
Triton推理服务器12-模型与调度器(2)
在“Triton推理服务器11-模型调度器(1)”文章中,已经说明了有状态(stateful)模型的“控制输入”与“隐式状态管理”的使用方式,本文内容接着就继续说明“调度策略”的使用。
(续前一篇文章的编号)
- 调度策略(Scheduling Strategies)
在决定如何对分发到同一模型实例的序列进行批处理时,序列批量处理器(sequence batcher)可以采用以下两种调度策略的其中一种:
- 直接(direct)策略
当模型维护每个批量处理槽的状态,并期望给定序列的所有推理请求都分发到同一槽,以便正确更新状态时,需要使用这个策略。此时,序列批量处理程序不仅能确保序列中的所有推理请求,都会分发到同一模型实例,并且确保每个序列都被分发至模型实例中的专用批量处理槽(batch slot)。
下面示例的模型配置,是一个TensorRT有状态模型,使用直接调度策略的序量批处理程序的内容:
|
name: "direct_stateful_model" platform: "tensorrt_plan" max_batch_size: 2 sequence_batching { max_sequence_idle_microseconds: 5000000 direct { } control_input [ { name: "START" control [ { kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ] } ] }, { name: "READY" control [ { kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ] } ] } ] } # 续接右栏 |
# 上接左栏 input [ { name: "INPUT" data_type: TYPE_FP32 dims: [ 100, 100 ] } ] output [ { name: "OUTPUT" data_type: TYPE_FP32 dims: [ 10 ] } ] instance_group [ { count: 2 } ]
|
现在简单说明以下配置的内容:
- sequence_batching部分指示模型会使用序列调度器的Direct调度策略;
- 示例中模型只需要序列批处理程序的启动和就绪控制输入,因此只列出这些控制;
- instance_group表示应该实例化模型的两个实例;
- max_batch_size表示这些实例中的每一个都应该执行批量大小为2的推理计算。
下图显示了此配置指定的序列批处理程序和推理资源的表示:
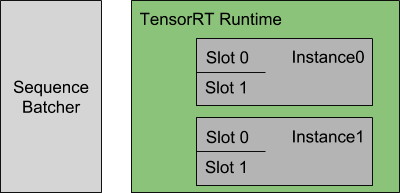
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着Triton可以同时4个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
|
所识别的推理请求种类 |
执行动作 |
|
需要启动新序列 |
|
|
是已分配处理槽序列的一部分 |
将该请求分发到该配置好的批量处理槽 |
|
是积压工作中序列的一部分 |
将请求放入积压工作中 |
|
是最后一个推理请求 |
|
下图显示使用直接调度策略,将多个序列调度到模型实例上的执行:

左边显示了到达Triton的5个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
- 在实例0与实例1中各有两个槽0与槽1;
- 根据接收的顺序,为序列0至序列3各分配一个批量处理槽,而序列4与序列5先处于排队等候状态;
- 当序列3的请求全部完成之后,将处理槽释放出来给序列4使用;
- 当序列1的请求全部完成之后,将处理槽释放出来给序列5使用;
以上是直接策略对最基本工作原理,很容易理解。
接下来要进一步使用控制输入张量与模型通信的功能,下图是一个分配给模型实例中两个批处理槽的两个序列,每个序列的推理请求随时间而到达,START和READY行显示用于模型每次执行的输入张量值:
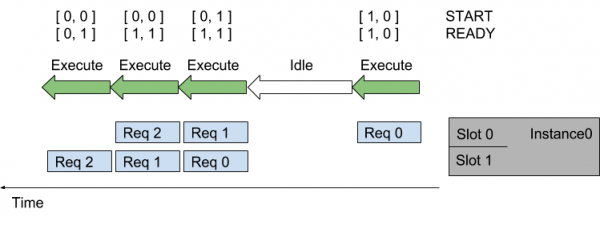
随着时间的推移(从右向左),会发生以下情况:
- 序列中第一个请求(Req 0)到达槽0时,因为模型实例尚未执行推理,则序列调度器会立即安排模型实例执行,因为推理请求可用;
- 由于这是序列中的第一个请求,因此START张量中的对应元素设置为1,但槽1中没有可用的请求,因此READY张量仅显示槽0为就绪。
- 推理完成后,序列调度器会发现任何批处理槽中都没有可用的请求,因此模型实例处于空闲状态。
- 接下来,两个推理请求(上面的Req 1与下面的Req 0)差不多的时间到达,序列调度器看到两个处理槽都是可用,就立即执行批量大小为2的推理模型实例,使用READY来显示两个槽都有可用的推理请求,但只有槽1是新序列的开始(START)。
- 对于其他推理请求,处理以类似的方式继续。
以上就是配合控制输入张量的工作原理。
- 最旧的(oldest)策略
这种调度策略能让序列批处理器,确保序列中的所有推理请求都被分发到同一模型实例中,然后使用“动态批处理器”将来自不同序列的多个推理批量处理到一起。
使用此策略,模型通常必须使用CONTROL_SEQUENCE_CORRID控件,才能让批量处理清楚每个推理请求是属于哪个序列。通常不需要CONTROL_SEQUENCE_READY控件,因为批处理中所有的推理都将随时准备好进行推理。
下面是一个“最旧调度策略”的配置示例,以前面一个“直接调度策略”进行修改,差异之处只有下面所列出的部分,请自行调整:
|
直接(direct)策略 |
最旧的(oldest)策略 |
|
direct { }
|
oldest { max_candidate_sequences: 4 } |
在本示例中,模型需要序列批量处理的开始、结束和相关ID控制输入。下图显示了此配置指定的序列批处理程序和推理资源的表示。
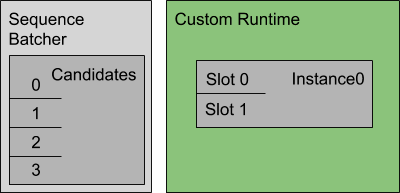
使用最旧的调度策略,序列批处理程序会执行以下工作:
|
所识别的推理请求种类 |
执行动作 |
|
需要启动新序列 |
尝试查找具有候选序列空间的模型实例,如果没有实例可以容纳新的候选序列,就将请求放在一个积压工作中 |
|
已经是候选序列的一部分 |
将该请求分发到该模型实例 |
|
是积压工作中序列的一部分 |
将请求放入积压工作中 |
|
是最后一个推理请求 |
模型实例立即从积压工作中删除一个序列,并将其作为模型实例中的候选序列,或者记录如果没有积压工作,模型实例可以处理未来的序列。 |
下图显示将多个序列调度到上述示例配置指定的模型实例上,左图显示Triton接收了四个请求序列,每个序列由多个推理请求组成:
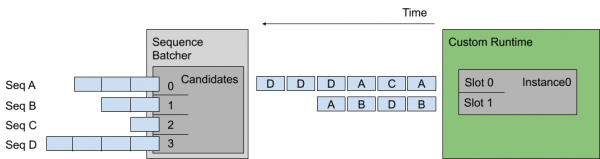
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列D中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在“Triton推理服务器13-模型调度器(3)”文中提供完整的说明。【未完,待续】
来源:业界供稿
好文章,需要你的鼓励


全球数据中心电力需求暴涨,超越电网建设速度
国际能源署发布的2025年世界能源展望报告显示,全球AI竞赛推动创纪录的石油、天然气、煤炭和核能消耗,加剧地缘政治紧张局势和气候危机。数据中心用电量预计到2035年将增长三倍,全球数据中心投资预计2025年达5800亿美元,超过全球石油供应投资的5400亿美元。报告呼吁采取新方法实现2050年净零排放目标。

维吉尼亚理工学院破解单细胞生物学新密码:当大语言模型遇见细胞世界的奇妙变革
维吉尼亚理工学院研究团队对58个大语言模型在单细胞生物学领域的应用进行了全面调查,将模型分为基础、文本桥接、空间多模态、表观遗传和智能代理五大类,涵盖细胞注释、轨迹预测、药物反应等八项核心任务。研究基于40多个公开数据集,建立了包含生物学理解、可解释性等十个维度的评估体系,为这个快速发展的交叉领域提供了首个系统性分析框架。

AMD双轮驱动:路线图与资金互促,收入持续提升
AMD首席执行官苏姿丰在纽约金融分析师日活动中表示,公司已准备好迎接AI浪潮并获得传统企业计算市场更多份额。AMD预计未来3-5年数据中心AI收入复合年增长率将超过80%,服务器CPU收入份额超过50%。公司2025年预期收入约340亿美元,其中数据中心业务160亿美元。MI400系列GPU采用2纳米工艺,Helios机架系统将提供强劲算力支持。

西湖大学团队突破:AI推理模型内存消耗降低50%的秘密武器
西湖大学王欢教授团队联合国际研究机构,针对AI推理模型内存消耗过大的问题,开发了RLKV技术框架。该技术通过强化学习识别推理模型中的关键"推理头",实现20-50%的内存缩减同时保持推理性能。研究发现推理头与检索头功能不同,前者负责维持逻辑连贯性。实验验证了技术在多个数学推理和编程任务中的有效性,为推理模型的大规模应用提供了现实可行的解决方案。
2023
02/02
15:33
分享
点赞

分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
