
HPE退出云服务器市场 两周前曾说不会退 原创
至顶网服务器频道 10月20日 新闻消息(文/Simon Sharwood with Chris Mellor):HPE宣布不再继续为大型云运营商提供定制服务器的业务。
读过笔者10月5日文章的读者可能会感到惊讶。其时HPE的Carlo Giorgi告诉记者,云服务器业务“……正在重新被打造及被打造成更适合目标用户的业务。云服务器业务仍将为服务提供商提供定制产品,但不会只具有标准的SKU,而且产品结构将取决于计算类型的需要。”
但现在HPE却发布了HPE总裁Antonio Neri本周提交的给金融分析师的幻灯片。他的第三张幻灯片判了服务器的死刑,见下图。
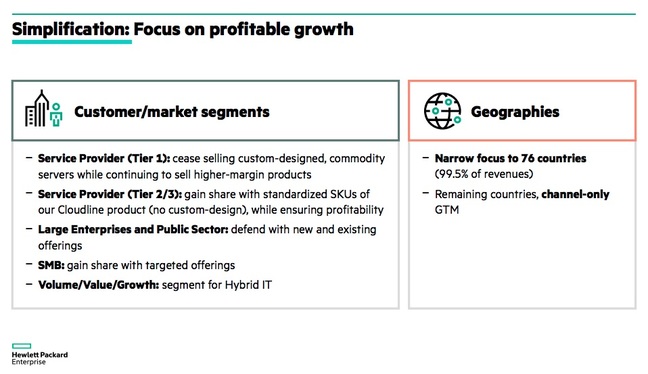 HPE总裁Antonio Neri判服务器死刑的幻灯片
HPE总裁Antonio Neri判服务器死刑的幻灯片
至于HPE为大型云提供的“高利润产品”是什么则没有明说。但如果说是完全新的东西的话,笔者会感到吃惊,因为Neri幻灯片里的第五张概述了HPE公司产品、地点和语言的大幅度整固。这可能也解释了为什么坊间会有HPE计划砍掉5000个工作岗位的 流言。
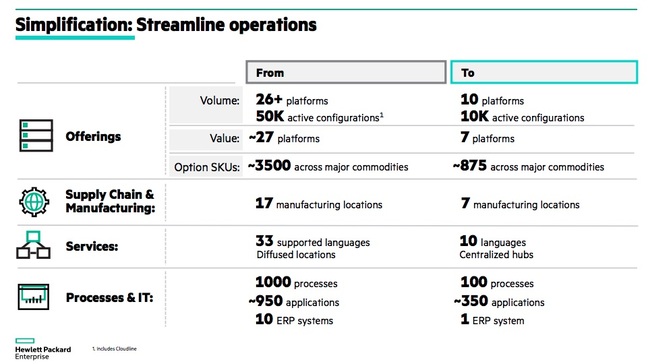 HPE的精简计划
HPE的精简计划
整套幻灯片在HPE公司未来的发展方向上给出了一些提示,幻灯片提到的计划包括:名为“Project New Stack”的项目,旨在提供“跨云混合即服务平台应用、数据及基础架构组合”;扩展Aruba平台,在云管理网络领域挑战思科的Meraki;作为Aruba解决方案的一部分开发SD-WAN功能,为客户提供单一控制点的Wi-Fi、交换和广域网;扩展Aruba OS下一代校园聚合交换的可编程性。
笔者曾要求HPE澄清其服务器计划,如果HPE这样做的话,笔者会更新此文或发一篇新的文章。
来源:The Register
好文章,需要你的鼓励


Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
超过140家金融、支付及科技公司,包括Visa、Stripe和贝莱德,联合支持推出名为Open USD(OUSD)的新稳定币,直接挑战市场领导者Tether和Circle。OUSD由独立机构Open Standard LLC运营,主打零费用、无限额铸造与赎回,且储备收益大部分归合作伙伴所有,而非由发行方独占。Mastercard、美国运通、谷歌、Shopify、Coinbase等巨头均已加入。Circle股价在消息公布后下跌约13%。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Anthropic正式推出中端大语言模型Claude Sonnet 5,其编程能力在SWE-Bench Pro和Terminal-Bench 2.1两项基准测试中分别提升5.1%和13.4%。该模型具备更强自主性,能主动核查输出结果,并在抵御恶意请求和提示注入攻击方面表现更优。Sonnet 5将成为Claude免费版和Pro版的默认模型,定价为每百万输入token 3美元。此外,此前因美国出口管制而暂停推出的Mythos 5和Fable 5模型,管制已解除,将于近期恢复访问。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
10/20
18:01
分享
点赞

Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
北美电网夏季压力暂缓,但容量危机隐患未除
为270万人守护饮水安全:莫卡辛水电站发电机组更新改造全记录
加州最大光储项目Eland:清洁能源未来的范本
AI音乐视频生成:2026年十款自动化创作工具盘点
欧洲AI安全与网络滥用桌面推演的核心洞察
Rivian R2激光雷达实车曝光,外观设计优于同类车型
HPE Alletra Storage MP X10000发布,AI智能体存储出现了
HPE Zerto Software 为企业数智化保驾护航
算启当下 即见未来
HPE ProLiant Gen12正式发布,打造极致可靠、能效优化、智能自驱的新一代计算平台
HPE Gen12:英特尔至强6加持,数据中心和边缘计算的“新宠”
据报道,慧与同埃隆.马斯克的X公司签署价值10亿美元的人工智能服务器大单
HPE谈2025年合作伙伴激励包:Alletra MP、Private Cloud AI、VM Essentials均属于最高倍薪酬类别
HPE CEO谈超算优势、VM Essentials市场机会和财报业绩
HPE计划在2025年全面升级超级计算机阵容
HPE发布用于AI和高性能计算的新超级计算机平台和服务器
