
浪潮完成500万平方公里1Km分辨率高精度数值天气预报
ZD至顶网服务器频道 04月12日 新闻消息:近日,浪潮与某气象客户紧密合作,完成了区域覆盖面积超500万平方公里、水平分辨率达1Km*1Km的高精度数值天气预报,为气象业务提供了更加精准的天气预报产品,达到了国内领先国际先进的水平。这项工作是在浪潮为该客户建设的天梭超级计算机上完成的,该超算拥有8640个处理器核心,是目前国内数值天气预报业务领域部署的基于x86技术的性能最高的超级计算机,将更好地服务于经济生产、人民生活和防灾减灾等。
浪潮完成500万平方公里1Km分辨率高精度数值天气预报
天气预报:更高精度、更大规模
该客户之前采用的气象业务化集合预报系统,该系统包含11个预报成员,每天完成2次集合预报(0点和12点),预报范围为当地及周边省市,覆盖全国20%~25%的区域,水平分辨率为3km。该预报系统包含前处理、同化、预报、后处理模块,预报4天的天气过程。每个预报成员分配一定数量计算节点进行运算,总耗时在2小时左右。
浪潮气象领域高性能计算专家在该预报系统的之前预报范围基础上增加了一层嵌套区域,将水平分辨率提高到1km,并可预报4天的天气过程。这一改动将增加运算的复杂度,而且计算规模也随之大增。经过浪潮专家的深入并行优化,使用浪潮超级计算机可将运算耗时可以控制在2小时30分钟,不仅能够给出更高精确度的预报结果,而且还能满足预报的时效性。
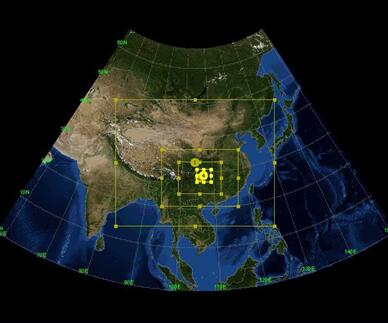
针对该系统中的高分辨率大规模短期预报(12小时),浪潮超级计算机完成了水平位网格数为2400*2100的1km高精度数值模拟,这一精度的覆盖范围达到504万平方公里,超过中国一半以上的国土面积。在这一超大规模预报模式下,浪潮专家成功将并行规模扩展到8192处理器核心上,并达到近乎线性的加速效率,运行时间耗时大约2.4小时。
超级计算:更低功耗、更强性能
之所以能够支撑更高精度、更大规模的气象数值预报,除了在算法方面的改进和优化外,也得益于浪潮超算系统的优秀设计,并实现了更低功耗、更强性能。
浪潮为客户构建的超级计算机采取刀片+胖节点+高速IB网络的解决方案,峰值计算性能达数百万亿次。同时水冷方案设计相比传统风冷系统节能20%以上,使PUE值大幅降低,实现了绿色超算,做到了高性能与低能耗的融合。
高密度、高性能刀片节点:在高性能计算中,为了节省空间、降低能耗、简化管理,采用刀片服务器已是大势所趋。浪潮为客户设计的超级计算机采用浪潮英信NX5440M4服务器,在8U的空间内可扩展20个计算节点,超高的计算密度为用户后期扩展带来方便。
更高效率、更低延迟:若把强大的计算资源比作"资源仓库",有了高速便捷无拥堵的"路",才能把资源利用到极致。浪潮采用648端口全线速无阻塞核心Infiniband交换机,很好地实现了高速率与低延迟,让计算性能得到充分发挥。
全密闭水冷,冷却效率超95%:水冷相对于风冷方式,具有绿色环保,能效比高的优势,不仅大大的节省了用户的空间,也可以优化用户的成本。浪潮根据机房实际条件,采用IT数据中心专用冷水机组,内置自然冷却模块,利用水侧自然冷却实现节能降耗,冷水机组内置低温套件,实现-20℃~+43℃的全工况启动与运行,可以适应冬季时的极低气温环境,同时针对高密度负荷服务器机柜配置高性能机柜级水冷空调,提高冷冻水供水温度至15℃,进一步实现节能增效。整体制冷方案采用密闭机柜级制冷,冷却效率超过95%。
目前,依托高效能服务器和存储技术国家重点实验室、Inspur-Intel中国并行计算联合实验室、Inspur-NIVDIA云超算创新中心等全球领先的研发创新体系,浪潮拥有从万亿次到千万亿次的超级计算机产品研发、系统建设、运维服务能力,拥有完备的HPC软硬件产品线及丰富的应用移植、应用优化经验,为中国气象预报、环保监测、高校科研、石油勘探、生命基因、工业制造等众多行业用户提供了领先优质的超算系统与应用服务,实现了国产高性能计算机系统的海外出口产业化。
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2017
04/12
10:25
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
