
Triton推理服务器08-用户端其他特性
前面文章用Triton开源项目提供的image_client.py用户端作示范,在这个范例代码里调用大部分Triton用户端函数,并使用多种参数来配置执行的功能,本文内容就是简单剖析image_client.py的代码,为读者提供撰写Triton用户端的流程。
- 指定通信协议
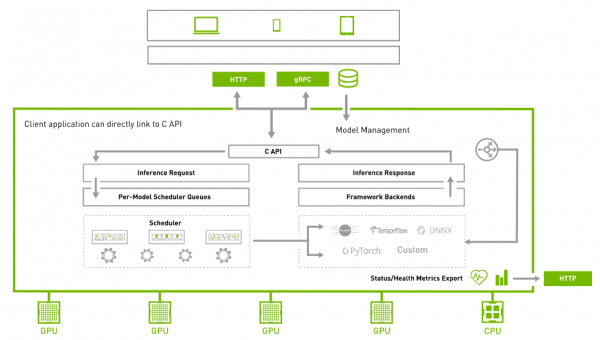
为了满足大部分的网路环境的用户端请求,Triton在服务器与用户端之间提供HTTP与gRPC两种通信协议,如下架构图所示:
当我们启动Triton服务器之后,最后状态会停留在如下截屏的地方:

显示的信息表示,系统提供8001端口给gRPC协议使用、提供8000端口给HTTP协议使用。此时服务器处于接收用户端请求的状态,因此“指定通信协议”是执行Triton用户端的第一个工作。
这个范例支持两种通信协议,一开始先导入tritonclient.http与tritonclient.grpc两个模块,如下:
|
37 39 |
import tritonclient.grpc as grpcclient import tritonclient.http as httpclient |
代码使用“-i”或“--protocal”其中一种参数指定“HTTP”或“gRPC”协议类型,如果不指定就使用“HTTP”预设值。再根据协议种类调用httpcclient.InferenceServerClient()或grpcclient.InferenceServerClient()函数创建triton_client对象,如下所示:
|
308 309 310 311 312 313 314 315 316 317 318 |
try: if FLAGS.protocol.lower() == "grpc": # Create gRPC client for communicating with the server triton_client = grpcclient.InferenceServerClient( url=FLAGS.url, verbose=FLAGS.verbose) else: # Specify large enough concurrency to handle the # the number of requests. concurrency = 20 if FLAGS.async_set else 1 triton_client = httpclient.InferenceServerClient( url=FLAGS.url, verbose=FLAGS.verbose, concurrency=concurrency) |
最后启用triton_client.infer()函数对Triton服务器发出推理要求,当然得将所需要的参数提供给这个函数,如下所示:
|
441 442 443 444 445 446 |
responses.append( triton_client.infer(FLAGS.model_name, inputs, request_id=str(sent_count), model_version=FLAGS.model_version, outputs=outputs)) |
不过image_client.py代码中并未设定gRPC所需要的8001端口,因此使用这个通讯协议时,需要用“-u”参数设定“IP:端口”,例如下面指令:
|
$ |
python3 image_client.py -m inception_graphdef -s INCEPTION VGG ${HOME}/images/mug.jpg -i GRPC -u <服务器IP>:8001 |
在examples范例目录下还有20个基于gRPC协议的范例以及10个基于HTTP协议的范例,则是在代码内直接指定个别通信协议与端口号的范例,读者可以根据需求去修改特定的范例代码。
- 调用异步模式(async mode)与数据流(streaming)
大部分读者比较熟悉的并行计算模式,就是在同一个时钟脉冲(clock puls)让不同计算核执行相同的工作,也就是所谓的SIMD(单指令多数据)并行计算,通常适用于数据量大而且持续的密集型计算任务。
对Triton推理服务器而言,并不能确认所收到的推理要求是否为密集型的计算。事实上很大的比例的推理要求是属于零碎型计算,这种状况下调用“异步模式”会让系统更加有效率,因为它允许不同计算核(线程)在同一个时钟脉冲段里执行不同指令,这样能大大提高执行弹性进而优化计算性能。
当Triton服务器端启动之后,就能接收来自用户端的“异步模式”请求,不过在HTTP协议与gRPC协议的处理方式不太一样。
在代码中用httpclient.InferenceServerClient()函数创建HTTP的triton_client对象时,需要给定“concurrnecy(并发数量)”参数,而创建gRPC的用户端时就不需要这个参数。
调用异步模式有时会需要搭配数据流(stream)的处理器(handle),因此在实际推理的函数就有triton_client.async_infer()与triton_client.async_stream_infer()两种,使用gRPC协议创建的triton_client,在调用无stream模式的async_infer()函数进行推理时,需要提供partial(completion_callback, user_data)参数。
由于异步处理与数据流处理有比较多底层线程管理的细节,初学者只需要范例目录下的代码,包括image_client.py与两个simple_xxxx_async_infer_client.py的代码就可以,细节部分还是等未来更熟悉系统之后再进行深入。
- 使用共享内存(share memory)
如果发起推理请求的Triton用户端与Triton服务器在同一台机器时,就可以使用共享内存的功能,这包含一般系统内存与CUDA显存两种,这项功能可以非常高效地降低数据传输的开销,对提升推理性能有明显的效果。
在image_client.py范例中并未提供这项功能,在Python范例下有6个带有“shm”文件名的代码,就是支持共享内存调用的范例,其中simple_http_shm_client.py与simple_grpc_shm_client.py为不同通信协议提供了使用共享系统内存的代码,下面以simple_grpc_shm_client.py内容为例,简单说明一下主要执行步骤:
|
76 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
# 1.为两个输入张量创建数据:第1个初始化为一整数、第2个初始化为所有整数 input0_data = np.arange(start=0, stop=16, dtype=np.int32) input1_data = np.ones(shape=16, dtype=np.int32)
input_byte_size = input0_data.size * input0_data.itemsize output_byte_size = input_byte_size
# 2. 为输出创建共享内存区域,并存储共享内存管理器 shm_op_handle = shm.create_shared_memory_region("output_data", "/output_simple", output_byte_size * 2)
# 3.使用Triton Server注册输出的共享内存区域 triton_client.register_system_shared_memory("output_data", "/output_simple", output_byte_size * 2)
# 4. 将输入数据值放入共享内存 shm_ip_handle = shm.create_shared_memory_region("input_data", "/input_simple", input_byte_size * 2)
# 5. 将输入数据值放入共享内存 shm.set_shared_memory_region(shm_ip_handle, [input0_data]) shm.set_shared_memory_region(shm_ip_handle, [input1_data], offset=input_byte_size)
# 6. 使用Triton Server注册输入的共享内存区域 triton_client.register_system_shared_memory("input_data", "/input_simple", input_byte_size * 2)
# 7. 设置参数以使用共享内存中的数据 inputs = [] inputs.append(grpcclient.InferInput('INPUT0', [1, 16], "INT32")) inputs[-1].set_shared_memory("input_data", input_byte_size)
inputs.append(grpcclient.InferInput('INPUT1', [1, 16], "INT32")) inputs[-1].set_shared_memory("input_data", input_byte_size, offset=input_byte_size)
outputs = [] outputs.append(grpcclient.InferRequestedOutput('OUTPUT0')) outputs[-1].set_shared_memory("output_data", output_byte_size)
outputs.append(grpcclient.InferRequestedOutput('OUTPUT1')) outputs[-1].set_shared_memory("output_data", output_byte_size, offset=output_byte_size)
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
# 8. 从共享内存读取结果 output0 = results.get_output("OUTPUT0") |
至于范例中有两个simple_xxxx_cudashm_client.py这是针对CUDA显存共享的返利代码,主要逻辑与上面的代码相似,主要将上面“shm.”开头的函数改成“cudashm.”开头的函数,当然处理流程也更加复杂一些,需要有足够CUDA编程基础才有能力驾驭,因此初学者只要大致了解流程就行。
以上就是Triton用户端会用到的基本功能,不过缺乏足够的说明文件,因此其他功能函数的内容必须自行在开源文件内寻找,像C++版本的功能得在src/c++/library目录下的common.h、grpc_client.h与http_client.h里找到细节,Python版本的函数分别在src/python/library/triton_client下的grpc、http、utils下的__init__.py代码内,获取功能与函数定义的细节。【完】
来源:业界供稿
好文章,需要你的鼓励


Cyera获得4亿美元融资专攻AI数据安全,估值达90亿美元
人工智能和数据安全公司Cyera宣布完成4亿美元后期融资,估值达90亿美元。此轮F轮融资由贝莱德领投,距离上次融资仅6个月。随着95%的美国企业使用生成式AI,AI应用快速普及带来新的安全挑战。Cyera将数据安全态势管理、数据丢失防护和身份管理整合为单一平台,今年推出AI Guardian扩展AI安全功能。

上海AI实验室研究者想出妙招:让AI像优秀学生一样高效思考,告别“想太多“毛病
上海AI实验室开发RePro训练方法,通过将AI推理过程类比为优化问题,教会AI避免过度思考。该方法通过评估推理步骤的进步幅度和稳定性,显著提升了模型在数学、科学和编程任务上的表现,准确率提升5-6个百分点,同时大幅减少无效推理,为高效AI系统发展提供新思路。

SAP推出全新AI功能助力零售业数字化转型
SAP在2026年全国零售联盟大展上发布了一系列新的人工智能功能,将规划、运营、履约和商务更紧密地集成到其零售软件组合中。这些更新旨在帮助零售商管理日益复杂的运营,应对客户参与向AI驱动发现和自动化决策的转变。新功能涵盖数据分析、商品销售、促销、客户参与和订单管理等领域,大部分功能计划在2026年上半年推出。

MIT团队让机器人终于不再“卡顿“:一种让机器人像人一样流畅反应的突破性技术
MIT团队开发的VLASH技术首次解决了机器人动作断续、反应迟缓的根本问题。通过"未来状态感知"让机器人边执行边思考,实现了最高2.03倍的速度提升和17.4倍的反应延迟改善,成功展示了机器人打乒乓球等高难度任务,为机器人在动态环境中的应用开辟了新可能性。
2023
01/03
16:59
分享
点赞

SAP推出全新AI功能助力零售业数字化转型
Gmail推出个性化AI收件箱与智能搜索等多项新功能
CISA警告HPE OneView和微软Office漏洞正被活跃利用
谷歌削减Android开源代码发布频率至每年两次
高通CES 2026:扩展IE-IoT产品组合推进边缘AI发展
恩智浦发布S32N7处理器系列,加速AI驱动汽车发展
n8n自动化平台严重漏洞可让攻击者完全控制服务器
微软将在Copilot中直接集成购买按钮功能
Snowflake收购Observe拓展AI驱动监控能力
丰田升级SUV产品线,RAV4新增信息娱乐系统
可信开源软件现状报告:AI重塑技术栈基线
思科修复ISE安全漏洞,公开概念验证代码已发布
