
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官! 原创

当具身智能以灵活的姿态
融入人类日常生产生活
当创作打破媒介的局限
孪生出卓越的视觉美学
当生物医疗突破技术的壁垒
为生命编织独特的基因序列
......
这些创新与突破
正重新定义 AI 时代的边界。
在新工业革命的浪潮中
我们见证
每一位创业者的创新历程
是他们在未知的前方
铺设出希望的轨道
推动着新工业革命的列车
飞驰向前
仅以此文回顾与致敬参与
2024 NVIDIA 创业企业展示活动
的每一位创业先锋!
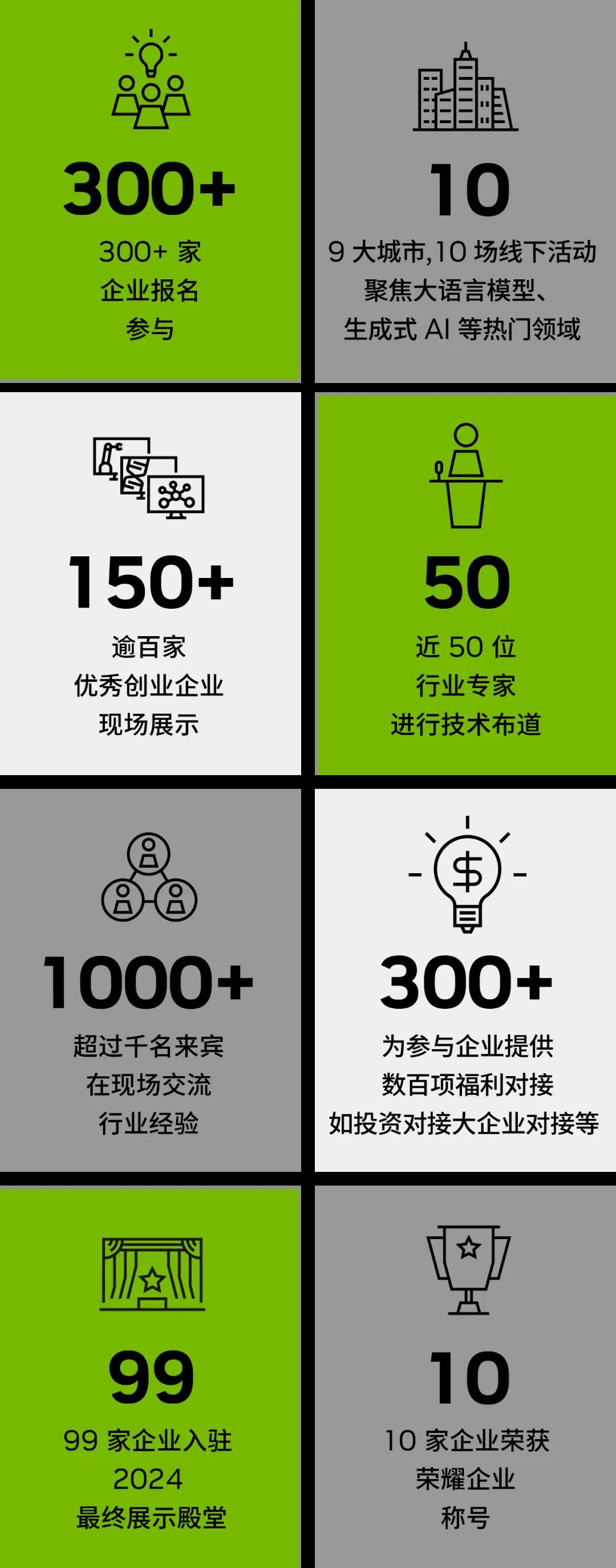
让我们一起回顾,
新工业革命列车驶过的每一站
华南区
香港站
香港站是 2024 NVIDIA 创业企业展示区域展示的第一站,香港站聚焦生成式 AI、医疗健康等领域。活动上,12 家创业企业进行路演展示,32 家企业在现场进行了展位展示,并有 20 多家来自大企业及创投机构的代表与在场企业进行了深入的交流。现场圆桌论坛环节,在场嘉宾围绕科技赋能医疗与生命科学主题,深入探讨发展路径,并提出了富有前瞻性的洞察与建议。

深圳站
深圳站聚焦大语言模型技术、机器人与具身智能等前沿方向。12 家创业企业进行了精彩路演,34 家企业在现场进行了展位展示, 50 余家投资机构与企业进行了深入交流。活动现场,NVIDIA 专家分享了大语言模型与具身智能的前沿技术, 在场嘉宾围绕 AI 创业企业在香港的出海优势以及“机器人与具身智能行业”主题进行了深度讨论。

华东区
上海站
上海站聚焦生命科学、工业控制、ACG、生成式 AI、AI Agent(AI 智能体)、数字人、数据标注、RAG 等前沿话题,15 家创业企业进行现场路演,13 家企业在现场进行了展位展示,68 家来自大企业及创投机构的代表与在场企业进行了深入交流。活动现场,NVIDIA 技术专家聚焦大模型、生成式 AI 展开技术分享,帮助企业探索更多创新机会。

杭州站
杭州站聚焦生成式 AI、AR 硬件、数据智能等技术领域,以及电商营销、工业制造等行业应用前沿话题,10 家创业企业在当天进行了路演展示,多家大企业及创投机构的代表与在场企业进行了深入交流。

南京站
南京站聚焦生成式 AI 在游戏、零售、交通物流等行业的创新应用。共有 7 家企业进行了路演展示。NVIDIA 携手合作伙伴专家介绍了大模型 AI 技术在工业、医疗、金融等多个领域的应用情况。

北区
北京站
北京站活动汇聚了 9 家来自生成式 AI、自动驾驶、生命科学等领域的创业公司进行路演展示。技术专家分享了AI 的多行业应用,重点介绍了 NVIDIA NIM 推理微服务和 NVIDIA Omniverse 平台。多款具备跑跳、互动、咖啡制作等功能的机器人方案亮相展区。

北京站(数字孪生&传媒娱乐)专场
北京站(数字孪生&传媒娱乐)专场聚焦大语言模型、物理 AI、智慧工厂、机器人、数字化内容创新等技术领域与行业应用。10 家创业企业在当天进行了路演展示,6 家企业在现场进行了展位展示。活动特别聚焦“AI 助力影视和娱乐行业创新”等话题开展圆桌论坛,从 AI 在影视和娱乐行业场景落地的突破与挑战、技术赋能、发展趋势等角度分享展望了当前和未来的演进方向。

中西部地区
银川站
银川站共有 13 家企业在现场进行了路演展示,NVIDIA 携手多位合作伙伴专家深入剖析了 AI 在各领域的应用场景,包括高性能存储加速 AI 大模型训练、生成式 AI 的优化部署,以及 AI 在科学研究和工业发展的推动作用。并将通过更多的活动交流,携手推动中西部 AI 创新生态建设。

成都站
成都站聚焦大语言模型/生成式 AI、数字孪生、传媒娱乐行业创新,以及 AI 全球化方向。NVIDIA 携手多位合作伙伴专家充分展示了 AI 助力中国创业企业全球化方面的战略实施路径与成功模式。现场 11 家创业企业进行了精彩路演。

半程展示
半程展示聚焦大语言模型、生成式 AI、医疗健康、自动驾驶、机器人等方向。31 家会员企业以分组路演的形式展示了其创新能力和成果。活动中开展了 SheTech 论坛,三位卓越的女性管理者分享了女性在科技领域的独特力量与非凡成就,共话新工业革命下的“她力量”。

最终展示
12 月 10 日
10 家 “荣耀企业”
亮相线上最终展示活动
为 2024 NVIDIA 创业企业展示
画上了完美的句号
从华东到华南
从中西部到北京
经过 5 个月征途
在最终展示的主舞台上
我们终于迎来
10 家“荣耀企业”的身影
他们分别是
爱动超越
阿丘科技
DataMesh
米粿 AI
镁伽科技
深涌智能
元始智能
智臾科技
逐际动力
Taikangnuo Biotechnology Limited
(以上企业排名不分先后)
每一家创业企业
都期待通过 AI 技术创新推动传统行业变革
面对未来对企业的展望
他们这样说.....










让我们翘首期待
他们开启新工业革命的时代进程
历经 8 年时光
NVIDIA 创业企业展示
也将持续坚守支持
我们明年再见!

来源:至顶网计算频道
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
