
TritonЭЦРэЗўЮёЦї05-АВзАЗўЮёЦїШэМў
дкЧАвЛЦЊЮФеТвбОДјзХЖСепДДНЈвЛИіTritonЕФЭЦРэФЃаЭВжЃЌЯждкжЛвЊАВзАКУЗўЮёЦїЖЫгыгУЛЇЖЫШэМўЃЌОЭФмНјааЛљБОЕФВтЪдгыЬхбщЁЃ
ЮЊСЫМђЛЏЙ§ГЬЃЌЮвУЧЪЙгУNVIDIA Jetson AGX OrinЩшБИНјааЪОЗЖЃЌЫљгаВНжшЖМФмЪЪгУгкИїжжЛљгкNVIDIA JetsonжЧФмаОЦЌЕФБпдЕЩшБИЩЯЃЌвВЪЪгУгкДѓВПЗжзАдиUbuntu 18вдЩЯВйзїЯЕЭГЕФx86ЩшБИЩЯЃЌМДБуЩшБИЩЯУЛгаАВзАNVIDIAЕФGPUМЦЫуПЈвВФмЪЙгУЃЌжЛВЛЙ§ЩЯЮвУЧЕФЬсЙЉЕФФкШнЖМЪЧЛљгкGPUМЦЫуЛЗОГЃЌЖдгкДПCPUЕФЪЙгУдђашвЊгУЛЇздаабаЖСЫЕУїЮФМўЁЃ
ЯждкОЭПЊЪМАВзАTritonЗўЮёЦїШэМўЃЌNVIDIAЮЊTritonЗўЮёЦїЬсЙЉвдЯТШ§жжШэМўАВзАЕФЗНЪНЃК
- дДДњТыБрвыЃК
етжжЗНЪНашвЊДгhttps://github.com/triton-inference-server/serverЯТдидДДњТыЃЌШЛКѓАВзАвРРЕПтЃЌдйгУcmakeгыmakeЙЄОпНјааБрвыЁЃЭЈГЃЛсгіЕНЕФТщЗГЪЧВНжшЗБЫіЃЌВЂЧвГіДэТЪНЯИпЃЌвђДЫВЂВЛЭЦМіЪЙгУетИіЗНЗЈЁЃ
гааЫШЄепЃЌЧыздааВЮПМЧАУцЯТдиЕФПЊдДВжРяЕФdocs/customization_guide/build.mdЮФМўЃЌгаЙигкUbuntu 20.04ЁЂJetpackгыWindowsЕШИїжжЦНЬЈЕФБрвыЯИНкЁЃ
- ПЩжДааЮФМўЃК
TritonПЊЗЂЭХЖгЮЊЪЙгУепЬсЙЉБрвыКУЕФПЩжДааЮФМўЃЌАќРЈUbuntu 20.04ЁЂJetpackгрWindowsЦНЬЈЃЌПЩвддкhttps://github.com/triton-inference-server/server/releases/ ЩЯЛёШЁЃЌУПИіАцБОЖМЛсЬсЙЉЖдгІNGCШнЦїЕФАцБОЃЌШчЯТЭМЃК

ШЛКѓЕНЯТУцЕФ“Assets”бЁдёКЯЪЪЕФАцБОЃК
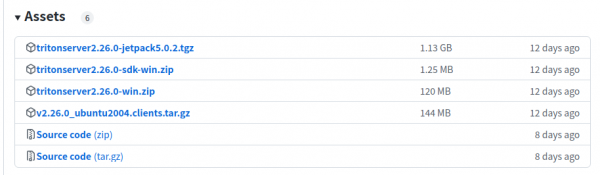
вдзАдиJetpack 5ЕФOrinЮЊР§ЃЌОЭЯТдиtritonserver2.26.0-jetpack5.0.2.tgz(1.13GB) бЙЫѕЮФМўЕНБОЛњЩЯЃЌШЛКѓНтбЙЫѕЕНжИЖЈФПТМЯТОЭПЩвдЃЌР§Шч${HOME}/tritonФПТМЃЌЛсЩњГЩ<backends>ЁЂ<bin>ЁЂ<clients>ЁЂ<include>ЁЂ<lib>ЁЂ<qa>ЕШ6ИіФПТМЃЌПЩжДааЮФМўдк<bin>ФПТМЯТЁЃ
дкжДааTritonЗўЮёЦїШэМўЧАЃЌЛЙЕУЯШАВзАЫљашвЊЕФвРРЕПтЃЌЧыжДаавдЯТжИСюЃК
|
$ $ |
sudo apt-get update sudo apt-get install -y --no-install-recommends software-properties-common autoconf automake build-essential git libb64-dev libre2-dev libssl-dev libtool libboost-dev rapidjson-dev patchelf pkg-config libopenblas-dev libarchive-dev zlib1g-dev |
ЯждкОЭПЩвджДаавдЯТжИСюЦєЖЏTritonЗўЮёЦїЃК
|
$ $ |
cd ${HOME}/triton bin/tritonserver --model-repository=server/docs/examples/model_repository --backend-directory=backends --backend-config=tensorflow,version=2 |
ШчЙћзюКѓГіЯжвдЯТЛУцВЂЧвНјШыЕШД§зДЬЌЃК
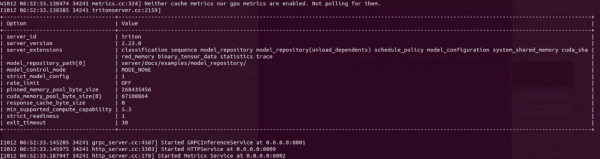
ЯждкTritonЗўЮёЦївбОе§ГЃдЫааЃЌНјШыЕШД§гУЛЇЖЫЬсГіЧыЧѓЃЈrequestЃЉЕФзДЬЌЁЃ
- DockerШнЦїЃК
дкNGCЕФhttps://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tagsПЩвдевЕНTritonЗўЮёЦїЕФDockerОЕЯёЮФМўЃЌУПИіАцБОжївЊЬсЙЉвдЯТМИжжАцБОЃК
- year-xy-py3ЃКАќКЌTritonЭЦРэЗўЮёЦїЃЌжЇГжTensorflowЁЂPyTorchЁЂTensorRTЁЂONNXКЭOpenVINOФЃаЭЃЛ
- year-xy-py3-sdkЃКАќКЌPythonКЭC++ПЭЛЇЖЫПтЁЂПЭЛЇЖЫЪОР§КЭФЃаЭЗжЮіЦїЃЛ
- year-xy-tf2-python-py3ЃКНіжЇГжTensorFlow 2.xКЭpythonКѓЖЫЕФTritonЭЦРэЗўЮёЦїЃЛ
- year-xy-pyt-python-py3ЃКНіжЇГжPyTorchКЭpythonКѓЖЫЕФTritonЗўЮёЦїЃЛ
- year-xy-py3-minЃКгУзїДДНЈздЖЈвхTriton ЗўЮёЦїШнЦїЕФЛљДЁЃЌШчCustomize Triton ContainerЃЈздЖЈвхTritonШнЦїЃЉЫЕУїЮФМўЫљУшЪіЕФФкШнЃЛ
Цфжа“year”ЪЧФъЗнЕФЪ§зжЃЌР§Шч2022ФъЬсНЛЕФОЭЪЧ“22”ПЊЭЗЃЛКѓУцЕФ“xy”ЪЧСїЫЎКХЃЌУПДЮЭљЩЯМг“1”ЃЌР§Шч2022Фъ10дТ4ШеЬсНЛЕФАцБОЮЊ“22-09”ЁЃ
NVIDIAЬсЙЉЕФTritonШнЦїОЕЯёЪЧЭЌЪБжЇГжx86/AMD64гыARM64МмЙЙЕФЯЕЭГЃЌвд22.09-py3ОЕЯёЮЊР§ЃЌПЩвдПДЕНШчЯТЭМЫљБъЪОЕФ“2 Architectures”:

ЕуЛїзюгвЗНЕФ“ЯђЯТ”ЭМБъЃЌЛсеЙПЊШчЯТЭМЕФФкШнЃЌЪТЪЕЩЯЪЧгаСНИіВЛЭЌАцБОЕФОЕЯёЃЌВЛЙ§ЪЙгУЯрЭЌОЕЯёУћЃК
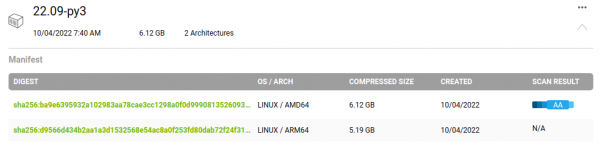
вђДЫдкx86ЕчФдгыJetsonЩшБИЖМЪЙгУЯрЭЌЕФОЕЯёЯТдижИСюЃЌШчЯТЃК
|
$ |
docker pull nvcr.io/nvidia/tritonserver:22.09-py3 |
ОЭФмИљОнЫљЪЙгУЩшБИЕФCPUМмЙЙШЅЯТдиЖдгІЕФОЕЯёЃЌЯждкжДаавдЯТжИСюРДЦєЖЏTritonЗўЮёЦїЃК
|
$
$ |
# ИљОнЪЕМЪЕФФЃаЭВжИљФПТМЮЛжУЩшЖЈTRITON_MODEL_REPOТЗОЖ export TRITON_MODEL_REPO=${HOME}/triton/server/docs/examples/model_repository # жДааTritonЗўЮёЦї docker run --rm --net=host -v ${TRITON_MODEL_REPO}:/models nvcr.io/nvidia/tritonserver:22.09-py3 tritonserver --model-repository=/models |
ШчЙћжДаае§ГЃЃЌвВЛсГіЯжвдЯТЕФЕШД§ЛУцЃЌБэЪОдЫааЪЧе§ШЗЕФЃК
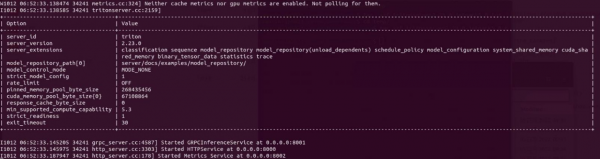
вдЩЯШ§жжЗНЪНЖМФмдкМЦЫуЩшБИЩЯЦєЖЏTritonЗўЮёЦїШэМўЃЌФПЧАПДЦ№РДЪЙгУDockerОЕЯёЪЧзюЮЊМђЕЅЕФЁЃЕБЗўЮёЦїШэМўЦєЖЏжЎКѓЃЌОЭДІгк“ЕШД§ЧыЧѓ”зДЬЌЃЌПЩвдЪЙгУ“Ctrl-C”зщКЯМќжежЙЗўЮёЦїЕФдЫааЁЃ
гавЛжжШЗШЯTritonЗўЮёЦїе§ГЃдЫааЕФзюМђЕЅЗНЗЈЃЌОЭЪЧгУcurlжИСюМьВщHTTPЖЫПкЕФзДЬЌЃЌЧыжДаавдЯТжИСюЃК
|
$ |
curl -v localhost:8000/v2/health/ready |
ШчЙћгаЯдЪО“HTTP/1.1 200 OK”ЕФаХЯЂЃЈШчЯТЭМЃЉЃЌОЭФмШЗЖЈTritonЗўЮёЦїДІгке§ГЃдЫааЕФзДЬЌЃК
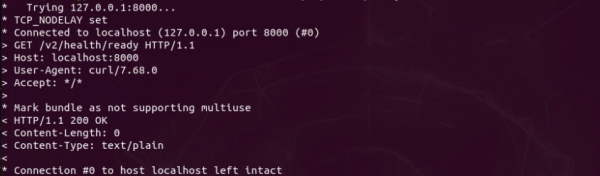
НгЯТШЅОЭвЊАВзАПЭЛЇЖЫШэМўЃЌгУРДЖдЗўЮёЦїЬсГіЭЦРэЧыЧѓЃЌетбљВХЫуЭъГЩвЛИізюЛљДЁЕФЭЦРэжмЦкЁЃЁОЭъЁП
РДдДЃКвЕНчЙЉИх
КУЮФеТЃЌашвЊФуЕФЙФРј


АЃЩемгыAnthropicКЯзїв§СьAIМЏГЩЩЬсШЦ№жЎТЗ
АЃЩемгыAnthropicРЉДѓКЯзїЃЌМЦЛЎХрбЕ3ЭђУћдБЙЄЪЙгУClaudeЃЌБъжОзХЦѓвЕAIеНТдаТЗНЯђЁЃУцЖдИДдгФЃаЭЩњЬЌЁЂжЮРэвЊЧѓКЭШЫВХЖЬШБЃЌзЩбЏЙЋЫОе§ГЩЮЊЙиМќЕФAIЯЕЭГМЏГЩЩЬЁЃбаОПЯдЪО95%ЕФЦѓвЕAIЪдЕуЯюФПСуЛиБЈЃЌОЁЙмЭЖзЪ300-400вкУРдЊЁЃМЏГЩЩЬФмЬюВЙММЪѕФмСІгыЪЕМЪгІгУМфЕФКшЙЕЃЌЕЋвВДјРДаТЕФвРРЕЗчЯеЁЃCIOашвЊдкРћгУЭтВПКЯзїЛяАщЕФЭЌЪББЃГжФкВПФмСІНЈЩшКЭМмЙЙзджїШЈЁЃ

зжНкЬјЖЏЗЂВМGARЃКШУAIФмЯёШЫРрвЛбљОЋзМРэНтЭМЯёШЮКЮЧјгђЕФЭЛЦЦадММЪѕ
зжНкЬјЖЏЕШЛњЙЙСЊКЯЗЂВМGARММЪѕЃЌШУAIФмЭЌЪБРэНтЭМЯёЕФШЋОжКЭОжВПаХЯЂЃЌЪЕЯжЖдЖрИіЧјгђМфИДдгЙиЯЕЕФзМШЗЗжЮіЁЃИУММЪѕЭЈЙ§RoIЖдЦыЬиеїжиЗХЗНЗЈЃЌдкБЃГжШЋОжЪгвАЕФЭЌЪБЬсШЁОЋШЗЯИНкЃЌдкЖрЯюВтЪджаБэЯжГіЩЋЃЌЩѕжСдкФГаЉжИБъЩЯГЌдНСЫЬхЛ§ИќДѓЕФФЃаЭЃЌЮЊAIЪгОѕРэНтФмСІДјРДживЊЭЛЦЦЁЃ

Pure StorageКЭЛЊЮЊДцДЂдіГЄзюПьЃЌIDCЕкШ§МОЖШБЈИцЯдЪО
IDCЗЂВМ2025ФъЕкШ§МОЖШШЋЧђЦѓвЕМЖДцДЂЯЕЭГЪаГЁзЗзйБЈИцЃЌЯдЪОДцДЂЪаГЁЭЌБШдіГЄ2.1%жСНќ80вкУРдЊЁЃДїЖћвд22.7%ЪаГЁЗнЖюОгЪзЃЌЛЊЮЊвд12%ЗнЖюЮЛСаЕкЖўЧвдіГЄ9.5%ЁЃШЋЩСДцеѓСаБэЯжЭЛГідіГЄ17.6%ЃЌжаЖЫДцДЂЯЕЭГдіГЄ8.1%ЁЃЕигђЗНУцЃЌШеБОЁЂМгФУДѓКЭХЗжоБэЯжзюМбЃЌЖјУРЙњЪаГЁЯТНЕ9.9%ЁЃIDCдЄМЦЫцзХAIгІгУЩјЭИЃЌЦѓвЕЖдЩСДцДцДЂашЧѓНЋГжајдіГЄЁЃ

Inclusion AIЭЦГіЭђвкВЮЪ§ЫМЮЌФЃаЭRing-1TЃКЪзИіПЊдДЕФГЌДѓЙцФЃЭЦРэв§ЧцШчКЮжиЫмAIЫМПМБпНч
Inclusion AIЭХЖгЭЦГіЪзИіПЊдДЭђвкВЮЪ§ЫМЮЌФЃаЭRing-1TЃЌЭЈЙ§IcePopЁЂC3PO++КЭASystemШ§ЯюКЫаФММЪѕЭЛЦЦЃЌНтОіСЫГЌДѓЙцФЃЧПЛЏбЇЯАбЕСЗЕФЮШЖЈадКЭаЇТЪФбЬтЁЃИУФЃаЭдкAIME-2025ЛёЕУ93.4ЗжЃЌIMO-2025ДяЕНвјХЦЫЎЦНЃЌCodeForcesЛёЕУ2088ЗжЃЌеЙЯжГізПдНЕФЪ§бЇЭЦРэКЭБрГЬФмСІЃЌЮЊAIЭЦРэФмСІЗЂеЙЪїСЂСЫаТЕФРяГЬБЎЁЃ
2023
01/03
16:55
ЗжЯэ
Еудо

Г§гЂЮАДяКЭЬЈЛ§ЕчЭтЃЌЦфЫћAIЙЋЫОЖМашвЊППСПВЙРћ
2025ФъЪ§ОнжааФаОЦЌСьгђзюШШУХЗЂеЙЧїЪЦ
здЖЏЛЏММЪѕСьЕМепНвЪОЦѓвЕЖдAIШЯжЊЕФЙиМќЮѓЧј
ЮхЗжжЎШ§ЦѓвЕЖдWi-FiЭЖзЪаХаФдіЧП
CIOВПЪ№аТаЫММЪѕжИФЯЃКGartnerШ§ВНЗЈЦНКтЗчЯегыЪевц
АЃЩемгыAnthropicКЯзїв§СьAIМЏГЩЩЬсШЦ№жЎТЗ
Pure StorageКЭЛЊЮЊДцДЂдіГЄзюПьЃЌIDCЕкШ§МОЖШБЈИцЯдЪО
гЂЬиЖћЛђвд16вкУРдЊЪеЙКAIЭЦРэаОЦЌГѕДДЙЋЫОSambaNova
5DМЧвфОЇЬхНЋГЩЮЊЮДРДЪ§ОнДцДЂжїСїММЪѕ
ЪзНьШЋЙњЖРНЧЪоЦѓвЕДѓШќзмОіШќдк№ЎЫГРћБеФЛ
ЮЊШЋЬьКђТЬЕчЖјЩњЃЌКЃГНДЂФмЗЂВМШЋЧђЪзИідЩњ8аЁЪБГЄЪБДЂФмНтОіЗНАИ
ЮЊAI+ЖјЩњЃЌКЃГНДЂФмЗЂВМШЋЧђЪзПюяЎФЦаЭЌAIDCШЋЪБГЄДЂФмНтОіЗНАИ
TritonЭЦРэЗўЮёЦї11-ФЃаЭРрБ№гыЕїЖШЦї(1)
TritonЭЦРэЗўЮёЦї10-ФЃаЭВЂЗЂжДаа
TritonЭЦРэЗўЮёЦї09-ЮЊЗўЮёЦїЬэМгФЃаЭ
TritonЭЦРэЗўЮёЦї08-гУЛЇЖЫЦфЫћЬиад
TritonЭЦРэЗўЮёЦї07-image_clientгУЛЇЖЫВЮЪ§
TritonЭЦРэЗўЮёЦї06-АВзАгУЛЇЖЫШэМў
TritonЭЦРэЗўЮёЦї05-АВзАЗўЮёЦїШэМў
TritonЭЦРэЗўЮёЦї04-ДДНЈФЃаЭВж
TritonЭЦРэЗўЮёЦї02-ЙІФмгыМмЙЙМђНщ
TritonЭЦРэЗўЮёЦї01-гІгУИХТл
