
Nvidia与NetApp合作打造深度学习GPU服务器芯片
NetApp和Nvidia已经推出了一个组合式的AI参考架构系统,与Pure Storage和Nvidia 合作的AIRI系统相竞争。
这款系统主要针对深度学习,与FlexPod(思科和NetApp合作的融合基础设施)不同,这款系统没有品牌名称。而且与AIRI不同的是,它也没有自己的机箱封装。
NetApp和Nvidia技术白皮书《针对实际深度学习用例的可扩展AI基础设施设计》定义了一个针对NetApp A800全闪存存储阵列和Nvidia DGX-1 GPU服务器系统的参考架构(RA)。此外还有一个速度慢一些的,成本更低的、基于A700阵列的参考架构。
高配的参考架构支持单个A800阵列(高可用性配对配置),5个DGX-1 GPU服务器,连接2个思科Nexus 100GbitE交换机。速度较慢的A700全闪存阵列参考架构支持4个DGX-1和40GbitE。
A800系统通过100GbitE链路连接到DGX-1,支持RDMA作为集群互连。A800可横向扩展为24节点集群和74.8PB容量。
据说A800系统可实现25GB /秒的读取带宽和低于500微秒的延迟。
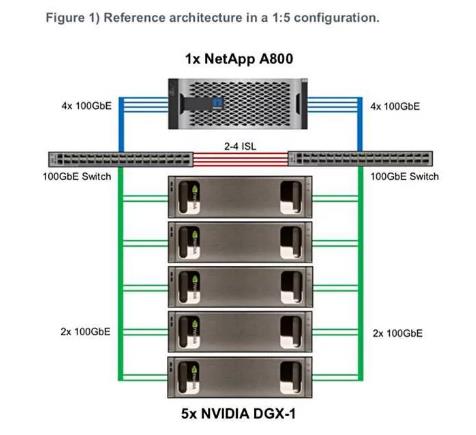
NetApp Nvidia DL参考架构配置图
Pure Storage和Nvidia的AIRI有一个FlashBlade阵列,支持4个DGX-1。FlashBlade阵列提供17GB /秒的速度,低于3毫秒的延迟。这与NetApp和Nvidia合作的参考架构系统相比似乎较慢,但A800是NetApp最快的全闪存阵列,而Pure的FlashBlade则更多地是一款容量优化型闪存阵列。
和Pure AIRI Mini一样,NetApp Nvidia DL RA可以从1个DGX-1起步,扩展到5个。 A800的原始容量通常为364.8TB,Pure的AIRI原始闪存容量为533TB。
AIRI RA配置图如下所示:
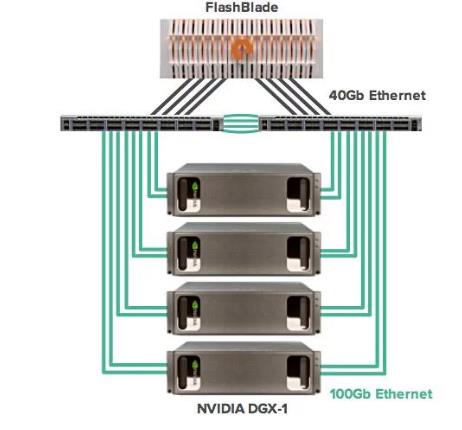
Pure Nvidia AIRI配置图
NetApp和Pure都对他们的这两个系统进行了基准测试,并且都包含Res-152和ResNet-50运行使用合成数据、NFS和64批量大小。
NetApp提供了图表和数据,而Pure只提供图表,所以对比起来有点困难。不过,我们可以通过将这些图表放在一起做个粗略的估计。
合成的总图表并不漂亮,不过确实提供了一些对比:

NetApp和Pure Resnet性能对比
至少从这些图表可以看出,NetApp Nvidia RA的性能优于AIRI,但让我们吃惊的是,由于NetApp/Nvidia DL系统与Pure AIRI系统相比具有更高的带宽和更低的延迟,分别是25GB/s的读取带宽和低于500微秒以下,后者分别17GB/s和低于3毫秒。
价格对比很好,但没有人透露给我们这方面的数据。我们猜测Nvidia可能会宣布更多深度学习方面的合作伙伴关系,就像NetApp和Pure这样的。HPE和IBM都是很明显的候选对象,还有像Apeiron、E8和Excelero等NVMe-oF这样的新兴阵列初创公司。
好文章,需要你的鼓励


据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
当超级计算机被压缩进一个比书本还小的盒子里,这画面有多炸裂?想象一下,你桌面上摆着的不是什么花瓶摆件,而是一台能跑200B参数AI推理的"超算怪兽"——这就是我们今天要聊的主角:华硕Ascent GX10。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的“稀疏化魔法“
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。


不用再训练AI模型,香港科技大学团队发明“智能管家“,让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。
2018
06/07
07:35
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
苹果发现:只需一个注意力层,就能让AI图像生成既快又好
YouTube推出基于Gemini 3的创作者游戏制作工具
英伟达是唯一能负担免费提供AI模型的厂商
OpenAI发布新旗舰图像生成AI模型GPT Image 1.5
脑启发算法可大幅降低AI能耗
Mac办公桌升级必备配件指南:提升工作效率的最佳选择
PTC Windchill+ 助力 HOLON研发全球首批符合汽车行业标准的 L4 级电动汽车
航旅行业的AI“乘法效应”:迈向指数级进化
OpenAI推出GPT Image 1.5模型加速图像生成竞争
Zoom推出AI Companion 3.0智能体工作流程
ChatGPT成为互联网最受阻止的爬虫机器人
