
TAO系列01-简化模型训练流程的TAO工具
特征模型(features model)是人工智能深度而学习的灵魂,其优劣程度就决定了前端推理结果的成败,包括计算性能与精确度的综合考量,是整个人工智能应用的最关键环节,而提取特征的训练(或称为学习)过程,是创建该项人工智能应用的起点。
深度学习的模型训练流程是固定的,但以下三个部分是最为耗费开发人员心力的阶段:
- 选择合适的神经网络算法:
深度学习的发迹也才短短10年左右的光景,目前只能算是初步爆发的阶段,至今也有几十种综合指标都相当优异的神经网络结构,大部分的算法都还在持续进化的过程中,到目前为止尚未出现有绝对优势的神经网络。
这种状况对于开发人员来说就造成抉择上的难题,因为各种算法都有不同的处理逻辑与侧重点,这些是需要具备足够厚实的数学基础的人,才有机会深入去分辨不同算法之间的优劣点,是有不低的准入门槛。
不过从实用性的角度来看,最简单的验证方法就是透过实际的执行,先挑选2~3种在性能与精准度都相对优异的神经网络,直接完成从模型训练到推理检测的流程。
- 选择执行训练与推理的框架:
这部分通常推荐选择具有雄厚实力的商业单位所维护的通用性框架,例如Google的TensorFlow、FaceBook的PyTorch、微软的MXNet等等,不仅能确保对更多神经网络算法的支持,在生命周期方面也比较有保障。
开发人员虽然不一定需要完全理解该神经网络的数学原理,但至少得要掌握网络结构之间的关系、节点内的计算式,以及输入与输出的格式。
对于框架所支持的神经网络,开发人员可以用比较少的代码去实现模型训练与推理检测的工作,如果遇到框架所不支持的网络,就需要自行撰写代码去实现这个神经网络的完整计算,这是个不小的工程。
- 针对终端设备的参数优化:
所有模型的执行效果,都必须在最终推理设备上进行验证后才能确认。
但是推理设备上的配置与性能并不一致,每个项目对性能与精确度的要求也不尽相同,因此这个调优的过程就必须反反复复的进行,如果某一方面未能达到标准的话,就得回到模型训练步骤去进行参数调整。
如果经过各种参数调试之后,仍然无法在性能与精确度都满足要求的时候,可能就需要回到第一步去更换神经网络种类,这样会连带影响所撰写的训练与推理的代码,几乎等于从零开始另一个项目的过程。
以上三个部分只是整个深度学习应用中比较明显的问题,也是最主要耗费时间的阶段,通常来说都得花费数周到数月的时间去进行。
针对这些繁琐的问题,英伟达于2021年推出的TAO(Train Adapt Optimize)模型训练工具,能够非常有效地解决以上的主要困扰,即便是不熟悉神经网络原理与算法的技术人员,也可以地在数天内轻松地掌握模型训练工作。

为了解决上述的主要问题,英伟达为TAO工具做了以下的处理,非常大幅度地减少开发过程的工作量:
- 集成功能强大的机器学习框架:
TAO并非英伟达自行重头开发的模型训练工具,而是紧密集成TensorFlow与Pytorch这两个业界龙头级框架,并且分别面向“视觉AI”与“对话AI”两大领域。
这个战略思考点是非常明智的,因为人工智能领域的神经网络算法,仍处于高速迭代与翻新的阶段,维护与更新一套通用类深度学习框架,需要足够深厚的领域专业度,与极为庞大的人力与物力成本做支撑。
这两个分别由Google与Facebook所维护的框架,不仅更新神经网络支持列表的速度最快,所提供的开发资源也相对充沛,包括所支持的神经网络结构与算法,这样能非常有效地降低开发复杂度。
目前TAO已经支持30多种基础类与复合类神经网络,分别隶属于以下两大分类:
- 视觉类:augment、bpnet、classification、dssd、emotionnet、efficientdet、fpenet、gazenet、gesturenet、heartratenet、lprnet、mask_rcnn、retinanet、ssd、unet、yolo_v3、yolo_v4、yolo_v4_tiny、converter、detectnet_v2、multitask_classification、faster_rcnn等
- 对话类:speech_to_text、speech_to_text_citrinet、action_recognition、text_classification、question_answering、token_classification、vocoder、intent_slot_classification、punctuation_and_capitalization、spectro_gen、n_gram等
能支持这么庞大且复杂的神经网络种类,必须归功于TensorFlow与Pytorch这两个强大框架的支撑,并且TAO所支持的类型也会随着这两个框架的扩充而增加,充分利用起Google与Facebook两大巨头的技术资源。
- 实现Zero Coding的CLI指令接口:
要知道TensorFlow与Pytorch这两个深度学习框架的优点是功能强大,但伴随的难点是繁琐且复杂,二者光结构说明与开发指导都在近千页的规模,即便撇开神经网络算法不谈,光要熟悉任何一个框架的使用,至少也得花上数周至数月的时间。
如果再加上对个别神经网络算法的摸索与理解,然后在框架上开发/测试/除错有针对性的代码,这需要相当高的综合技术能力,绝非一般开发人员所能胜任。而这个组合性问题,也是目前延缓人工智能发展进度的一项主要原因。
为了解决这个问题,英伟达为TAO提供一套高阶封装的CLI指令接口,这是一套基于Python所开发的指令解析器,让开发人员透过指令的操作,去执行不同类别神经网络的模型训练、精度评估、剪裁、推理等复杂的工作,而不需要撰写任何一行的C++或Python代码,真正实现 “Zero Coding” 的境界。
操作人员只要熟悉以下的指令格式,就能非常轻松地执行模型训练的相关操作:
tao <主功能/网络种类> <子功能> [配套参数群]
这里的 <子功能> 包括database_convert、train、evaluate、prune、export、inference等操作,在[配套参数群] 还能指定参与计算的GPU数量与编号等,大概花上几十分钟就能轻松掌握这套指令格式的逻辑。
例如要使用编号1的GPU去训练ssd模型,大致的指令内容如下:
|
$ |
tao ssd train --gpu_index=1 -e <配置文件路径> -r <结果输出路径> |
例如要将KITTI数据集转换成YOLO_v4所用的格式,大致指令如下:
|
$ |
tao yolo_v4 database_convert -d <配置文件路径> -o <结果输出路径> |
使用这样的指令集,即便是不熟悉TensorFlow或Pytorch框架、不了解神经网络算法的开发人员,也能非常轻松地执行各种神经网络的模型训练工作,让企业彻底摆脱那些艰涩的技术枷锁。
这套高阶封装的CLI指令集,让我们能完整利用两个强大框架的功能与资源,却又不用受到其复杂度的困扰,真正享受到“得其所长、避其所短”的效果,算得上是TAO工具的灵魂所在。
- 提供针对性的配置文件:
要实现指令的单纯化的目标,就需要有完整的配置系统作为搭配,这个部分会是开发人员在TAO工具上最需要花时间的内容。
由于每种神经网络都有其独特的结构与参数种类,因此必须为每个网络提供各自的配置文件,例如图像分类(classification)的配置文件中,都有model_config、train_config、eval_config三个配置组,物件检测(object detection)配置文件还多了nms_config、augmentation_config、dataset_config等配置组。
此外,在训练过程还有dataset_convert、train、prune、retrain等阶段,都有一小部分参数需要进行微调,这些细节就需要开发人员对个别神经网络结构有进一步的了解,所幸TAO为目前所支持的神经网络都提供优化过的配置文件,使用者不需要从0开始进行配置,只要以范例文件为基础进行修改就可以。
绝大部分时候,我们需要修改的部分,就只有一些文件路径(xxx_path)、训练回合数(num_epoch)、批量数(batch_size_per_gpu),以及dataset_config里面的类别名称(target_class_mapping)的对应值。除非有特别的要求,并且您熟悉该神经网络的结构与特性,否则使用英伟达提供的优化配置参数,是足以获得一定水平之上的效果。
- 集成迁移学习功能:
这是一种将学习到的特征,从一个应用程序转移到另一个应用程序的过程。与从头开始训练同一模型相比,迁移学习的方式可以使用较少的数据集或较短的时间,训练出相同精确度的模型。
在英伟达NGC中心里,提供数十种基于专业数据集、在高端训练设备、由专业技术人员,所预训练出来的优质模型文件,可以纳入TAO的模型训练过程,非常有效地减少模型训练所耗费的时间成本。
以上就是TAO工具的关键技术,经过英伟达的一番整合之后,将“神经网络算法知识”与“机器学习框架”这两个技术门槛最高的部分给边缘化了,也就是说不具备这两方面技术能力的人,都能轻松执行模型训练的任务,剩下避不开的任务,就是“数据收集与标注”这项技术含量较低的工作了。
下图是TAO工具的技术框架图,可以看到这个工具支持视觉人工智能(Vision AI)与对话人工智能(Conversation AI)两大类应用,能让我们很轻松地创建更高价值的整合性人工智能应用。
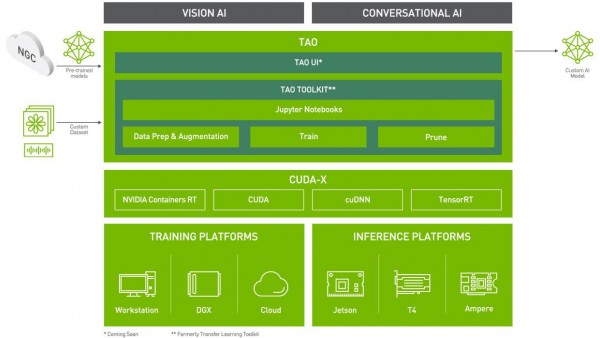
除此之外,TAO工具在便利性方面,还具备以下三个特色:
- 安装便利性:基于Docker容器技术进行封装
使用者只需要在装有CUDA GPU计算卡的x86设备上,安装合适的驱动与docker、nv-docker等管理软件即可,其他所需要的CUDA、CUDNN、TensorRT等开发资源,都预先打包在容器镜像之内。
- 操作便利性:以Jupyter为交互操作界面
这是个基于浏览器的互动式操作界面,使用者可以在任何一台能连上训练设备的电脑上执行模型训练的工作。
TAO也为所支持的神经网络都提供专属的执行脚本,并将所有需要的执行步骤提供完整的CLI指令,使用者只需要简单调整数据存放路径与配置文件的对应路径即可,几乎不需要撰写任何C++或Python代码;
- 部署便利性:与推理套件无缝对接
TAO所训练出来的文件,是兼容于TensorRT加速引擎的中间模型,只要在推理平台上透过“tao_converter”工具,就能轻松转换成该平台上的TensorRT加速引擎,无需透过繁琐的ONNX方式进行转换。
此外,这个中间模型也能在推理平台上,无缝地与DeepStream、Triton Server、RIVA这些推理工具进行对接,大幅降低过去部署过程的复杂度,让整个应用流程变得十分轻松。
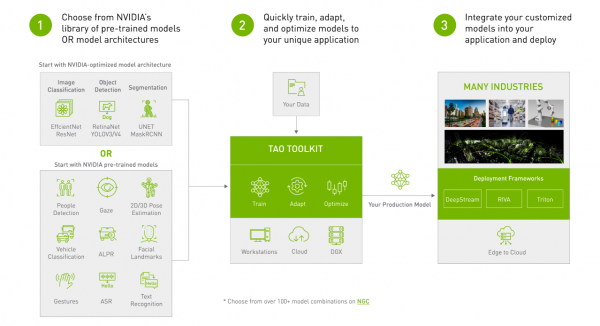
现在开始使用TAO工具,就能比传统模型训练的过程,减少90%的学习、撰写代码、测试与部署等步骤所需要的时间,让研发单位提高应用开发效率,更快速、更高频地开发高价值的人工智能应用。【完】
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2022
03/01
16:11
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
