
NVIDIA Jetson Nano 2GB 系列文章(31):DeepStream 多模型组合检测-1
前面已经介绍过关于DeepStream各种输入源的使用方式,而且Jetson Nano 2GB上开启4路输入(两个摄像头+两个视频文件),都能得到25FPS以上的实时性能,但毕竟“单一检测器(detector)”检测出来的物件是离散型的内容,例如车、人、脚踏车这些各自独立的信息。有没有什么方法能够实现“组合信息”呢?例如“黑色/大众/SUV车”!
DeepStream有一个非常强大的功能,就是多模型组合检测的功能,以一个主(Primary)推理引擎(GIE:GPU Inference Engine)去带着多个次(Secondary)推理引擎,就能实现前面所说的功能。
本实验在Jetson Nano 2GB上,执行4种模型的组合检测功能,能将检测到的车辆再往下区分颜色、厂牌、车种等三个进一步信息,在4路输入视频状态下能得到20+FPS性能,并且我们将显示的信息做中文化处理(如下图)。
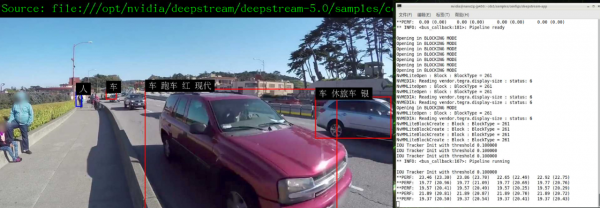
在Jetson Nano 2GB上已经安装的DeepStream的范例中,已经预先准备了多个与“车”有关的检测器,可以在/opt/nvidia/deepstream/deepstream/samples/models目录下,看到以下信息:
|
nvidia@nano2g-jp450:/opt/nvidia/deepstream/deepstream/samples/models$ ls -l 总用量 24 drwxrwxrwx 2 root root 4096 7月 13 23:49 Primary_Detector drwxrwxrwx 2 root root 4096 7月 13 22:45 Primary_Detector_Nano drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_CarColor drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_CarMake drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_VehicleTypes drwxrwxrwx 4 root root 4096 2月 8 21:49 Segmentation |
简单说明一下每个目录所代表的的意义:
- Primary_Detector:作为项目的主检测器,这是用Caffe框架以ResNet10网络所训练的4类检测器,能检测“Car”、“Bicycle”、“Person”、“Roadsign”四种物件,这个数据可以在目录下的labels.txt中找到。
- Primary_Detector_Nano:将Primary_Detector里的模型,针对Jetson Nano(含2GB)的计算资源进行优化的版本。
- Secondary_CarColor:车子颜色的次级检测器
- Secondary_CarMake:生产厂商的次级检测器
- Secondary_VehicleTypes:车子种类的次级检测器
组成结构也十分简单,其中主(Primary)检测器只有一个,而且必须有一个,否则DeepStream无法进行推理识别。次(Secondary)检测器可以有好几个,这里的范例就是针对“Car”这个类别,再添加“Color”、“Maker”、“Type”这三类元素,就能获取视频图像中物件的更完整信息。
在Jetson Nano的/opt/nvidia/deepstream/deepstream/samples/config/deepstream-app下面的source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt,就已经把这个组合检测器的配置调试好,现在直接执行以下指令:
|
cd /opt/nvidia/deepstream/deepstream/samples/config/deepstream-app deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt |
现在看到启动四个视频窗,但是每个视窗的执行性能只有8FPS,总性能大约32FPS,并不是太理想。
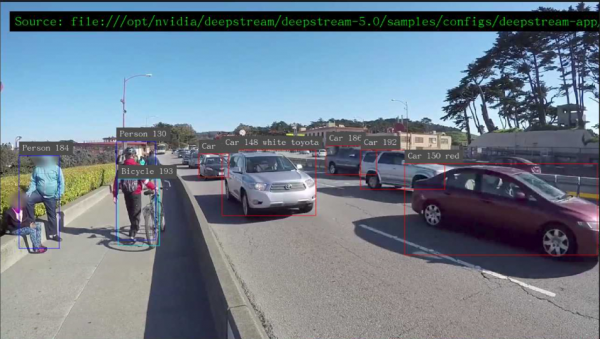
接下来看看怎么优化这个配置文件,
- 首先要执行模型组合功能功能,必须把“tracker”功能打开,不过可以关闭追踪号的显示,因此保留“enable=1”,将下面的“display-tracking-id=”设为“0”
- 由于我们在Jetson Nano 2GB版本上进行实验,需要进行以下的调整。如果您要在AGX Xavier或Xavier NX上上执行的活,请忽略这个步骤。
修改主检测器[primary-gie]的模型:配置文件中预设的是“Primary_Detector”检测器,这里得修改成专为Nano所训练的版本,这里修改以下几个地方:
-
- model-engine-file路径的“Primary_Detector”部分改成“Primary_Detector_Nano”
- config-file的文件改成config_infer_primary_nano.txt
因为Jetson Nano(含2GB)并不支持int8计算精度,因此还需要做以下修改:
-
- 将“_b4_gpu0_int8.engine”改成“_b8_gpu0_fp16.engine”
- 将所有“xx_gpu0_int8.engine”改成“xx_gpu0_fp16.engine”
- 将追踪器从原本的ibnvds_mot_klt.so改成 libnvds_mot_iou.so,用“#”变更注释的位置就可以。
修改完后重新执行,可以看到每个窗口的检测性能提升到10~12FPS,总性能提升到40~48FPS,比原本提升12~50%,不过距离理想中的25FPS还有很大的差距。
执行过程中如果遇到“There may be a timestamping problem, or this computer is too slow.”这样的信息,就把[sink0]下面的“sync=”设定值改为“0”就可以。
现在看看是否还有什么可调整的空间?参考前一篇文章“DeepStream-04:Jetson Nano摄像头实时性能”所提到的,将[primary-gie]下面的“interval=”设定为“1”,然后再执行应用时,发现每个输入源的识别性能立即提升到20FPS左右(如下图),总性能已经能到80FPS左右,比最初的32FPS提升大约2.5倍,这已经很接近实时识别的性能。
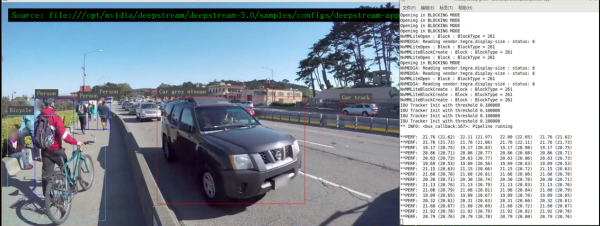
好了,在Jetson Nano 2GB上已经能达到接近实时推理的性能,是相当好的状态。
如果对于显示输出的状态有些不满意的话,我们按照下面的步骤去执行,将“英文”类别名改成“中文”,并且将边框变粗、字体放大,就能更轻松看到推理的效果:
- 所有的显示名称,都在models目录下个别模型目录里的labels.txt,可以将里面的内容全部改成中文。
例如deepstream/samples/models/Secondary_CarMake的“labels.txt”内容改为“广汽;奥迪;宝马;雪佛兰;克莱斯勒;道奇;福特;通用;本田;现代;英菲尼迪;吉普;起亚;雷克萨斯;马自达;奔驰;日产;速霸路;丰田;大众”,其他的就比照办理。
注意:这个顺序不能改变!
- 边框宽度:修改[osd]下面的“board-width”值,推荐2~4比较合适;
- 字体大小:修改[osd]下面的“texe-size”值,推荐15~18比较合适;
- 其他:请自行设定
现在重新执行这个deepstream-app的应用,就能得到本文一开始所显示的效果:
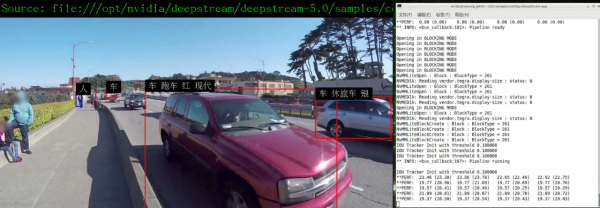
如何?这样的效果与性能就是在Jetson Nano 2GB实现的!【完】
来源:业界供稿
好文章,需要你的鼓励


Google推出通用商务协议并在Gemini中集成购买按钮
谷歌在AI购物战中加码,宣布将Gemini打造成购物平台,并与Shopify、沃尔玛、塔吉特等主要零售商合作推出开源标准。公司发布了通用商务协议(UCP),旨在简化AI代理与零售商系统间的通信。新标准将为搜索和Gemini提供结账功能,用户可直接通过AI工具购买商品。已获得Visa、万事达、PayPal等20多家公司支持。此举使谷歌与微软Copilot和OpenAI的ChatGPT竞争。

德国机构首创免训练人脸质量评估技术:Vision Transformer也能当“质检员“
德国弗劳恩霍夫研究院提出ViTNT-FIQA人脸质量评估新方法,无需训练即可评估图像质量。该方法基于Vision Transformer层间特征稳定性原理,通过测量图像块在相邻层级间的变化幅度判断质量。在八个国际数据集上的实验显示其性能可媲美现有最先进方法,且计算效率更高,为人脸识别系统提供了即插即用的质量控制解决方案,有望广泛应用于安防监控和身份认证等领域。

非洲电信基础设施巨头数字化转型实战访谈
Helios Towers供应链总监Dawn McCarroll在采访中分享了公司的数字化转型经验。作为一家在非洲和中东地区运营近15000个移动通信塔站的公司,Helios正通过SAP S/4Hana系统升级、AI技术应用和精益六西格玛方法论来优化供应链管理。McCarroll特别强调了公司Impact 2030战略中的数字包容性目标,计划在未来五年内培训60%的合作伙伴员工掌握精益六西格玛原则,并利用大数据和AI技术实现端到端的供应链集成。

临床AI大模型的人格面具:布朗大学揭示医疗角色扮演的双刃剑效应
布朗大学联合图宾根大学的研究团队通过系统实验发现,AI医疗助手的角色设定会产生显著的情境依赖效应:医疗专业角色在急诊场景下表现卓越,准确率提升20%,但在普通医疗咨询中反而表现更差。研究揭示了AI角色扮演的"双刃剑"特性,强调需要根据具体应用场景精心设计AI身份,而非简单假设"更专业等于更安全",为AI医疗系统的安全部署提供了重要指导。

