
Jetson Nano 2GB 系列文章(26): “Hello AI World”物件检测的模型训练
与前面“图像分类的模型训练”几乎完全一致的步骤,本文要带着大家来建立自己专属的物件检测模型,这是实用性较高的部分,因为物件检测的应用比较接地气,能轻易地与生活周遭的场景相结合,所以以“物件检测的模型训练”作为“Hello AI World”系列文章的结尾,是非常有意义的事情。
任何应用的模型训练,都必须从“数据集的收集与整理”开始。前面“图像分类模型训练”里使用的是KITTI数据集格式,至于物件检测所使用的数据集,就比图像分类要复杂很多,虽然“图像”本身可以是一样的,但是在每张图形上都必须更进一步地将所需要检测的物件“标注(annotate)”出来,目前已经有非常多的“图像标注工具”可以使用。
下图就是使用labelimg这个开源工具对图像进行标注的任务,将每个标注的图框给与指定的单一分类,每张图形都可能有多个分类与多个物件,标框的原则也会影响将来的推理结果,如果标框过程比较粗糙(边界界定不清楚),后面得到的结果也会比较粗糙。
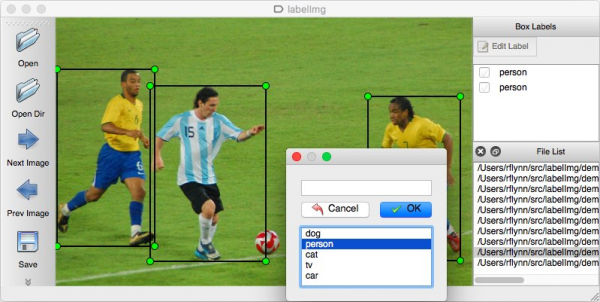
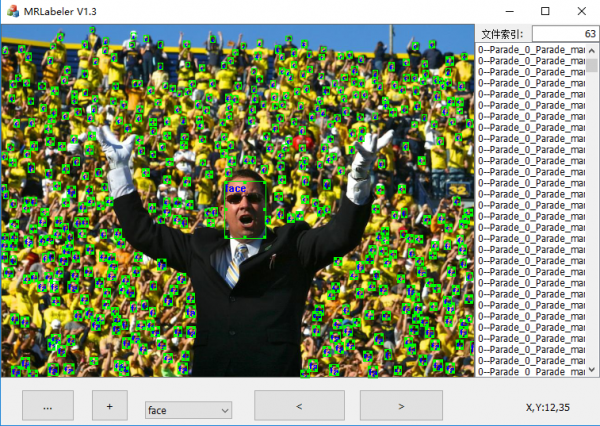
下面一张图是比较极端的,在一张图像中标注出上百个“face”类别的物件。
这个标注过程的工作量比简单的图像分类要高出许多倍,但是如果要做出属于自己的应用,这个过程必不可少。
由于各种数据集之间的结构并不一致,目前使用率较高的主要是Pascal VOC、MS-COCO与Google OpenImages这几个数据集,在Hello AI World项目的物件检测模型训练工具里,内建支持VOC与OpenImages这两种格式,因此这里的实验也主要以这两种格式为主,如果您手边有其他格式的数据集,可以透过网上很多工具,或者上传到http://roboflow.com去进行格式转换。
项目虽然提供camera-capture这个“现场抓图”的工具(如下图),但只能接受摄像头这个输入源,缺乏对单张图像进行标注功能,因此只能作为教学用途或者数据集补充功能,并不适合做批量的图像标注任务。

比较推荐labelimg与labelme这里能批量操作,并且能输出VOC格式的工具,请自行在网上寻找这些工具的安装与使用方法,本文的重点是引导大家将标注好的VOC格式或OpenImages格式的数据集,使用Pytorch框架提供的迁移学习功能,模型训练用的代码是train_ssd.py,表示用的网络模型为SSD,进行物件检测的模型训练任务。
一开始实验之前,请先执行以下三个步骤:
|
1
2
3 |
# 变更到指定工作目录
# 下载 PyTorch迁移学习的预训练模型 mobilenet-v1-ssd-mp-0_675.pth # 存放到指定位置 ssd/models
# 安装训练模型所需要的库
|
接下来分别以VOC格式与OpenImages格式的数据集做范例,分别进行整个模型训练的过程,这两种类型的执行差异,只有第一步的“数据集准备”有所不同,后面的“模型训练”、“转成ONNX格式”与“推理识别”等部分的步骤是完全一样的。
Step1:准备与整理数据集
进到工作目录之后,下面已经预先开好data与models两个子目录,后面的实验会将数据部分放在data目录下的对应项目中,训练的模型会放到models下的对应项目中。
- VOC数据集格式
由于这种格式算得上是物件检测数据集的鼻祖,并且格式相对简单,因此通用性较高,绝大部分数据集格式都能透过转换工具,转成VOC格式。为了比较贴近实际生活的体验,这里使用一个我们建立的“口罩识别”数据集:
|
1 2 |
# 下载数据集到指定目录,并且解压缩
|
按照VOC数据结构,必须具备以下元素:

- Annotations目录:存放全部的标注文件(*.xml)
- ImageSets/Main:下面主要是2个.txt文件
-
- test.txt:存放“测试”用的文件名(不用附加档名),数量自定,通常建议是整个数据集的20%左右比例,各种类别都需要涵盖。
- trainval.txt:存放“训练&校验”用的文件名列表,约占整个数据集的80%。
- JPEGImages目录:存放全部图片数据(*.jpg、*.jpeg、*.gif等)
- labels.txt:数据集的类别,本范例中只有“Mask”与“No_Mask”两个。
如果有自己建立的其他数据集,例如从其他数据集截取,或者camera-capture工具直接获得的,只要整理成上述的VOC结构,就能被本项目train_ssd.py代码所使用。
- OpenImages数据集格式
这个数据集的标注文件内容可能是目前最复杂的,不过数据内容丰富,能有效利用起来是非常好的。这个项目的作者为OpenImages数据集的部分数据抽取用途,提供一只专门的open_images_downloader.py代码,去下载特定类别的数据集与标注文件。
例如,我们想收集“水果(fruit)”数据并进行训练,这些水果包括“苹果(apple),橘子(orange),香蕉(banana),草莓(Strawberry),葡萄(Grape),梨(Pear),菠萝(Pineapple),西瓜(Watermelon)”这八种,
|
1 |
|
简单说明一下指令的参数:
- --data:数据存放的地方
- --class-names:要下载的类别,这里比较麻烦的是,OpenImages总共有600个类别,可以到https://github.com/dusty-nv/pytorch-ssd/blob/master/open_images_classes.txt 先查清楚想要下载哪些类别
其余比较重要的参数
- --stats-only:加上这个参数,可以“预览”每个类别的图像数量,但还不执行下载。下图显示在train/validation/test三类的图像数量与标注(boxes)数量的统计表。
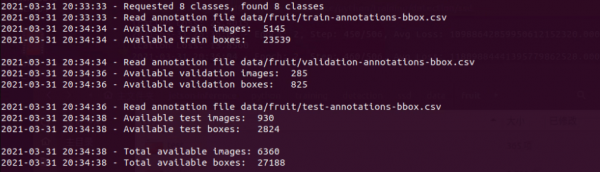
- --max-images:避免太多的数据集下载,可用这个参数限制数量,如果本次下载数据集不做数量限制的话,总共会下载6360张图片与27188个标注信息。
下面列出下载完的数据结构(如下图),里面有test/train/validation三个子目录,将下载的图像分配到这三个目录里面,其中train占80%、test占15%、validation占5%,大约是这样的比例分配。
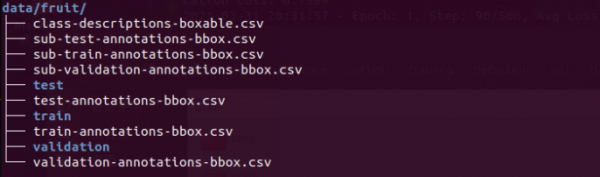
至于另外7个.csv文件中,class-descriptions-boxable.csv存放OpenImages的600种类别,其他6个则包含对应于train/test/validation三种用途的标注数据,内容相当艰涩复杂,这里就不做探索。
Step2:搭配学习功能训练模型
数据集的准备与整理,是整个模型训练中最耗费人力的部分,虽然接下去的部分执行步骤相当简单,不过却是最耗费计算资源的阶段,还好本项目支持Pytorch的迁移学习功能,这为我们节省非常多的计算时间。
train_ssd.py训练代码中已设定好以SSD这个网络模型为基础,提供一个以80类COCO数据集预训练好的mobilenet-v1-ssd-mp-0_675.pth为基础,去训练您的模型,这个模型在一开始的时候已经下载到对应的位置。
接下去我们只要根据“数据集格式”去选择参数,执行训练指令就可以:
|
1
2 |
# 数据集格式:VOC
# 数据集格式:OpenImages(预设值)
|
简单说明一下train_ssd.py的重要参数:
- --data:数据集存放的地方(输入)
- --model-dir:存放生成模型的地方(输出)
- --database-type:数据集种类,支持VOC与OpenImages(预设值)
- --epoch:训练的次数,预设值为30
- --batch-size:预设为4,在Nano(含2GB)上可改成2
每个epoch训练完,都会生成一个对应的xxx-Epoch-n-xxxx.pth文件。这个过程不仅消耗计算资源,而且对内存需求量很大,执行过程如果遇到中途中断,或者“LOSS”出现“nan”时,可能是内存不足所导致,这时候就需要增加SWAP空间,并且关闭图像桌面,将资源留给模型训练。
Step3:将模型文件转换成.onnx格式
这个步骤虽然十分简单,但很重要,因为这是将我们自己训练的模型,能调用TensorRT加速引擎的最便利方法。使用的指令如下,下面以口罩识别项目为例:
|
1 |
|
这里选择的--input通常以训练中Loss数字最小的那个模型文件,将他转换成指定路径的.onnx即可。
Step4:推理识别
这部分使用大家都应该已经很熟悉的detectnet指令,前面应使用内建的网络模型,因此只要指定--network就能得到配套的参数。但是现在不一样的是,要是用我们自己建立的模型文件,因此很多参数都得自己设定,其实也不是太复杂,参考以下的指令:
|
1 |
--labels=models/mask/labels.txt \ --input-blob=input_0 --output-cvg=scores --output-bbox=boxes \ /dev/video0 |
指令中的--input-blod、--output-cvg、--output-bbox这三个参数,依照本范例的值去给定就可以。其他--model、--labels根据实际状况进行调整,最后的/dev/video0也根据实际数据源进行改变。
来源:业界供稿
好文章,需要你的鼓励


Google Health 5.0 正式推出,安卓端新增数据统计小组件
Google Health 5.0作为Fitbit应用的更新版本正式推出。在安卓端,新版本引入了主屏幕快捷访问小组件,取代原有的圆形步数小组件,可显示最多六项健康指标,支持自定义缩放。点击小组件可跳转至完整统计页面,左上角心形图标可快速打开应用,右侧可直达Health Coach功能。此次更新还启用了全新Google Health图标,移除Fitbit品牌标识。安卓版已于5月19日开始推送,5月26日前全面覆盖。

当电脑学会用尺规作图:中国科学院团队让AI真正“画“出几何题
中科院团队发现顶级AI在几何作图上成功率不到6%,推出PAGER系统将精度提升4.1倍,揭示AI能力评估的关键盲点。

奥迪A2 e-tron入门级电动车将为品牌注入新活力
奥迪宣布将推出入门级纯电动车型A2 e-tron,旨在降低豪华电动车的拥有门槛。该车型基于大众最新MEB平台打造,预计提供50kWh、58kWh和79kWh三种电池选项,续航最高可达630公里。目前原型车正在瑞典北部极寒环境及巴伐利亚道路进行测试,重点验证热管理与电池性能。新车预计售价约4万美元,将于今年秋季正式亮相。

浙江大学联手京东研究院:让AI视频训练快6倍的“闪电秘诀“
浙江大学等机构提出Flash-GRPO视频AI训练新方法,通过同时段分组和梯度校正两项创新技术,实现训练速度提升6倍且质量更优。
2021
07/02
15:01
分享
点赞

AI落地深水区的技术账本:软件质量治理如何破解工程化瓶颈
Google Health 5.0 正式推出,安卓端新增数据统计小组件
周中绿色优惠:Juiced Scrambler电动自行车、Lectric XPress2及多款储能产品特惠来袭
NAMUGA机器人视觉业务向"头部"延伸,加速布局高端机器人解决方案
AMD Silo AI与博洛尼亚大学携手开展空间AI合作,聚焦机器人与自动驾驶领域
Remepy混合疗法帕金森治疗方案即将进入三期临床试验
Exa Labs完成2.5亿美元融资,估值达22亿美元
派拉蒙CIO规划AI规模化路径,CTO即将卸任
量子计算面临安全威胁与人才短缺双重挑战
IrisGo:由吴恩达投资的AI桌面智能体,让工作流程自动化成为现实
OpenAI宣称用AI推翻了一个困扰数学界近80年的猜想
Linus Torvalds坦言对AI又爱又恨:工具有用,但挑战真实存在
