
TAO系列12-将模型部署到Jetson设备
前面我们花了很多力气在TAO上面训练模型,其最终目的就是要部署到推理设备上发挥功能。除了将模型训练过程进行非常大幅度的简化,以及整合迁移学习等功能之外,TAO还有一个非常重要的任务,就是让我们更轻松获得TensorRT加速引擎。
将一般框架训练的模型转换成TensorRT引擎的过程并不轻松,但是TensorRT所带来的性能红利又是如此吸引人,如果能避开麻烦又能享受成果,这是多么好的福利!
- 一般深度学习模型转成TensorRT引擎的流程
下图是将一般模型转成TesnorRT的标准步骤,在中间”Builder”右边的环节是相对单纯的,比较复杂的是”Builder”左边的操作过程。
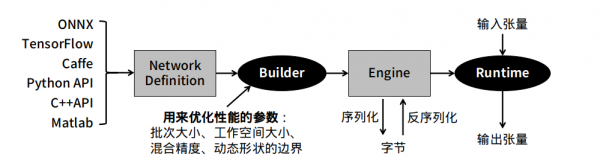
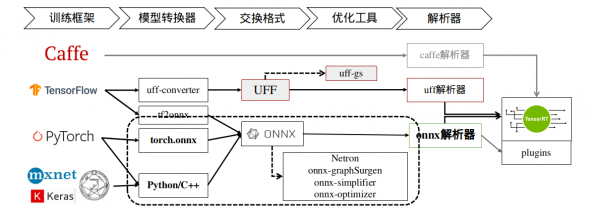
下图就上图 ”Network Definition” 比较深入的内容,TensorRT提供Caffe、uff与ONNX三种解析器,其中Caffe框架已淡出市场、uff仅支持TensorFlow框架,其他的模型就需要透过ONNX交换格式进行转换。
这里以TensorRT所提供的YOLOv3范例来做范例,在安装Jetpack 4.6版本的Jetson Nano设备上进行体验,请进入到TesnorRT的YOLOv3范例中:
|
$ |
cd /usr/src/tensorrt/samples/python/yolov3_onnx |
根据项目的README.md指示,我们需要先为工作环境添加依赖库,不过由于部分库的版本关系,请先将requirements.txt的第1、3行进行以下的修改:
|
1 2 3 4 5 6 |
numpy==1.19.4 protobuf>=3.11.3 onnx==1.10.1 Pillow; python_version<"3.6" Pillow==8.1.2; python_version>="3.6" pycuda<2021.1 |
然后执行以下指令进行安装:
|
$ |
python3 -m pip install -r requirements.txt |
接下来需要先下载download.yml里面的三个文件,
|
$ $
$ |
wget https://pjreddie.com/media/files/yolov3.weights wget https://github.com/pjreddie/darknet/raw/f86901f6177dfc6116360a13cc06ab680e0c86b0/data/dog.jpg |
然后就能执行以下指令,将yolov3.weights转成yolov3.onnx:
|
$ |
./yolov3_to_onnx.py -d /usr/src/tensorrt |
这个执行并不复杂,是因为TensorRT已经提供yolov3_to_onnx.py的Python代码,但如果将代码打开之后,就能感受到这750+行代码要处理的内容是相当复杂,必须对YOLOv3的结构与算法有足够了解,包括解析yolov3.cfg的788行配置。想象一下,如果这个代码需要自行开发的话,这个难度有多高!
接下去再用下面指令,将yolov3.onnx转成yolov3.trt加速引擎:
|
$ |
./onnx_to_tensorrt.py -d /usr/src/tensorrt |
以上是从一般神经网络模型转成TensorRT加速引擎的标准步骤,这需要对所使用的神经网络的结构层、数学公式、参数细节等等都有相当足够的了解,才有能力将模型先转换成ONNX文件,这是技术门槛比较高的环节。
- TAO工具训练的模型转成TensorRT引擎的工具
用TAO工具所训练、修剪并汇出的.etlt文件,可以跳过上述过程,直接在推理设备上转换成TensorRT加速引擎,我们完全不需要了解神经网络的任何结构与算法内容,直接将.etlt文件复制到推理设备上,然后用TAO所提供的转换工具进行转换就可以。
这里总共需要执行三个步骤:
- 下载tao-converter工具,并调试环境:
请根据以下Jetpack版本,下载对应的tao-converter工具:
|
|
Jetpack 4.4:https://developer.nvidia.com/cuda102-trt71-jp44-0 Jetpack 4.5:https://developer.nvidia.com/cuda110-cudnn80-trt72-0 Jetpack 4.6:https://developer.nvidia.com/jp46-20210820t231431z-001zip |
下载压缩文件后执行解压缩,就会生成tao-converter与README.txt两个文件,再根据README.txt的指示执行以下步骤:
- 安装libssl-dev库:
|
$ |
sudo apt install libssl-dev |
- 配置环境,请在 ~/.bashrc 最后面添加两行设置:
|
|
export TRT_LIB_PATH=/usr/lib/aarch64-linux-gnu export TRT_INCLUDE_PATH=/usr/include/aarch64-linux-gnu |
- 将tao-convert变成可执行文件:
|
$ $ $ |
source ~/.bashrc chmod +x tao-converter sudo cp tao-converter /usr/local/bin |
- 安装TensorRT的OSS(Open Source Software)
这是TensorRT的开源插件,项目在https://github.com/NVIDIA/TensorRT,下面提供的安装说明非常复杂,我们将繁琐的步骤整理之后,就是下面的步骤:
|
$ $ $ $ $ $ $
$ $
$ |
export ARCH=请根据设备进行设置,例如Nano为53、NX为72、Xavier为62 export TRTVER=请根据系统的TensorRT版本,例如Jetpack 4.6为8.0.1 git clone -b $TRTVER https://github.com/nvidia/TensorRT TRToss cd TRToss/ git checkout -b $TRTVER && git submodule update --init --recursive mkdir -p build && cd build cmake .. \ -DGPU_ARCHS=$ARCH \ -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ \ -DCMAKE_C_COMPILER=/usr/bin/gcc \ -DTRT_BIN_DIR=`pwd`/out \ -DTRT_PLATFORM_ID=aarch64 \ -DCUDA_VERSION=10.2 make nvinfer_plugin -j$(nproc) sudo mv /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1 /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1.bak sudo cp libnvinfer_plugin.so.8.0.1 /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1 |
这样就能开始用tao-converter来将 .etlt文件转换成TensorRT加速引擎了。
- 用tao-converter进行转换
- 首先将TAO最终导出(export)的文件复制到Jetson Nano上,例如前面的实验中最终导出的文件ssd_resnet18_epoch_080.etlt,
- 在Jetson Nano上执行TAO的ssd.ipynb最后所提供的转换指令,如下:
|
$ $ |
%set_env KEY= tao converter -k $KEY \ -d 3,300,300 \ -o NMS \ -e ssd_resnet18_epoch_080.trt \ # 自己设定输出名称 -m 16 \ -t fp16 \ # 使用export时相同精度 -i nchw \ ssd_resnet18_epoch_080.etlt |
这样就能生成在Jetson Nano上的ssd_resnet18_epoch_080.trt加速引擎文件,整个过程比传统方式要简便许多。【完】
来源:业界供稿
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2022
05/31
11:23
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破

{kind=link}