
你敢要它就有!至强6新品治好选择困难症
2月下旬,英特尔新一代数据中心处理器至强6大家族迎来了第三波的新品发布,主要包括代号Granite Rapids-SP的至强6700/6500性能核处理器,以及代号Granite Rapids-D的至强6系统级芯片(SoC)。
至强6700/6500系列性能核处理器上市,意味着至强6性能核产品阵容终于“补全”,覆盖从8至128核,得以更好地衔接第四代/第五代至强可扩展处理器产品线,与去年发布的至强6700系列能效核处理器形成清晰的分工。

至强6全家福
由于至强6产品家族旗下型号多,且发布时间跨度较长,定位差异也很大,我们先简要回顾至强6家族已经上市的产品线。
2024年6月,至强6首次亮相,发布的是代号为Sierra Forest-SP的至强6700能效核处理器。该系列的计算单元采用英特尔3制造工艺,提供了144个能效核,主要针对高密度、横向扩展工作负载,如云原生、CDN、微服务等,在为这类应用带来性能改善的同时,能效也有更为明显的提升。至强6700系列能效核处理器最大功耗350瓦,采用Socket E2接口(LGA 4710),支持8通道DDR5 6400MT/s,88个PCIe 5.0通道及64个CXL 2.0通道。
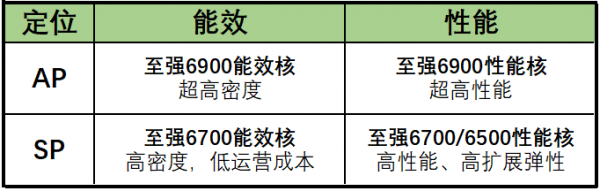
2024年9月发布的至强6900系列性能核处理器代号Granite Rapids-AP,定位为旗舰级,适合要求严苛的云、科学计算、AI(机头)等领域,可以在同样的空间内部署更多的性能核(单插槽可以达到128个性能核)、提供更大的内存带宽(12通道内存,并支持MRDIMM 8800MT/s)、更多的PCIe 5.0通道(96个)或CXL 2.0通道(64个),以及6个UPI2.0链路。相应的,至强6900系列性能核处理器需要使用更大面积的接口Socket BR(LGA 7529),最大功耗也增加到500瓦。其新的性能核前端设计有较大改进,在翻倍的内核数量和内存带宽加持下,性能表现是至强6整个家族中的佼佼者,在很多主流应用负载上的性能表现都能达到上一代产品的2-3倍。

今年2月发布的至强6700/6500系列性能核处理器代号Granite Rapids-SP,集成了8到86个性能核,平均每核分配的末级缓存多数都在4MB以上,完整支持AMX指令集,DSA、QAT、IAA和DLB等加速器也都开启。至强6700/6500性能核处理器使用与至强6700能效核处理器相同的接口和功耗上限,PCIe、CXL扩展能力相同,支持8通道DDR5 6400MT/s,部分型号还提供了MRDIMM 8000MT/s的支持能力。该系列的市场定位更偏向主流的数据中心、电信基础设施,以及企业级服务器和边缘场景。
在此,我们先做一个小结:至强6家族规划了AP与SP,以及性能核与能效核的微架构,由此交叉构成多个产品大类:AP+性能核对应至强6900性能核产品线(最高128核),负责提供这代产品目前最强性能输出水平(内核数和内存通道),PCIe和CXL扩展能力也要更强一些,使用面积更大的封装和插座。至强6900性能核的6个UPI2.0链路全部用于双路互联,可以充分提升跨处理器的访问带宽以尽可能提高性能,但不考虑用于构建多路系统。SP+能效核及性能核,对应的产品线则分别为至强6700能效核(最高144核)与至强6700/6500性能核产品线(最高86核),更多是用于主流服务器机型的升级换代,封装尺寸与前几代至强保持一致。
应用新主流:生成式AI、结构化数据
至强6700/6500系列性能核处理器与已经发布半年多的至强6700系列能效核处理器可以使用相同的服务器平台,因此在发布后可以迅速进入市场。由于过去一年AI需求高涨,业内一直期待性能核与能效核处理器能够尽快形成清晰明确的分工,以完整覆盖主流市场各种类型业务的需求:传统业务需要降本增效,新兴业务需要提质增量。
传统业务混合AI负载
在大模型蔚为风潮的背景下,至强6性能核拥有更多的内核、较大的内存带宽,以及AMX这类为AI任务优化的加速器,不论是传统的神经网络推理,还是Transformer大语言模型推理的性能都相较上一代至强处理器有大幅提升。主流的200亿参数以下的中、小规模的模型在至强6上都可以顺畅运行,再得益于至强本身在通用计算领域的竞争力和积累,就使得至强6700性能核非常适合混合部署AI业务的用户。譬如在互联网行业中已经验证成熟的推广搜(广告、推荐、搜索),企业应用中渗透率很高的自然语言处理,正在蓬勃发展的智能客服、知识助理等大模型私有部署等。这些业务都可以与传统业务部署在同一个节点、同一个资源池当中。
生成式AI
如果说至强6900性能核是AI训练的最佳机头,那么至强6700/6500系列性能核也有望成为AI推理的优秀机头,搭配GPU或其他AI专用加速器运行以生成式AI为代表的,大参数、高并发的大语言模型推理任务。
上一小节中提到了至强6性能核自身核心性能、内存带宽的优势。在至强6700/6500系列性能核上,还比较容易获得内存容量的优势。基于传统布局,双路至强6700/6500系列性能核机型依旧可以轻松提供32条内存插槽,可以较低成本部署2~4TB本地内存,上限可以达到8TB。部分型号还可以享受MRDIMM 8000MT/s提供的更高带宽。除了充裕的内存容量和带宽,充足的PCIe 5.0通道数有利于配置多块AI加速器和高性能网卡。至强6700/6500系列的双路节点可以提供176条PCIe 5.0通道,单路节点可提供136条。这使得在4U机箱内部署8卡不再需要依赖PCIe Switch板,在液冷的支持下部署更高的密度也依然游刃有余。
随着以KTransformer为代表的开源大语言模型推理优化框架的出现,利用MoE架构稀疏性的特点在CPU和GPU上实现异构分层部署推理任务逐渐引起重视。这种异构协同的方案可以充分利用算力、存储资源,大幅降低部署门槛,显著提升推理速度。这种模式也能让至强6处理器的计算性能、内存优势及AMX加速能力获得更大的发挥空间。而且至强6性能核产品线中的DSA、QAT、DLB、IAA等加速器也全都默认开放,让数据流的预处理、节点间交互的效率更高。尤其是6700性能核的高性能产品线当中,4种加速器都各提供4个,能助力CPU卸载加密、压缩、数据传输和转换等任务。这些特性有利于改善节点内南北向、东西向数据传输中的消耗,在构建高并行、多节点的AI集群时可进一步提升效率。
至强处理器在可信或隐私计算方面较为独到的技术特性,也在这次至强6700/6500系列性能核发布时得到了进一步增强。其从第四代至强可扩展处理器开始集成的TDX(Trust Domain Extensions)技术,原本可基于硬件的可信执行环境部署信任域(TD)让敏感数据和应用程序获得虚拟机/容器级别的隔离,免受未经授权的访问。这次也随新品将机密计算的覆盖范围进一步增强,通过新增的TDX Connect,可在CPU和PCIe设备之间实现高性能的加密连接,这可以更好地保护加载于主内存、CPU、加速卡全链路中的数据。TDX Connect对于需要租赁弹性算力部署私有AI业务的用户而言是一个非常重要的保障,毕竟在算力平权的时代,自有数据和微调的垂直模型才是企业核心竞争力的有力保障。
向量数据库
生成式AI带动了业内对向量数据库的关注。由于大语言模型的知识是在训练和微调时固化的,遇到“超纲”的问题时,模型可能会拒绝回答或胡说八道。通过检索增强生成(RAG)让模型可以检索外部数据获取更多的信息以补充其知识盲区。对于私有化部署大语言模型的企业而言,必须通过微调强化模型在特定领域的专业度,并建议搭配向量数据库以实现RAG,可以充分利用私有信息并不断更新。简单说,参数规模决定了大语言模型的智力水平,向量数据库决定了大语言模型的专业度、可信度,以及可持续发展。
向量数据库与传统的以行或列组织信息的数据库不同,其使用数据的高维度嵌入作为信息单元,并基于嵌入进行相似性检索。因此在构建向量数据库时需要通过模型对筛选、收集的文档进行提取、格式化、切分。结构化数据库的向量操作非常适合使用至强6性能核进行处理。单路的至强6性能核的典型应用场景是全闪存储节点,在此基础上部署向量数据库能进一步发挥处理器的性能特点:适宜的处理能力和丰富的扩展性。
内存数据库
相较于至强6900性能核处理器和6700能效核处理器,至强6700/6500系列性能核处理器还拥有一个关键的特点,它们传承了英特尔在x86市场的独门绝技:可以原生扩展至4路和8路,这意味着单台服务器通过八路配置即可提供688个性能核以及32TB本地DDR5内存,尤其适合用于大型内存数据库以及科学计算集群的胖节点等。以SAP HANA为代表的大型内存数据库为联机事物处理(OLTP)等关键业务提供了有力支撑,将尽可能多的数据放置在内存当中有利于提高并发事务吞吐量、加快决策速度。
另外,根据以往的经验,顶尖的服务器厂商还会通过节点控制器进一步拓展处理器数量和内存容量。不过在至强6性能核上还有更简单的内存扩展方式——CXL2.0内存。至强6性能核独有的CXL平面内存模式(Flat Memory Mode)可以平滑地扩展内存容量和带宽,不需要操作系统内核或部署专用的软件支持。平面内存模式与本地内存的配置比例是1:1,理论上可以将服务器的内存容量翻倍,或者允许使用相对更便宜的基于DDR4的CXL内存。以配置32TB内存为例,如果完全使用本地内存,必须使用单条128GB的DDR5 RDIMM,价格比较昂贵;而搭配CXL内存,本地内存就可以使用更为常见64GB DDR5 RDIMM,从而有效降低整体成本,总带宽还有所提升。
产品阵容进一步解析
至强6700/6500性能核处理器规划了非常绵密和多样的产品线,内核数量从8核至86核,UPI数量和启用的加速器数量也有所差别。为了构成如此多样的规格,英特尔设计了三种类型的封装形态:XCC、HCC、LCC。
- XCC:拥有两个计算单元(Compute Tile)和两个IO单元(IO Tile),分别由Intel 3和Intel 7工艺制造。XCC所使用计算单元与组成至强6900性能核的UCC相同,都是单芯片44个内核、4通道内存控制器,区别是UCC使用了3个计算单元。XCC的两个计算单元提供最多86个内核。
- HCC:一个计算单元和两个IO单元。HCC的计算单元提供最多48个核心,以及8通道内存控制器。HCC没有考虑对MRDIMM的支持。
- LCC:一个16核心的计算单元和两个IO单元,不支持MRDIMM。使用LCC的处理器UPI链接数只有3,这可能与其计算单元和IO单元之间的EMIB连接较少有关。

从产品定位角度看,至强6700/6500性能核处理器可以进一步细分为高性能、主流、多路、单路等产品线。
高性能产品线
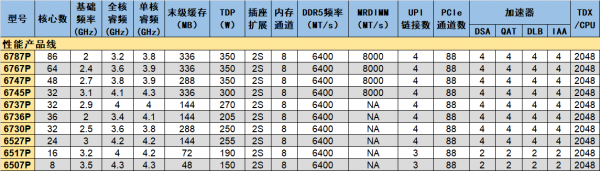
高性能产品线提供了最多86核的型号(6787P),多数型号的加速器全部打开。至强6的每个IO单元提供2个加速器模块,每个模块有DSA、QAT、DLB、IAA各1。两个IO单元就是4种加速器各4个。基于LCC的6517P 和 6507P提供的加速器是各两个。
高性能产品线涵盖了XCC、HCC、LCC三种封装,因此内核数量、内存支持、功耗的差异也很大。其中,以第三位数字为界,674xP以上的4款均是XCC,内核数量最多86,LCC末级缓存最多336MB,均支持MRDIMM 8000MT/s。这里有一个特例是6730P,它也基于XCC,提供了288MB末级缓存,但不支持MRDIMM。
其中,6745P以32核享受了多达336MB的末级缓存,平均每核缓存超过10MB!它的频率也较高,基础频率超过3GHz,全核睿频可以达到4.1GHz,单核4.3GHz。这种核少、高频、大缓存的SKU更适合追求低内存延迟、高处理压力的任务,譬如大数据分析、科学计算等。而核数更多的型号则更适合高并行性的任务。
6527P、6736P、6737P这几个SKU使用的HCC封装,提供16到36核的配置。HCC理论上最多48核,提供192MB末级缓存。6737P只使用了其中的32核,但享用了全部末级缓存,因此其定位略高于核数略多的6736P(36核)。
6507和6517P使用LCC封装,核数少,基础频率高,可以达到3.2GHz以上,睿频可以达到4.3GHz,而功耗不到200瓦。LCC给每个性能核准备了4.5~6MB的末级缓存,要多于其他系列的原生设计。高频率、大缓存有都利于在核数相对较少的情况下提升性能。
主流产品线
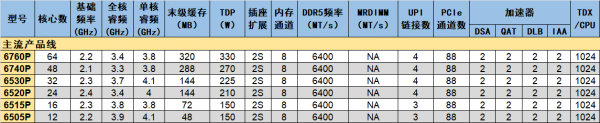
主流产品线的核数跨度在12个到64个之间,显然也使用了三种版本的内核封装。其中两款67x0P使用XCC,却没有开放MRDIMM的支持。不过好在二者的末级缓存都较大,平均每核心的缓存容量达到至少5MB。相比高性能产品线,主流产品线的加速器只开放了一半,分别只有2个,每CPU的TDX数量也减半了。
这一组产品的型号非常直观,第三位数字可以与实际内核数挂钩。譬如6760P的第三位是6,核数是64;6520P的2对应24核。唯一的特例是6505P,它不是8核而是12核。
多路产品线
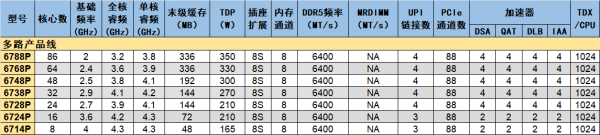
多路产品线是为4路、8路服务器准备的,售价较高,均被列入67xxP序列。该产品线的型号也比较容易理解,第三位数字大致对应了核数多寡;第四位数字是8或4,清晰体现了其原生的UPI直连多路支持能力。譬如6724P和6714P基于LCC,每个插槽有3个UPI链接,正好可以分别直连其他3个插座以构成全连接的4路系统,或通过节点控制器实现8路。其余尾数为8的处理器都有4个UPI,可以构成典型的8路系统。
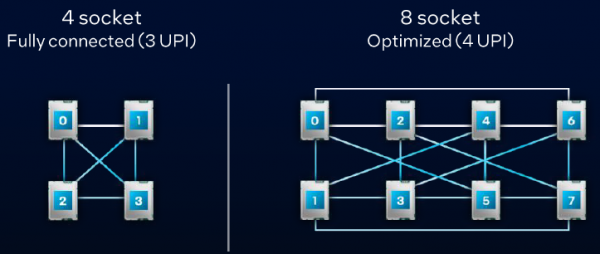
这些面向多路的产品都不支持MRDIMM,即使是其中两款基于XCC也是如此。其实对于多路系统而言,相邻任意两个处理器之间顶多只有一条UPI链接,跨插座的内存访问带宽远低于双路产品线——作为对比,双路旗舰6900性能核系列会使用全部6个UPI互联。因此,多路系统全局访问内存的瓶颈在于UPI的带宽,很难发挥MRDIMM的带宽优势,暂时也就没有启用的必要。长远看,由于MRDIMM有单条内存容量翻倍的潜力,未来的多路系统还是会择机引入MDRIMM的。
多路产品线中超过16核的SKU都开放了全部的加速器。6748P是已公开的至强6产品线中,唯一使用了“满血”HCC的SKU,提供48核和192MB末级缓存。
8核的6714P和16核的6724P基于LCC打造,它俩的核数较少,但设定了比高性能产品线的6507P和6517P更高的功耗和频率。实际上,6714P和6724P是整个至强6家族当中频率最高的SKU,基础频率甚至达到了4GHz,不论是之前提到的高性能产品线还是后面要提到的单路产品线都没有达到这个水平。高频也是它们虽然基于LCC,但依旧可以冠以67xxP之名的原因之一。这样的规格虽不适合高并发的处理,但优势在于响应速度更快,在配合某些根据内核数收取授权费的软件使用时也可以适当降低成本。
单路产品线
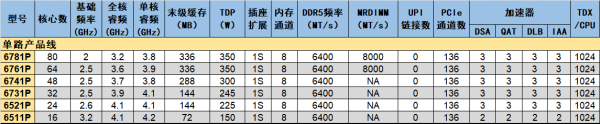
至强6700和6500性能核的单路产品线所有产品名称的第四位数字均为1,第三位数字与核数的对应关系也最为“整齐”,核数均为8的整倍数,没有特例。单路处理器不需要使用UPI互联,因此IO单元中原本可用作UPI x24的几个UIO可被用作x16的PCIe或CXL通道。最终它们的PCIe通道数比双路“同胞”们多了48个,达到136个。
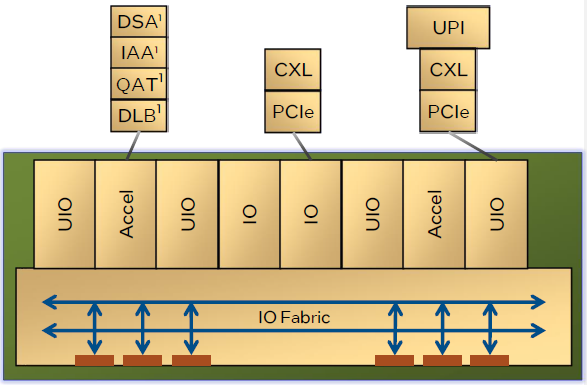
(图注:性能核处理器的IO单元功能模块)
单路至强6性能核处理器的加速器数量大多为3组,介于性能(4组)和主流(2组)产品线之间。80和64核的单路处理器支持MRDIMM 8000MT/s,但同样使用XCC的48核6741P却不支持MRDIMM。
由于当前处理器的内核数量已经足够的多,专门规划单路至强可以控制成本,或用于提升机箱内扩展设备的部署密度。以全闪存储节点为例,如果2U前窗提供24个U.2 NVMe盘位,不依赖PCIe Switch或扩展卡的话,需要96个NVMe通道。单路至强6性能核满足NVMe SSD后,还有40个PCIe 5.0通道,可分配给两块100/200G IB网卡服务存储集群,还有1块OCP网卡做管理。对于并行度较高的业务,譬如云、轻量级推理、视频转码等,如果在原本双路机箱内部署两个单路节点,在内核数相同的前提下,可以挂载更多的PCIe设备用于推理、转码、存储等。
至强6系统级芯片、至强6300
在至强6700/6500性能核发布同期,英特尔也正式推出了至强6系统级芯片与至强6300,在这里我们对二者也顺便做一些简要介绍。
至强6系统级芯片的计算单元与XCC、HCC、LCC是通用的,但搭配了一个重新设计的IO单元。这个IO单元取消了UIO,减少了IO模块,仅支持较少、较低规格的PCIe和CXL,主要面积用于提供2×100Gbps以太网、媒体加速器、vRAN加速器等。这也从另一个角度体现了至强6产品家族将计算单元和IO单元解耦的意义。通过调整IO单元的规格,配置不同的扩展能力、多样化的加速器,可以更好地适配更丰富的细分场景。

至强6系统级芯片将通用计算、AI推理、媒体编码、以太网等功能整合在单一封装内,主要部署于边缘侧,如网络安全加速器、媒体服务器、5G虚拟基站等。目前已经公开规格的至强6系统级芯片最多42核(6726P-B),使用BGA4368封装,TDP最高235瓦,支持4通道DDR5 6400MT/S。英特尔也透露了72核的存在,后续还会陆续发布。
至强6300系列定位于入门级服务器,采用的内核是Raptor Lake,提供8个核心,支持双通道DDR5 4800MT/s ECC UDIMM。Raptor Lake就是13代酷睿处理器中的性能核,只是用在至强产品线当中时没有再用酷睿那种性能核与能效核并存,或者是大小核的设计,而是使用全性能核的设计。它还提供ECC内存支持,并搭配C260系列PCH。同样的内核、同样的LGA1700插座,其实英特尔在2024年第四季度推出过至强E-2400系列。至强6300系列的出现看起来像是有意将至强E-2400统一到至强6品牌之下。
至强6全家福成形:高低搭配,平滑过渡
至强6700/6500性能核的发布,进一步完善了至强6家族产品线。整个面向主流和中高端市场的产品线覆盖了8核到144核,提供了领先的内核数量、独一份的内存带宽、具有前瞻性的加速器。对于正在进入换代周期的第二、第三代至强可扩展处理器的机型用户而言,至强6可以很好地承接业务迁移、升级的需求。对于保持传统业务的用户,至强6能效核可以平滑迁移并提供数倍的部署密度以及更好的能效,以改善运营成本。对于希望与时俱进,跟上AI浪潮的用户,至强6性能核不仅仅是提供更大更多的内核,其实还提供了更适应AI需求的加速器,以实现1+1>2的效果。
至强6为旗舰与主流产品提供了不同的封装规模。后者的封装尺寸与第三代至强可扩展处理器以来的几代产品保持相同,TDP的增长也比较谨慎。这意味着对于多数用户而言,这数年来积累的系统布局、运维习惯可以基本保持不变。
狂飙的内核与稳定的外形,这并非反差,而是技术前瞻性和对市场持久承诺的结合。
来源:至顶网计算频道
好文章,需要你的鼓励


依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
今天讲的出海案例是依米康,这家数据中心温控与液冷设备厂商正在把泰国纳入海外交付体系,并用生产线、总装车间和焓差实验室承接算力设施订单。

人民大学、上海AI实验室等联合打造的“全能生物AI“:一个模型搞定分子、蛋白质和自然语言的终极尝试
BioMatrix是首个将分子序列、分子三维结构、蛋白质序列、蛋白质三维结构和自然语言统一在单一语言模型中的生物基础模型,在80项任务中77项达到最优或第二优。

Craig Primack博士:远程医疗如何填补肥胖症诊疗缺口
美国远程医疗巨头Hims & Hers完成对澳大利亚竞争对手Eucalyptus的收购后,正式进军英国、德国、日本等市场。公司肥胖症业务负责人Craig Primack博士表示,肥胖症是慢性、复发性疾病,需综合治疗方案而非单纯开药。远程医疗能填补NHS等公共医疗体系的服务缺口,为患者提供药物、营养、运动及生活方式的全方位支持,并在GP停诊时提供及时的医疗咨询。

浙江大学研究团队打造“技能护栏“:让AI电脑助手在危险环境中也能安全学习和工作
浙江大学提出SKILLHARNESS框架,通过为AI电脑助手的每项技能附加安全边界,从成功、失败和风险三类经历中学习,使AI在动态危险环境中安全高效地完成任务。
2025
03/20
16:07
分享
点赞

依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
Craig Primack博士:远程医疗如何填补肥胖症诊疗缺口
OpenAI与Broadcom联合推出专为AI推理打造的定制芯片Jalapeno
IBM宣称推出全球首个亚纳米芯片技术
OpenAI 迎来 AI 研究大牛 Noam Shazeer 加盟
纳米堆栈是什么?IBM如何像建城市一样造芯片
免费AI Token陷阱:多供应商策略才能避免被锁定
IBM发布全球首款亚1纳米芯片,晶体管仅0.7纳米宽
提升AI智能体工作流的速度与能效
智能体AI如何变革芯片设计与验证流程
AI数据中心与HPC集群中I/O设计挑战持续升级
稳居全球企业存储市场榜首,戴尔科技以三大核心能力持续领跑
