
能源巨头埃尼集团成功将HPC性能提升一个数量级

全球各大石油与天然气企业,无疑是最早热衷于利用先进设备开展HPC(高性能计算)仿真与建模的客群之一。支持他们数十年如一日参与实验和投资的原因非常简单:只有提前弄清哪里有石油和天然气、哪里没有,才能避免浪费大量资金,尽可能增加项目决策的成功概率。
虽然各大石油与天然气巨头都掌握着相当庞大的HPC系统(而且与国家实验室类似,往往不止一套),但拥有3.1万余员工、在全球76个国家开展业务的意大利能源巨头埃尼对于HPC的重视和投入仍显得格外夸张。这家能源企业下辖石油、天然气、发电/配电业务以及化学精炼业务,并在过去十年间斥巨资构建多台超级计算机。
本周,埃尼集团再次果断出手,委托HPE和AMD为其位于米兰西南部费雷拉·埃尔博尼镇的绿色数据中心构建HPC6系统。
我们专门为此制作了一张表格,整理出2013年至2024年期间埃尼集团在该绿色数据中心内部署的HPC系统:
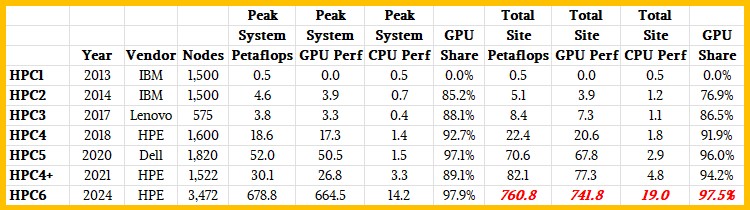
感兴趣的朋友还可点击此处(https://www-aicanet-it.translate.goog/en/storia-informatica/calcolo-scientifico-in-italia/eni?_x_tr_sl=it&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=sc)回顾埃尼集团自上世纪60年代以来的计算技术发展史。
在此期间,埃尼集团将其旗舰系统的容量扩大了1360倍,作为商业企业来说这样的HPC投入堪称飞跃。在2018年与HPE签订HPC4合作协议时,我们曾经发文介绍过HPC1、HPC2、HPC3和HPC4系统,当时HPE还没有收购Cray并获得相应的互连与系统设计成果。HPC1和HPC2系统由IBM构建而成,随着2014年底蓝色巨人手中的System x服务器业务被联想收购,HPC1和HPC2系统合同也随之易手。其中HPC1是一台纯CPU计算设备,但从HPC2开始埃尼集团就走上了CPU加GPU的混合道路。机器中的大部分算力来自GPU,但在必要时,系统也拥有充足的算力,能够在合理的规模下运行纯CPU代码。
2020年,戴尔拿到了为埃尼集团构建52千万亿次HPC5系统的合同。而在新冠病毒肆虐的2021年,埃尼又与HPE接洽,要求对HPC4系统进行升级。双方还出人意外地在2021年打造出一套全新HPC4+系统——采用的则是主要为公共事业企业设计的GreenLake计算与存储设施计费标准。关注者本以为埃尼集团会选择开发HPC6,而非对上代系统进行升级。但当时的埃尼明显头脑清醒,打算等待GPU市场竞争进一步升温,再由英伟达、AMD乃至英特尔参与HPC6系统的竞标。换句话说,HPC4+更像是一种权宜之计,旨在享受GPU厂商上代技术带来的价格优惠。
埃尼集团在利用GPU加速进行油藏建模与地震分析工作负载领域,身处石油与天然气行业的领先地位。2021年11月,埃尼与Stone Ridge Technology建立了战略合作伙伴关系,将后者提供的ECHELON动态油藏仿真工具引入自己的全面油藏仿真环境当中。作为石油与天然气行业的核心充分考虑需求,这类负载全部依赖GPU加速技术的支撑。也正因为如此,埃尼集团过去几年间对于GPU资源的需求也在不断增长,包括计划于今年年内部署到位的HPC6系统。预计HPC6有望亮相ISC24超级计算大会和6月同期发布的Top500超算榜单。

埃尼集团位于米兰的绿色数据中心采用AMD“Milan”或“Genoa”Epyc CPU,全新HPC6系统则匹配MI250X GPU。
考虑到HPC6的性能只相当于两年多前由美国橡树岭国家实验室部署的1.68百亿亿次“Frontier”超级计算机的37%,所以整个安装部署过程应该会比较顺利。
具体来讲,HPC6系统基于HPE Cray EX4000液冷机柜,与Frontier系统中使用的Cray EX235a定制机柜略有区别,但乍看上去仍颇有相似之处。HPC6系统中共设有28个这样的机柜,分别可容纳128个节点。但最后一个机柜中只安放16个节点,因此HPC6系统共包含3472个节点。每个节点只配备一块64核AMD处理器,我们推测这就是AMD专门为Frontier打造的定制化“Trento”芯片,其运行主频仅为2 GHz,且运行功耗也远低于标准64核“Milan”或“Genoa”处理器。但据我们了解,埃尼集团正计划部署标准Genoa处理器,希望通过其上提供的Infinity Fabric 4.0端口与系统中的AMD GPU保持一致通信。但这一情况尚未得到埃尼方面的证实。
HPC6系统中的GPU计算引擎并非新近发布的“Antares”MI300X加速器,而是延续了Frontier中采用的上一代“Aldebaran”MIX250X GPU。考虑到MI300X芯片拥有显著的性能(包括性价比)提升,暂时不清楚埃尼集团为何继续选择上代产品。这可能是因为AMD今年之内的全部MI300X产能均已分配给各分销商(主要面向超大规模基础设施运营商和云服务商,且相关合同可能去年年中就已经确定),此外劳伦斯利弗莫尔国家实验室也几乎占满了AMD今年之内的全部MI300A CPU-GPU混合芯片产能。如果AMD仍拥有大量MI250X处理器库存,且其单次浮点运算成本与MI300X相同,那么只要运行和散热空间不是太过紧张,应该可以满足埃尼集团的负载处理需求。
用美国前国防部长Donald Rumsfeld的话来说,GPU就是我们投身AI战场的武器。
总而言之,HPC6系统已经确定采用上代GPU技术,跟之前的HPC4+系统保持一致。这应该是埃尼集团有意为之,目的是在预算、能效和供货时间等指标中取得平衡。毕竟作为一套大型系统,埃尼集团必须考虑到还有很多公司愿意花高价一口气采购2万到5万张GPU,借此构建AI引擎。与这类受众相比,HPC客户明显预算不足,而且矢量性能更多关注FP64和FP32算力,跟强调FP8的AI负载有所区别。如果未来FP4运算成为AI主流,那么云服务商与超大规模基础设施运营商的需求将进一步与HPC客户分割开来。
在HPC6系统的3472个节点中,共容纳着13888个GPU,意味着其节点采用与Frontier系统相同的CPU对GPU 1:4比例。但如大家所见,如果着眼于单一Epyc插槽内的8个CPU小芯片和与之一一对应的4个双小芯片GPU,那么CPU与GPU的实际比率仍是1:1(Cray就特别在其超级计算机设计中采用1:1的CPU和GPU比例)。
为了将各节点连接起来,HPC6系统将采用Cray的现有Slingshot 11互连。这套互连体系由“Rosetta”交换机构成,这款交换机拥有64个传输速率为200 Gb/秒的扩展以太网端口,网卡上匹配的则是Cray“Cassini”ASIC。虽然思科、博通和Marvell推出的以太网ASIC均拥有4倍传输带宽(也就是同等或更高基数下的端口能够将传输速度提升2到4倍),但却不具备Cray这种以HPC为中心的Slingshot互连融合功能(这种功能在许多场景下也可用于加速AI工作负载)。我们还不清楚HPC6系统中所使用Slingshot网络的具体设计,唯一确定的就是其拥有像Frontier内部的蜻蜓拓扑结构。
埃尼集团宣布,HPC6将拥有超600千万亿次的峰值性能,并可在高性能LINPACK超级计算基准测试中提供至少400千万亿次的持续性能。而如果要把HPC6系统中CPU和GPU的峰值性能分别计算,我们猜测GPU的峰值性能约为664.5千万亿次,CPU的峰值性能则为14.2千万亿,合计总峰值性能为678.7千万亿次。其中GPU(及其HBM内存)占机器总峰值FP64浮点算力的97.5%,成本则占系统总成本的80%左右。
下图所示,为埃尼集团HPC1到HPC6系统随时间推移的CPU与GPU峰值变化(单位为千万亿次):
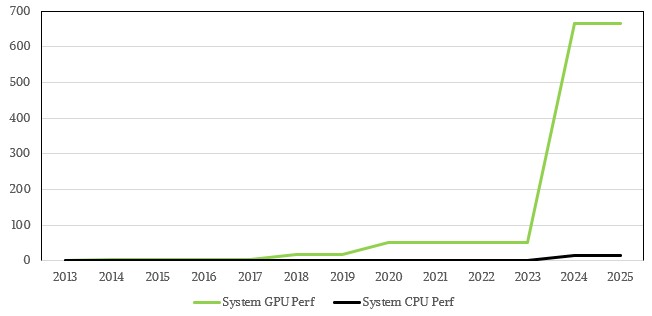
图中CPU的部分确实难以分辨,而GPU算力的迅猛增长则肉眼可见。下图所示,为对数坐标下HPC1到HPC6系统随时间推移的CPU与GPU峰值变化(单位为千万亿次):
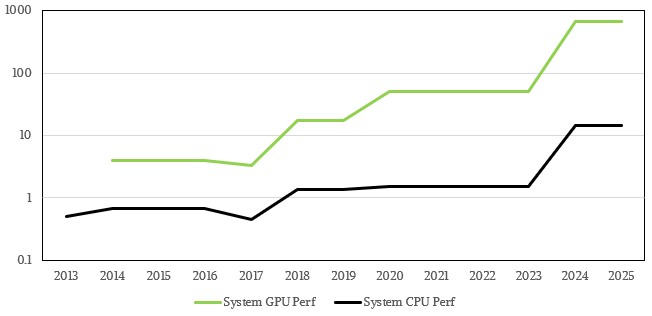
埃尼集团在声明中表示,HPC6系统采用的液冷技术能够处理掉系统全部发热量的96%,而携带热量的冷却液可进一步用于加热水温、为埃尼集团的办公室供暖。该公司还补充称,HPC6系统的峰值功率负载为10.17兆伏安。请注意,兆伏安(MVA)与兆瓦不同,是用于衡量设备理论峰值负载处理能力的指标。截至发稿时,我们仍不清楚埃尼集团给出数值的单位到底是10.17兆瓦,还是10.17兆伏安。无论如何,同等功率下兆伏安的数字要大于兆瓦,所以如果10.17的单位确实是兆伏安,那么兆瓦数字应该更小。相比之下,Frontier系统的额定功率为22.8兆瓦,所以根据网络与存储规模简单计算,HPC6的功率应该在8.3兆瓦左右。所以埃尼集团给出的兆伏安单位似乎没错。但在讨论超级计算系统时,人们大多是以兆瓦为实际功耗单位,所以这里大家可以姑且采信8.3兆瓦这个推测。
另外,很难说HPC6系统的构建成本是多少。但我们强烈怀疑埃尼集团的采购价格要高于橡树岭国家实验室。该国家实验室为了构建Frontier系统而砸下6亿美元,其中包括5亿美元的系统采购成本和1亿美元的非经常性工程(NRE)成本。Cray公司早在2019年就已经对外证实,Frontier系统这5亿美元采购成本中,有5000万美元专门购买存储设备,具体包括11.5 PB闪存层、679 PB磁盘层和专门用于存放元数据的10 PB闪存层。
假设每单位FP64计算成本相同,而且采用的Cray ClusterStor E1000“Orion”并行文件系统磁盘与附加的闪存容量(采用ZFS加Lustre混合文件系统)比例也相同,那么埃尼集团构建HPC6系统的成本应该在1.85亿美元左右。其中存储成本为1850万美元。粗略计算下来,这对应着250 TB磁盘加4.3 TB冷艳,再加上专门用于存放元数据的3.7 TB闪存。
而作为常规的商业客户,与橡树岭国家实验室的Frontier政府合同相比,埃尼这家能源巨头可能还需要额外支付溢价。从历史经验来看,溢价系数一般在1.5倍至2倍之间。再考虑到当前GPU市场需求旺盛、但供给侧严重不足的现实,我们认为埃尼集团很可能需要为HPC6系统支付2.5亿至3亿美元的构建投入。当然,另外一种可能就是埃尼集团在HPC6项目上享受到了与GreenLake相同的定价优惠,所以把总成本控制在了1.75亿美元。具体情况目前无法断言,后续我们会找机会跟HPE亲自求证。
埃尼集团还向我们证实,HPC6系统将在今年年内部署安装,而HPC4+和HPC5系统计划在2025年年内正式退役。但在此之前,埃尼绿色数据中心将至少拥有几个月的空前繁盛期——其总FP64性能将较两年之前提高10.8倍。而如果把衡量标准从FP64矢量计算换成FP64矩阵数学,那么GPU还能把成绩再提高1倍。
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2024
01/25
15:20
分享
点赞

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
福特3万美元电动皮卡再度现身测试路段
美国最大变压器工厂扩建,剑指AI数据中心用电需求
AMD 发布新一代 AMD RDNA(TM) 4 架构,推出 AMD Radeon(TM) RX 9000 系列显卡
HPE Gen12:英特尔至强6加持,数据中心和边缘计算的“新宠”
据报道,慧与同埃隆.马斯克的X公司签署价值10亿美元的人工智能服务器大单
HPE谈2025年合作伙伴激励包:Alletra MP、Private Cloud AI、VM Essentials均属于最高倍薪酬类别
HPE CEO谈超算优势、VM Essentials市场机会和财报业绩
HPE计划在2025年全面升级超级计算机阵容
苏姿丰的十年历程回顾:AMD如何从英特尔廉价替代品成长为x86领域的有力竞争者
面临AMD及自身内部挑战,英伟达Green 500主导地位受到威胁
微软率先拿下HBM驱动的AMD CPU供货
英伟达继续努力,希望推动AI融入包括HPC在内的一切领域
