
【视频直播】关于浪潮M5,你想知道的,都在这里…… 原创
看惯了盛大的线下发布会?这次我们再玩点儿不一样的,8月2日14:00,浪潮将在线上举办M5上市研讨会,会议全程视频直播最强产品经理阵容将悉数亮相!
看惯了盛大的线下发布会?
这次我们再玩点儿不一样的
8月2日14:00

浪潮将在线上举办M5上市研讨会
会议全程视频直播
最强产品经理阵容将悉数亮相
(产品经理里各种美女帅哥这种事,我能不说?)
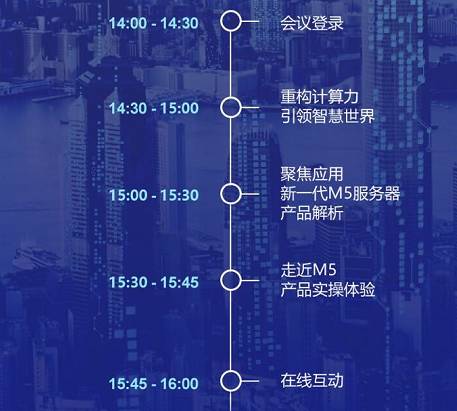
多款明星产品深度解剖
近距离实操体验
面对面答疑解惑
……
关于M5的一切
或许你都能在此找到答案
据内部靠谱消息
参与互动貌似还有礼品拿耶
废话不多说
速速戳http://app.uao.so/projects/inspur/index.html?from=singlemessage&isappinstalled=0
报名参与!
来源:至顶网服务器频道
好文章,需要你的鼓励



2026-07-20
南京理工大学、浙江大学、新加坡国立大学联合研究:给机器人装上“双重记忆“,让它真正记住自己在干什么
LaMem-VLA是南京理工大学等三所高校提出的双重记忆机器人框架,通过将短期视觉记忆和长期语义记忆融入模型推理过程,显著提升机器人执行长程任务的成功率。


京东氧气AI商品中台:用千亿规模的AI大脑,让每一件商品都被精准理解
京东氧气AI商品中台(Oxygen AIIC)通过大语言模型与视觉语言模型,构建了覆盖千亿级商品知识资产的全链路生产与服务系统,将商品信息丰富度提升至3.35倍。
2017
08/01
18:10
分享
点赞

最新文章
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
相关文章

邮件订阅
白皮书