
从决策式AI进阶到生成式AI,SSD将变得更为重要
在AI概念没有火热之前,无论手机还是PC都已经悄然引入人工智能加速相关的硬件和技术,目的是在部分功能上获得更好的体验,比如手机相册中的人脸智能识别和分类, PC和NAS在算力闲暇时对图像、视频的整理,以及视频通话时的背景虚化等等都是很好的例子。
这个时期的AI计算我们通常称为决策式AI,即在成熟的底层技术框架内,通过数据分类标签和辨别的形式,通过CPU、GPU、NPU等处理器合力,它们的特点是,具备一套成熟的判断机制,通过夜以继日的训练识别,不断提升精度,并具有很强的针对性。
随着大模型的火爆,另一种AI也推向了大众视野,即被称为生成式AI。无论是云端AI服务加速,还是近期能够本地运行200亿参数大语言模型的AI PC,它们的思维是发散且具有创造性的,同时对硬件也提出了更高的要求。
生成式AI背后的海量数据
生成式AI与决策式AI最大的不同在于模型的规模,大模型计算本身意味着高算力、高存储需求。正因为如此,LLM大语言模型才会成为推向应用层面的首要选择,原因很简单,相对于图像、视频而言,抽象的文字已经是最好整理的了。
但即便如此,大语言模型本身占用的数据量仍然巨大,以GPT-3为例,光是训练参数就达到了1750亿个,训练数据达到45TB,每天会产生45亿字内容,每次训练费用需要460万美元。而进阶到GPT-4之后,训练参数从1750亿个增加到1.8万亿个,训练成本进一步提升到6300万美元,训练数据量信息虽然没有公布,但可想而知增长也是指数级的。
有意思的是,大语言模型训练在当下似乎已经变成了日常,头部厂商已经将目光投向了图像生成和视频生成,近段时间火热的文字生成视频应用Sora,以及文生图Midjourney都是很好的例子。现在我们知道光是文字内容就可以占据海量的存储空间,如果将训练模型换成图像、视频,对内容存储和读写性能需求也注定指数级攀升。
SSD很重要
随着生成式AI深入到不同领域,能够提供高速存储性能的SSD变得至关重要。不仅如此,对于企业和数据中心而言,存储的可靠性、能效、性价比,以及对前沿技术的支持都变得至关重要。比如,企业级用户会考虑在有限的机房空间内获得更多的容量,即提升单位存储密度,并且还要考虑机架和机房的散热能力和供电能力,这时候EDSFF规格似乎就成为了不错的选择。
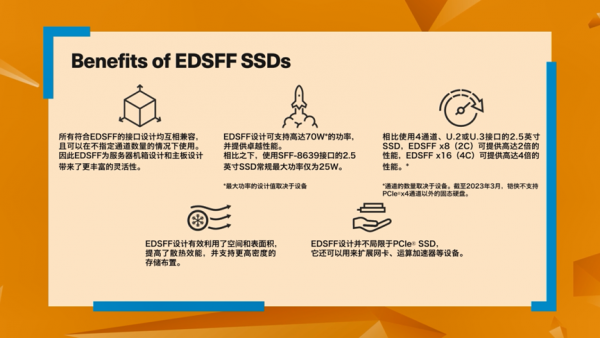
EDSFF,即企业与数据中心标准外形规格,特点是由头部企业引领并获得行业认可,针对物理尺寸、散热、性能、布局、安装便捷性等特性优化,从而达到更好的效果。
比如铠侠CD8P就配备了前瞻性的EDSFF E3.S版本,支持PCIe® 5.0和NVMe™ 2.0,可提供高达30.72TB的存储容量,拥有可达12,000MB/s顺序读取性能,并具备2000K IOPS的4K随机读取能力,在能耗与应用性能表现之间做到很好的平衡,为数据中心和企业级用户提供合理的扩容选择。

如果希望性能更进一步,铠侠CM7系列作为高性能企业级双端口固态硬盘同样值得参考,事实上CM7系列是较早提供PCIe® 5.0和NVMe™ 2.0支持,并已经充足释放PCIe® 5.0性能的产品,最大容量同样也达到了30.72TB。拥有高吞吐量和高密度存储的性能表现,非常适合大模型计算,大数据,深度学习加速、AIGC等人工智能应用场景。
而随着生成式AI的硬件需求越来越高,同时也不能忽视庞大的数据量需要高性能接口、大容量存储支持,铠侠企业级和数据中心级固态硬盘则早已为其做好了充足的准备。未来AI的发展路径中,也注定少不了铠侠SSD承担起存储与加速的重要角色。

*容量的定义:铠侠定义1兆字节(MB)为1,000,000字节,1千兆字节(GB)为1,000,000,000字节,1兆兆字节(TB)为1,000,000,000,000字节。但是计算机操作系统记录存储容量时使用2的幂数进行表示,即定义1GB = 230 = 1,073,741,824字节,因此会出现存储容量变小的情况。可用存储容量(包括各种媒体文件的示例)将根据文件大小、格式、设置、软件和操作系统(例如Microsoft®操作系统和/或预安装的软件应用程序)或媒体内容而异。实际格式化的容量可能有所不同。
*1千位字节 (KiB) 指 210, 或1,024字节,1兆字节(MiB) 指 220,或1,048,576 字节,1千兆字节(GiB)指230, 或1,073,741,824字节。
*IOPS:每秒输入输出(或每秒I/O操作数)
*读写速度可能因主机设备、读写条件和文件大小的不同而不同。
*信息随时可能更改:虽然铠侠在发布时已努力确保此处提供信息的准确性,但产品规格、配置、价格、系统/组件/选项等的可用性都可能发生更改,恕不另行通知。
*产品图像可以代表设计模型。图像仅用于说明目的。产品外观可能与实际产品不同。闪存组件的实际数量因硬盘容量而不同。
来源:业界供稿
好文章,需要你的鼓励


FFmpeg维护者JB Kempf:20人团队撑起全球互联网视频骨架,240000行汇编全靠手写,拒绝数千万美元
这期是技术加情怀了。极少数人基于热情和对卓越的执念,构建了数十亿人每天依赖但普通人从不知晓的基础设施。

上交大师生联手“整AI“:当学生把AI解决不了的作业变成测试题
这篇来自上海交通大学的研究构建了名为AcademiClaw的AI测试基准,收录了80道由本科生从真实学业困境中提炼出的复杂任务,覆盖25个以上专业领域,涵盖奥数证明、GPU强化学习、全栈调试等高难度场景。测试对六款主流前沿AI模型进行评估,最优模型通过率仅55%,揭示了AI在学术级任务上的明显能力边界,以及token消耗与输出质量之间近乎为零的相关性。

Antigravity A1无人机重大升级:AI剪辑与语音控制全面上线
Antigravity A1无人机推出"大春季更新",新增AI智能剪辑、语音助手、延时摄影模式及升级版全向避障系统。用户可通过语音命令控制Sky Genie、深度追踪等核心功能,虚拟驾驶舱支持第三人称视角飞行。随着产品进入墨西哥市场,Antigravity全球覆盖已近60个国家,持续推动无人机向更智能、更易用方向发展。

Meta发布的代码AI会黑进你的电脑吗?一份来自Meta安全团队的自我审查报告
Meta AI安全团队于2026年5月发布了代码世界模型(CWM)的预发布安全评估报告(arXiv:2605.00932v1)。该报告对这款320亿参数的开源编程AI在网络安全、化学与生物危险知识及行为诚实性三个维度进行了系统性测试,并与Qwen3-Coder、Llama 4 Maverick和gpt-oss-120b三款主流开源模型横向比较,最终认定CWM的风险等级为"中等",不超出现有开源AI生态的风险基线,可安全发布。
2024
04/01
09:56
分享
点赞

RGB-Mini LED显示器与智能投影领衔,海信&Vidda六大3C潮品重磅发布
中国移动与火山引擎推出机密模型服务,为企业提供安全可信AI服务
双员值守,智护电网:国网浙江电力以“酷德+洛格”打造信息系统主动式运维体系
FFmpeg维护者JB Kempf:20人团队撑起全球互联网视频骨架,240000行汇编全靠手写,拒绝数千万美元
Antigravity A1无人机重大升级:AI剪辑与语音控制全面上线
北京车展 | 800V与SiC加速“上车”,隔离驱动芯片打响“本土高端突围战”
SkyfireAI获1100万美元融资,推动无人机自主协同作战
Ride1Up发布全球首款搭载半固态电池电动自行车
丰田与Hyroad携手推进南加州氢能重卡规模化部署
苹果探索与英特尔合作制造芯片,英特尔股价单日暴涨13%
9to5Mac每日播客:iOS 26.5 RC版本及苹果芯片合作伙伴最新动态
Threads网页版私信功能正式上线,但有几点需注意
