
TAO系列08-图像分类的模型训练与修剪
图像分类(image classification)是视觉人工智能的最基础应用,目前TAO模型训练工具支持resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny等10种神经网络,其中resnet、vgg、darknet、cspdarknet还有不同结构层数的区分。
在TAO启动器中只用 “classification” 这个任务指令,去面对上面所列出的十多种网络结构,其关键处就是结合“配置文件”的协助,因此这个配置文件的设置组是TAO工具的核心所在,也是本文一开始要花时间说明的部分。
在cv_samples下面的classification项目,是TAO工具的图像分类模型训练的标准范例,里面提供classification.ipynb执行脚本与specs目录下两个.cfg配置文件,基本上在执行脚本里只需要修改一些路径的设定就行,其余细节都在配置文件里面进行调整,包括所选择的神经网络种类与结构。
这个项目以Pascal VOC 2012数据集作为训练源,与TAO所支持的格式并不相同,因此在训练之前还需要进行格式的转换。还好这里的转换比较简单,只要将图像分别存放在以“类别”所命名的目录下就可以,同时分割成训练与校验两个不同用途的数据集,在脚本里透过一段简单的Python代码就能完成,并没有什么难度。
最后在训练之前,可以选择是否启动 “迁移学习” 的功能?在这个实验中也会示范这中间所得到的精度差异,让大家直接体验到迁移学习所带来的的好处。
以下就将几个执行重点提出来说明,协助大家可以轻松地执行。
- 配置文件内容
TAO的CLI指令集只使用一个classification去面对所有的图形分类应用,其余的工作就全部交给配置文件去处理。在图像分类的配置文件里,主要有以下三个配置组:
- model_config:存放神经网络种类、结构(层数)与特性的内容,以下列出比较重要的部分:
- arch:网络名称,可使用所有已支持的网络,包括resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny等;
- n_layer:有些网络有多种结构层,例如resnet有10/18/34/50/101、vgg有16/19、darknet有19/53、cspdarknet有19/53等;
其余参数都按照配置文件里面所设定的值,因为NGC提供的预训练模型是按照这些参数所训练的,能在迁移学习过程中得到比较好的效果。
- train_config:执行训练时所需要参考的
- train_dataset_path: 训练用数据集的位置,需要输入在容器内的完整路径
- val_dataset_path: 校验用数据集的位置,需要输入在容器内的完整路径
- pretrained_model_path: 预训练模型位置,需要输入在容器内的完整路径
- batch_size_per_gpu:请根据GPU显存大小进行调整
- n_epochs:训练的回合数
- n_workers:CPU的并行线程数,请根据实际CPU核数量进行调整
其余参数清先安装范例所提供的设置。
- eval_config:评估模型时所需要用到的参数,需要输入在容器内的完整路径
- eval_dataset_path: 测试用数据集路径,与前面相同
- model_path: 在前面训练模型过程中所生成的.tlt模型文件中,挑选效果最好的一个模型来进行评估,通常最后一个的效果会最好。这里的”resnet_080.tlt”是因为训练回合数为80。
其余参数清先按照范例所提供的设置。
以上关于路径部分的设置,只要遵循脚本一开始 “0. Set up env variables and map drives”的配置规则,文件里基本上不需要做修改。其他参数的定义与设定值,请访问https://docs.nvidia.com/tao/tao-toolkit/text/image_classification.html#model-config 有完整的说明。
- 数据集格式转换与分配
TAO支持的图像分类数据格式,是以“分类名”作为路径名,将所有该类的图像都放置到分类名目录之下,例如有20个分类的数据集,就会有20个分类目录。
本实验使用Pascal VOC的VOCtrainval_11-May-2012.tar(1.9GB)数据集,可以用脚本提供的链接,也可以在https://pan.baidu.com/s/1JhnBCRi32xblhSSWFmF5aA(密码: gg95)下载压缩文件。
请按照脚本的数据集处理过程,包括放置路径与解压缩的指令。由于这个数据集的格式并不符合TAO的要求,因此脚本中使用一段Python代码来进行转换,详细内容请自行阅读代码,其主要功能就是将下图左边VOC路径结构转换成右边符合TAO要求的结构,存放在“formated”目录下。

接着再将“formated”的数据,随机分割成train、val与test三大类存放到“split”目录下,作为后面执行训练、校验与测试时所需要的数据路径。
- 动迁移学习功能
TAO的模型训练继承TLT的迁移学习功能,只要在配置文件中的“train_config”配置组里,指定好“pretrained_model_path:”的路径就可以,如果不想启用这个功能,只要在这个参数前面用 “#” 去关闭就行。
在NGC提供300多个预训练模型,我们需要挑选合适的模型来协助执行迁移学习,这部分的下载需要使用NGC的指令来操作,在脚本中已经提供完整的安装步骤,只要执行命令块就行,然后用以下指令去下载所选的模型:
|
ngc registry model download-version 模型全名 --dest 本地存放路径 |
这里配合所使用的网络种类,挑选nvidia/tao/pretrained_classification:resnet18作为本次的预训练模型,文件大小在80MB左右。
下图左方是这个实验中,关闭迁移学习功能所训练出来的模型,经过下面评估步骤所测算出来的结果,下图右方则是在基于NGC下载的预训练模型基础上,利用迁移学习功能所训练出来的模型效果,总体来说得到的精准度提升还是很明显的。
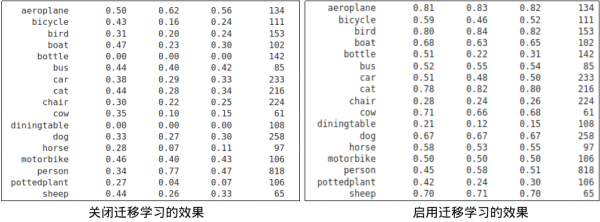
但如果是缺乏合适预训练模型的状况下,也不能硬是挑选不合适的模型来做迁移学习,可能得到的效果会更差。
- 执行模型训练
当前面的准备工作都做到位之后,这个步骤就是水到渠成。执行训练所耗费的时间就只跟GPU卡的总体计算资源有关系,如果您的设备有一张以上GPU计算卡的话,可以透过TAO指令以下参数,去调整可用的计算资源:
- --gpus [N]:指定要调用的GPU卡数量;
- --gpu_index 编号1 [编号2...]
例如设备上有2片GPU卡时,想要全部用上的话就直接用 “--gpus 2” 参数进行调用;如果设备上有4片GPU计算卡,想要指定调用0号与3号这两张卡的时,就用 “--gpus 2 --gpu_index 0 3” 参数,就能精准调用指定的GPU来进行训练。
在这个图像分类实验中,我们以NVIDIA RTX2070与RTX3070进行测试,这两张计算卡都具有8GB显存。在固定回合数为80、batch_size_per_gpu为64的条件下,所耗费的训练时间如下:
- 单GPU/3070-8G : 52分19秒
- 单GPU/2070-8G : 62分44秒
- 双GPU/3070+2070 : 38分03秒
- 修剪模型
这个步骤的目的,是要在维持足够精准度的前提下缩小模型的尺寸,越小的模型会消耗更少的计算资源,特别是内存与显存。
这对于计算资源充沛的计算设备来说,所体现的差异并不明显,但是对于计算资源相对吃紧的边缘设备来说,就有非常大的影响,甚至影响推理识别的性能,因此请自行决定是否需要执行这个步骤。
这里的要剪裁的对象是已训练好的模型,而不是从网络结构层进行融合处理,最简单的方法就是调整 “-pth(阈值)” ,在精确度与模型大小之间取得平衡,调整的值越高就会得到越小的模型,但精准度会受到比较大的损失,这就需要经过不断尝试去调节出满足要求的模型。
以这个classification项目为例,在80回合中训练的模型大小为87.7MB,通常最后一回合训练的模型精确度会最好,因此用resnet_080.tlt模型进行修剪测试:
- -pth=0.6:修剪后生成大小为38.5MB的resnet18_nopool_bn_pruned.tlt
- -pth=0.3:修剪后生成大小为44.2MB的resnet18_nopool_bn_pruned.tlt
至于修剪后模型对精确度产生怎样的影响?就需继续往下执行“再训练”之后,看看评估的效果如何!
- 模型再训练
经过修剪的模型并不能立即使用,而是作为“再训练”的预训练模型,再次利用迁移学习的技巧,以前面的数据集进行模型再训练的工作,唯一不一样的地方是这次使用的配置文件为classification_retrain_spec.cfg,这个配置内容与前面的classification_spec.cfg只有三个差异的地方:
- 在model_config设置组少了两个”freeze_blocks”设置;
- 在train_config设置组的“pretrained_model_path”换成前面修剪过的模型;
- 在eval_config设置组的“model_path”换成修剪后重新训练的模型
继续往下执行“7. Retrain pruned models”与“8. Testing the model”两个步骤,就能得到修剪过模型的精确度评估结果。
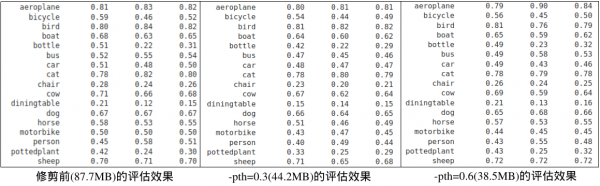
从上面的比较表中可以看出,这个剪裁的方式对模型文件大小的影响是很明显的,但精确度的损失并不是太大,所以这个剪裁赢视为有效果。
- 本实验结语
这个范例主要让大家体会并熟悉TAO的配置文件与执行流程,事实上TAO所提供的范例几乎都是一样的流程,后面还有导出模型、INT8优化、生成TensorRT引擎的步骤,我们结合在后面的物件检测范例中进行说明。【完】
来源:业界供稿
好文章,需要你的鼓励


CoreWeave LOTA技术实现对象数据高速全球传输
CoreWeave发布AI对象存储服务,采用本地对象传输加速器(LOTA)技术,可在全球范围内高速传输对象数据,无出口费用或请求交易分层费用。该技术通过智能代理在每个GPU节点上加速数据传输,提供高达每GPU 7 GBps的吞吐量,可扩展至数十万个GPU。服务采用三层自动定价模式,为客户的AI工作负载降低超过75%的存储成本。

IDEA研究院等机构联手打造智能AI助手:让机器像人类一样思考和学习的突破性技术
IDEA研究院等机构联合开发了ToG-3智能推理系统,通过多智能体协作和双重进化机制,让AI能像人类专家团队一样动态思考和学习。该系统在复杂推理任务上表现优异,能用较小模型达到卓越性能,为AI技术的普及应用开辟了新路径,在教育、医疗、商业决策等领域具有广阔应用前景。

谷歌DeepMind与CFS合作开发核聚变等离子体AI控制系统
谷歌DeepMind与核聚变初创公司CFS合作,运用先进AI模型帮助管理和改进即将发布的Sparc反应堆。DeepMind开发了名为Torax的专用软件来模拟等离子体,结合强化学习等AI技术寻找最佳核聚变控制方式。核聚变被视为清洁能源的圣杯,可提供几乎无限的零碳排放能源。谷歌已投资CFS并承诺购买其200兆瓦电力。

AI训练新突破:上海AI实验室让大模型自己当老师,推理和判断能力同步飞跃
上海人工智能实验室提出SPARK框架,创新性地让AI模型在学习推理的同时学会自我评判,通过回收训练数据建立策略与奖励的协同进化机制。实验显示,该方法在数学推理、奖励评判和通用能力上分别提升9.7%、12.1%和1.5%,且训练成本仅为传统方法的一半,展现出强大的泛化能力和自我反思能力。
2022
04/20
16:54
分享
点赞

Littelfuse推出首款具有SPDT和长行程且兼容回流焊接的发光轻触开关
至顶科技助力AI创业者,在HICOOL峰会探索“如何用AI赚到第一桶金”
CoreWeave LOTA技术实现对象数据高速全球传输
谷歌DeepMind与CFS合作开发核聚变等离子体AI控制系统
微软为Windows 11推出全新Copilot自动化功能
苹果研究人员探索AI如何预测Bug、编写测试并修复代码
刚果称全球最大水电站可为AI数据中心供电
HPE Alletra存储业务获得战略重点关注
谷歌DeepMind与核聚变初创公司合作的真实原因
Omdia预测:超大规模云市场销售额2030年将达1630亿美元
Oracle全面押注AI,用户仍在摸索应用路径
Aramex与AWS携手推进全球物流数字化转型
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
