
NVIDIA Jetson Nano 2GB 系列文章(7):通过 OpenCV 调用 CSI/USB 摄像头
在本系列上一篇文章里,我们为大家介绍了 Jetson Nano 2GB 安装 CSI 摄像头的方法,以及最基础的启动指令。在本篇文章中,我们将向大家展示如何通过 OpenCV 调用 CSI/USB 摄像头。
本期我们会带着大家使用这个摄像头,执行一些很实用的图像处理(image processing)应用,至于计算机视觉(computer vision)的应用,将在下一期里带着大家一起操作。
什么是图像处理?什么又是计算机视觉?如果您有所混淆的话,这里先做个基本说明,二者之间的区隔还是很明显的:
图像处理:输入为图像,输出也是图像
过程中对于图形进行一些应用处理,例如颜色空间(color space)转换、图像格式转换、尺寸转换、角度转换、图像合成等操作,最基本的就是将摄像头的图像读入,显示在屏幕上,并写入磁盘,这就形成一个最简单的录像功能。
计算机视觉:输入为图像,输出为信息
在输入的图像/视频中,找到特定信息的技术,例如基于颜色的追踪、物体边缘的检测、将图像的像素转成信号直方图(histogram)等计算,甚至于车道查找(lane finding)、人脸检测(face detection)等,都属于计算机视觉的范畴,其输入为一张图像,但输出的是某类从图像中淬炼出来的信息。
在 Jetson Nano 2GB 搭建的 JetPack 4.4.1 版本里,内建 OpenCV 4.1.1 版本的开发环境,这是目前图像处理、计算机视觉领域使用率最高的开发工具,因此我们就用 OpenCV 搭配 CSI 摄像头来做图像处理项目。
这里使用 Jetson Nano 2GB 的自带的 gedit 全文编辑器来撰写代码,编程语言使用 Jetson Nano 2GB 预安装的 Python 3.6 版本,由于相关所需的开发环境都已经由 JetPack 4.4.1 完整提供,因此不需要再执行额外的安装,非常简便。
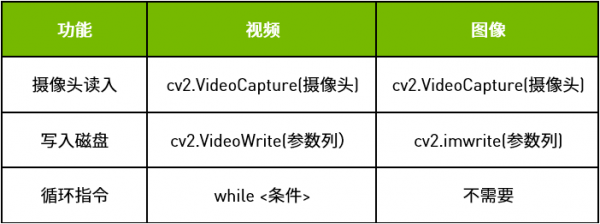
我们可以将视频数据认知为由连续的图像所组合,因此在这里全部以视频处理作为示范,比较动态。至于图像的处理方式,请自行调整代码,二者之间的差异主要在写入磁盘以及是否需要循环指令的部分,如下表:
实现摄像头录像功能
这个功能主要执行三个动作:
-
从摄像头读入图像
-
给定文件名
-
写入磁盘中
这些动作在 OpenCV 都有非常简单的对应指令可以操作,详细代码如下:

本代码以“ESC”键结束录像。

将读入的图像执行缩放
这个功能主要执行三个动作:
-
摄像头读入图像
-
调用 cv2.resize 函数进行图像尺寸改变,选择插值方式(cv2.INTER_NEAREST)
-
在屏幕上显示
完整代码如下:

本代码以“ESC”键结束录像。

将读入的图像执行旋转
这个功能主要执行 4 个动作:
-
从摄像头读入图像
-
找出图像中心点
-
调用 cv2.getRotationMatrix2D() 函数进行旋转
-
显示:本范例显示 90 度/ 180 度/ 270 度
详细代码如下:

本代码以“ESC”键结束录像。

本文介绍了 3 种在 Jetson Nano 2GB 上,结合 CSI 摄像头与 OpenCV 做的很实用的图像处理应用,应该很容易上手。后面将为您介绍几个常用的计算机视觉应用情况。
来源:英伟达
好文章,需要你的鼓励


人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
英特尔携手戴尔以及零克云,通过打造“工作站-AI PC-云端”的协同生态,大幅缩短AI部署流程,助力企业快速实现从想法验证到规模化落地。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2021
03/17
16:56
分享
点赞

《2025 中国企业级 AI 实践调研分析年度报告》:深度剖析与价值洞察
Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
Infinidat G4系列升级重新定义高端企业存储格局
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
