
软件定义存储中,企业级SSD扮演了什么角色?
5G、人工智能、物联网、云计算技术快速升级,存储容量和性能需求也快速增长,全球数据量也进而呈现出爆炸式提升的状态。在海量应用场景下依靠单一的存储方式已经无法满足大规模非结构数据,如何在可控成本内高效、弹性地应对每一次数据洪峰的冲击,可靠的数据存储架构变得尤为关键。在诸多解决方案中,软件定义存储很快受到了欢迎。
软件定义存储是一种软硬件分离、利用软件对通用硬件进行管理的存储架构。对于虚拟化服务而言,用户端可以无视服务端具体由多少硬件、或是什么样的存储型号组成,也不限制服务端设备位于何处。这相当于智能家居的软件层面,用户只需要关注是否可以调节房间温度、灯光亮度,控制空调及灯具的遥控器放在哪里并不重要。
用户虽然可以自行选择运行存储服务的硬件,但实际上支持软件定义存储的硬件本身,也需要遵守一定规范,从而可以更好地帮助企业用户在虚拟化环境中部署固态硬盘资源,跳出传统物理存储设备布局的束缚。

让效率先行
提升软件定义存储性能也同样需要硬件支持,例如铠侠企业级PM7系列与数据中心级CD8系列所通过的VMware vSAN 8.0版本认证,可帮助企业基于实际应用中负载变化,动态地调整存储资源,自动维护各个虚拟机所需的存储容量、性能和可用性,并获得更高的I/O执行效率,提高整个虚拟化环境的性能以及可靠性。
同时这也并非铠侠第一次通过软件定义存储认证,作为NAND闪存技术发明者,铠侠一直积极推动存储技术发展,并积极适配用户的应用需求。在多年的应用和适配中,铠侠旗下已经有将近300款企业级和数据中心级SSD通过相关认证,可满足不同场景的虚拟化软件定义存储需求。
其中铠侠PM7系列是具备2.5英寸规格和支持SAS 4.0单、双端口设计的多功能型固态硬盘,具备优秀的兼容性、可靠性等诸多特点。相对上一代产品,铠侠PM7系列在随机读取性能提升幅度明显,并可提供高达30.72TB的容量点支持。

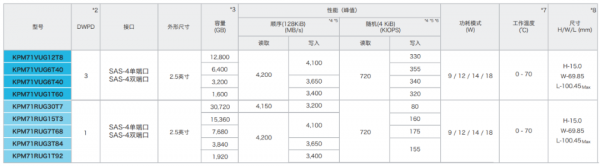
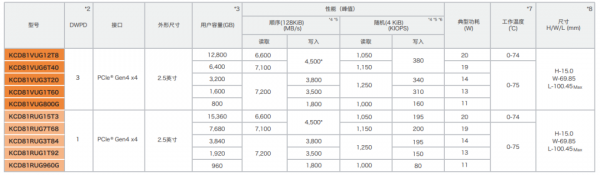
铠侠CD8系列是一款PCIe® 4.0 compliant并支持NVMe™ 1.4协议规范的产品,可提供高达7,200 MB/s顺序读取速度和1,250K IOPS随机读取速度。与此同时,CD8系列还提供读写混合型与读取密集型两个版本,其中读写混合型的CD8-V可提供3 DWPD耐久度和最高12.8TB容量,读取密集型CD8-R则可以提供1 DWPD耐久度和最高15.36TB容量。

对未来做足准备
在融合大数据、人工智能技术对数据存储性能提出更高要求的大环境下,优秀的存储性能变得愈发关键。软件定义存储能够进一步在自动驾驶、深度学习、人工智能加速、数字孪生、平台运营等诸多关键业务场景中,提供充足的发挥空间,同时对企业和数据中心的基础建设提出了更高要求。
铠侠同样也是积极推动具有前瞻性的EDSFF存储规范解决方案,,推出包括E1.S、E3.S规格在内的多款产品,并应对企业级和数据中心级客户针对PCIe® 5.0,推出CM7系列、CD8P系列等符合PCIe® 5.0 compliant的新一代产品。
在未来,铠侠将继续与合作伙伴们共同努力,为全球合作伙伴提供高效、可靠的存储解决方案,为AI加速、云计算、IoT等前沿领域提供高性能、多场景存储方案,助力客户进一步提升计算效率,抢占市场先机。

*容量的定义:铠侠定义1兆字节(MB)为1,000,000字节,1千兆字节(GB)为1,000,000,000字节,1兆兆字节(TB)为1,000,000,000,000字节。但是计算机操作系统记录存储容量时使用2的幂数进行表示,即定义1GB = 230 = 1,073,741,824字节,因此会出现存储容量变小的情况。可用存储容量(包括各种媒体文件的示例)将根据文件大小、格式、设置、软件和操作系统(例如Microsoft®操作系统和/或预安装的软件应用程序)或媒体内容而异。实际格式化的容量可能有所不同。
*1千位字节 (KiB) 指 210, 或1,024字节,1兆字节(MiB) 指 220,或1,048,576 字节,1千兆字节(GiB)指230, 或1,073,741,824字节。
*IOPS:每秒输入输出(或每秒I/O操作数)
*读写速度可能因主机设备、读写条件和文件大小的不同而不同。
*信息随时可能更改:虽然铠侠在发布时已努力确保此处提供信息的准确性,但产品规格、配置、价格、系统/组件/选项等的可用性都可能发生更改,恕不另行通知。
*产品图像可以代表设计模型。图像仅用于说明目的。产品外观可能与实际产品不同。闪存组件的实际数量因硬盘容量而不同。
来源:业界供稿
好文章,需要你的鼓励


遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
市场研究公司Klue本月初遭黑客入侵,大量客户数据被窃。Klue表示正与黑客组织Icarus沟通,并相信对方正在删除所盗数据。受影响客户包括Gong、LastPass、HackerOne等多家知名企业。然而事态趋于复杂——另一黑客团伙声称从Icarus处获取了Klue客户数据,并向客户发出勒索威胁。Klue提醒客户勿向第二方支付赎金,并建议索取数据样本以核实其真实性。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。

苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
苹果公司对OpenAI提起诉讼,指控其窃取商业机密。据披露,前苹果系统电气工程师刘畅(Chang Liu)在离职加入OpenAI后,利用一个此前未知的身份验证零日漏洞,持续数周从苹果内部网络存储中下载大量机密文件,内容涵盖未发布产品信息、工程演示文稿及技术规格等。苹果已修复该漏洞并终止相关访问权限。此案已提交加州北区联邦法院,并要求陪审团审判。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。
2024
04/11
17:20
分享
点赞

QumulusAI直接上市:加速面向企业AI的新型云服务
微软Exchange Server本地版使用门槛再度提高
新AI路线图能否约束科技巨头?
AI赋能医疗研究:如何在速度与质量间找到平衡
Applied Computing获2000万美元融资,为油气行业打造全厂AI基础模型
麻省理工学院新系统GIFT:让AI将2D设计高效转化为3D模型
Canvas母公司Instructure与两度入侵其系统的黑客达成协议
Grafana Labs遭黑客入侵后拒绝支付赎金
纽约公共医疗系统遭黑客入侵,逾180万人数据及指纹信息被窃
GitHub遭黑客入侵,约3800个内部代码仓库数据被盗
7-Eleven数据泄露事件波及逾18.5万人个人信息
黑客组织ShinyHunters声称入侵逾百家机构Oracle PeopleSoft服务器
