
Jetson Nano 2GB 系列文章(22): “Hello AI World”图像分类代码
前一篇文章已经带着大家使用Hello AI World项目的imagenet指令进行了深度学习图像分类的推理识别实验,但这些演示与测试只是个学习的过程,最终的目的还是要能用起这个项目的资源,为自己开发合适的应用代码。因此本文就延续上一篇文章来向大家介绍“Hello AI World”图像分类代码。
选择使用~/jetson-inference/python/examples下面的my-recognition.py这只代码,其“输入源”的部分选择以下函数:
|
8 |
img = jetson.utils.loadImage(opt.filename) |
这部分其实造成了一些不便之处,因为“loadImage()”一次只能读取一张图像,大大降低了这只代码的实用性,因此我们建议选择用/usr/local/bin/imagenet.py这只代码,它能够广泛接受更多样化的输入源,完整地实现imagenet的所有功能。
以下就是/usr/local/bin/imagenet.py 的完整代码,请不要被这33行代码吓到,真正与图像分类推理计算的部分也只有4行,我们在下面会详细说明。
|
1 2
3 4
5
6
7
8
9
10
11
12
13 14 15 16 18 19
20
21 22 23
24
25
26
27
28
29
30
31
32 33 |
import jetson.inference import jetson.utils
import argparse import sys
# parse the command line parser = argparse.ArgumentParser(description="Classify a live camera stream using an image recognition DNN.", formatter_class=argparse.RawTextHelpFormatter, epilog=jetson.inference.imageNet.Usage() + jetson.utils.videoSource.Usage() + jetson.utils.videoOutput.Usage() + jetson.utils.logUsage())
parser.add_argument("input_URI", type=str, default="", nargs='?', help="URI of the input stream") parser.add_argument("output_URI", type=str, default="", nargs='?', help="URI of the output stream") parser.add_argument("--network", type=str, default="googlenet", help="pre-trained model to load (see below for options)") parser.add_argument("--camera", type=str, default="0", help="index of the MIPI CSI camera to use (e.g. CSI camera 0)\nor for VL42 cameras, the /dev/video device to use.\nby default, MIPI CSI camera 0 will be used.") parser.add_argument("--width", type=int, default=1280, help="desired width of camera stream (default is 1280 pixels)") parser.add_argument("--height", type=int, default=720, help="desired height of camera stream (default is 720 pixels)") parser.add_argument('--headless', action='store_true', default=(), help="run without display")
is_headless = ["--headless"] if sys.argv[0].find('console.py') != -1 else [""]
try: opt = parser.parse_known_args()[0] except: print("") parser.print_help() sys.exit(0)
# load the recognition network net = jetson.inference.imageNet(opt.network, sys.argv)
# create video sources & outputs input = jetson.utils.videoSource(opt.input_URI, argv=sys.argv) output = jetson.utils.videoOutput(opt.output_URI, argv=sys.argv+is_headless) font = jetson.utils.cudaFont()
# process frames until the user exits while True: # capture the next image img = input.Capture()
# classify the image class_id, confidence = net.Classify(img)
# find the object description class_desc = net.GetClassDesc(class_id)
# overlay the result on the image font.OverlayText(img, img.width, img.height, "{:05.2f}% {:s}".format(confidence * 100, class_desc), 5, 5, font.White, font.Gray40)
# render the image output.Render(img)
# update the title bar output.SetStatus("{:s} | Network {:.0f} FPS".format(net.GetNetworkName(), net.GetNetworkFPS()))
# print out performance info net.PrintProfilerTimes()
# exit on input/output EOS if not input.IsStreaming() or not output.IsStreaming(): break |
如果将代码区分为以下4部分,就能很容易理解:
- 参数解析:5~19行,请参考前面文章关于参数解析的部分,可忽略
- 输入输出:21、22、25、29、30等5行,与videoSource、videoOutput有关
- 文字叠加:23与28行是为了将显示结果,用文字叠加到图像上
- 图像分类:20、26、27行,以及30行的net.GetNetworkFPS()部分
现在我们主要解说与“图像分类”有关的这4行代码:
- 第20行:net = jetson.inference.imageNet(opt.network, sys.argv)
用jetson.inference深度学习模块的imageNet()图像分类函数,来建立net这个对象,现在这个net对象就具备了“图像分类”的属性
- 第26行:class_id, confidence = net.Classify(img)
img是从25行的input.Capture()获取的一帧图像,将img传入net.Classify进行图像分类的检测,将“置信度最高”的分类编号传回给class_id变量、将置信度值传回给confidence变量。
这里要说明的,在执行Classify(img)的过程,可能会检测出非常多的“可能性”,但最终回传“置信度最高”一个类别。当我们后面执行检测时,会看到终端上打印出类似下图的信息:
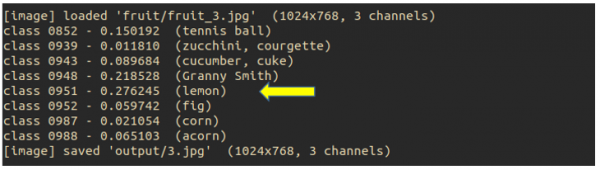
在本帧图像进行分类识别时,会出现8种可能性,但最后回传置信度最高的分类编号(0951)给class_id、置信度(0.276245)给confidence。
下面比对一下检测结果的输出图像,如下图:
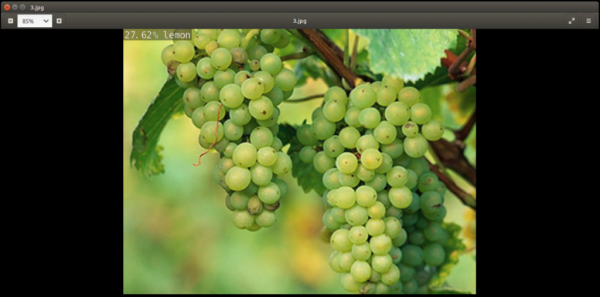
这里可以确认,回传的值只有一组,就是“置信度最高”的,不管这个置信度数值有多低。
虽然在上面的终端中已经显示出了这个类别编号的名称,但实际上这个函数回传的值就只有两个,因此我们自己还需要用下一行的代码,来找出类别编号所对应的名称与描述。
- 第27行:class_desc = net.GetClassDesc(class_id)
这行的目的,是用类别编号class_id去找到对应的类别名称与描述,语法非常直观,不多做解释。重要的是这个类别名称与描述的内容,存放在哪个文件里面。
从上一篇文章中,知道这个代码预设使用的网络模型为GOOGLENET,使用的数据集是ImageNet的1000分类数据集,这个在系统里面对应的类别名称与描述文件,在~/jetson-inference/data/networks/ilsvrc12_synset_words.txt里面,用文字编辑器打开后,看看第951行(如下图)是什么内容?

很不幸的,951行出现的是“orange”,而“lemon”出现在第952行,这个差异主要是因为类别编号是从“0”开始,而编辑器的行数是从“1”开始,所以中间会有这样的差距,现在知道之后就很简单了。
- 第30行: net.GetNetworkFPS()
这部分显示识别性能,其实是对图像分类的应用,是无关紧要的,不过这个项目其实也是很神奇的,过去我们自己用OpenCV撰写性能标识的代码,其实还挺繁琐的,但是在jetson-inference项目中,无论是图像分类,还是后面要说明的物件识别、语义分割等应用,用这个GetNetworkFPS()函数就轻松得到计算的性能,真是不能再方便了!
看完之后就会发现,其实整个代码中的关键,就是在一开始用imageNet()函数去建立图像分类的对象,然后将读入的图像传给Classify()函数进行分类的推理计算,这两个步骤几乎就完成了90%的工作了。
相信有了这样的解说会让您更清楚该如何使用jetson.inference这个深度学习的模块,去开发您自己的图像分类应用。
来源:业界供稿
好文章,需要你的鼓励


Flytrex无人机携手达美乐,可一次性送达两个大号披萨
无人机食品配送服务商Flytrex与全球知名披萨连锁品牌Little Caesars宣布合作,推出全新Sky2无人机,最大载重达4公斤,可一次配送两个大披萨及饮料,满足全家用餐需求。Sky2支持最远6.4公里的配送范围,平均从起飞到送达仅需4.5分钟。首个试点门店已在德克萨斯州怀利市上线,并实现与Little Caesars订单系统的直接集成。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

欧洲最大3D打印公寓楼提前数月竣工
法国社会住房项目ViliaSprint?已正式完工,成为欧洲最大的3D打印多户住宅建筑,共12套公寓,建筑面积800平方米。项目由PERI 3D Construction使用COBOD BOD2打印机完成,整体工期较传统建造缩短3个月,实际打印仅用34天(原计划50天),现场操作人员从6人减至3人,建筑废料率从10%降至5%。建筑采用可打印混凝土,集成光伏板及热泵系统,能源自给率约达60%。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2021
06/01
09:48
分享
点赞

欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
Synetic在2026嵌入式视觉峰会上发布LYNX计算机视觉SDK
生数科技发布世界动作模型Motubrain,为机器人智能带来"无限可能"
