赢得更多客户和成功案例。和除了Facebook或微软之外的所有人一样,我只需等待第二款Nervana芯片面市即可判断英特尔能否成功与NVIDIA和其他很多正在为训练人工智能网络准备芯片的初创公司相竞争。
来源:至顶网服务器频道
好文章,需要你的鼓励


AI对就业的影响:大规模裁员背后的真相与数据
近期数据显示,2026年5月前企业已宣布约9万个与AI相关的裁员岗位,部分预测称未来五年美国15%的工作将被AI取代。然而,Ramp与Revelio Labs追踪近2.2万家企业的最新报告显示:重度投入AI的企业反而实现了更快的人员增长,包括初级岗位在内的各职能人数均有上升。但这一数据主要来自技术型企业,能否普遍适用仍存疑。报告同时指出,资源匮乏的企业可能在AI浪潮中持续落后。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

AI重复申请问题推动电网转向“承诺优先“规划
AI数据中心开发商向多家电力公司同时提交大负荷接入申请以确定选址,导致区域需求预测虚高、电网投资失衡。美国联邦能源监管委员会(FERC)及ERCOT、PJM、SPP等机构正推动"承诺优先"规划机制,要求项目具备实质性商业承诺方可纳入长期传输规划。谷歌、亚马逊、微软、OpenAI等科技巨头支持建立标准化的项目成熟度评估体系,但各方在具体机制上仍存分歧。发电建设问题尚未被纳入联邦传输改革议程。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2018
06/04
15:46
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
