
计算增强很容易,内存升级却越来越难

如果没法以足够快的速度获取数据、以供计算引擎在特定时钟周期内完成特定数据处理操作,那再强的向量或矩阵单元浮点运算性能又有啥用?很明显,存储跟不上,算力确实会后继乏力。
几十年来,人们一直在讨论计算和内存带宽间的失衡。而且每一年,高性能计算行业都不得不接受单位浮点运算所对应的内存带宽越来越低的事实。虽然不像算力那么直观,但内存带宽其实也是一种资源类型,而且相当昂贵。
在我们考量这个问题的同时,内存容量的提升也步步趋于瓶颈。摩尔定律的困境不仅影响着CPU,内存也同样不能幸免。半导体厂商越来越难以开发出密度更高、速度更快的内存,这也导致内存的价格一路飙升。过去几十年间容量大涨、成本不变的美梦,似乎终于到了醒来的一天。
在Jack Dongarra的图灵奖获奖演讲中,这位橡树岭国家实验室杰出研究员兼田纳西大学名誉研究教授敏锐地提出,超级计算机架构其实每十年左右就会发生一波变化。沿着这个思路推断,如今处理器元件过多、但内存带宽却跟不上算力发展的现实,也一定会驱动架构的又一次调整。英特尔也适时发布了“Sapphire Rapids”至强SP服务器CPU的一些基准测试结果,展示了HBM2e堆叠内存的优势,其内存带宽约为现代服务器CPU中常见的普通DDR5内存条的4倍。(Sapphire Rapids提供64 GB HBM2e内存选项,可以与DDR5内存配合使用或选择纯HBM2e。)从HBM2e高带宽内存的优秀表现,恰好可以看出以往CPU算力和传输带宽间的失衡:
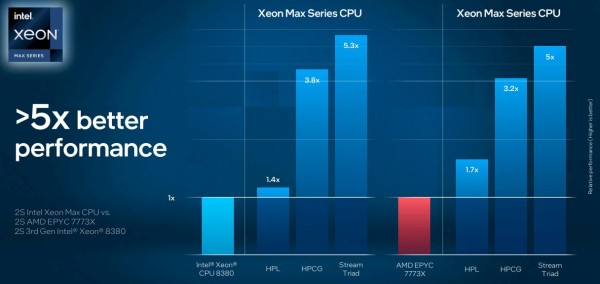
向Sapphire Rapids CPU引入HBM2e内存,并不会对高性能Linpack(HPL)矩阵数学基准测试造成太大影响,这是因为HPL不受内存限制。但在高性能共轭梯度(HPCG)和Stream Triad基准测试方面(二者都疯狂依赖于内存传输),转向HBM2e确实能实现性能提升。在正常情况下,HPCG测试可能跟实际应用最为接近,更能反映某些高难度HPC应用程序的真实编写方式。考虑到全球最快超级计算机的各时段平均算力利用率也就有1%到5%之间,那么将3.8倍的性能提升扩展到数千个节点,确实会带来非常大的改进。当然,这一切只是我们的猜测,HPCG跟现实间的差距还有待观察。
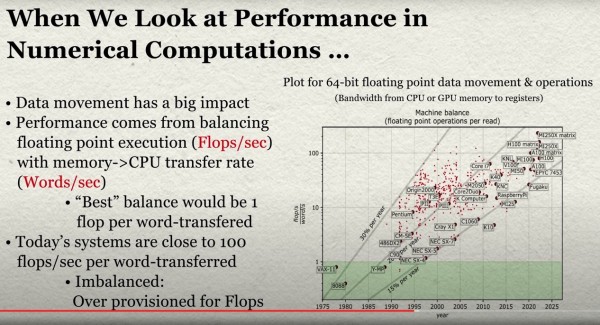
那么,CPU算力跟内存带宽之间到底有多大差距?我们来看Dongarra在演讲中展示的超级计算系统架构变化图:
放大这里的图表部分:

Dongarra解释道,“当我们衡量当今机器上的性能时,会发现数据移动才是制约速度的瓶颈。我们研究浮点执行率除以数据移动率,研究不同的处理器。过去,我们的处理器基本能做到每次浮点运算对应一次数据移动,也就是达成了1:1平衡。大家可能还记得原先的Cray-1,系统可以同时运行两项浮点运算和三次数据移动。但随着时间推移,处理器和内存开始出现失衡。接下来二十年间,这种失衡又扩大了一个量级。也就是说,现在每次数据移动要对应十次浮点2运算。最近,我们甚至发现每次数据移动开始对应上百次、甚至200次浮点运算。也就是说,浮点运算和数据移动间出现了巨大的失衡。所以我们虽然掌握着强大的算力,但因为数据移动指标跟不上,所以这些算力根本就用不起来。”
从图表中可以看到,随着超算系统架构的升级,失衡状况也越来越严重。我们认为,转向HBM2e、HBM3甚至是后面的HBM4和HBM5只是个开始。CXL内存也能部分解决这个问题。由于CXL内存的速度比闪存快,所以我们往往将其作为系统架构师的工具。但系统中可以容纳CXL内存容量和带宽扩展的PCI-Express通道是有限的,所以尽管内存共享的思路不错,在HPC模拟/建模和AI训练工作负载中也表现很好,但其仍有自己的局限性。
另外,我们还不清楚Sapphire Rapids上使用HBM2e内存的成本是多少。如果它能让受内存限制的应用程序的性能提高4到5倍,但CPU自身的价格涨个3倍,那新架构的每瓦性能收益基本还是在原地踏步。
新一代至强SP上的HBM2e内存选项算是朝着正确方向迈出的良好一步。但如果想让算力跟内存恢复平衡,最好是能让处理器上的L1、L2和L3缓存更大一些。
Dongarra表示,“我一直在抱怨计算设备的失衡。时至今日,我们能够买到的AMD或者英特尔家的现成商品处理器、加速器乃至互连方案,全都是不可调整的僵化产物。我们没法根据应用程序的驱动细节来设计硬件。所以要想保有发展空间,我们可能应该退后一步,看看架构如何与应用程序交互,又如何通过软件实现设计协同。协同非常重要,但在我们的硬件设计中却很少看到。这方面日本做得不错,他们的架构师和硬件人员会紧密沟通,设计出平衡性更好的机器。因此,如果着眼于前瞻性研究项目,我觉得接下来是时候把注意力转回架构上来了,让架构更好地反应应用程序的执行需求。总之,我们应当在硬件、应用程序和软件之间取得更好的平衡,找到真正的协同设计路径。我当初上大学的时候,学校就在探索能将设备组装起来的架构。斯坦福大学、麻省理工和卡耐基梅隆大学都有类似的尝试。但到现在,人们好像认为架构就这样了,没什么变化余地。或许我们该投入资金和研究支持,没准可以向能源部求助,共同为计算架构的发展翻开新的篇章。”
我们完全同意Dongarra提出的软件/硬件协同设计原则,也坚信架构应当反映其上运行的软件。坦率地讲,如果一台百亿亿次超算要花费5亿美元,但真正能用来执行运算的算力只有5%,那无疑代表着巨大的资源浪费。按照Dongarra的思路前进,未来的每台超级计算机都会有自己独特的性格。虽然这会降低通用性、拉升设计成本,但其每瓦性能、单位算力成本、单位内存带宽性能和单位内存带宽成本都将远远优于现有超算在HPCG等测试中的表现。没错,我们必须让HPC和AI架构重新走上正轨。
这是每一位半导体从业者必须承认并解决的难题。如果放任不管、无视Dongarra和他同行们的提醒,那就是在逃避责任、甚至可说是一种经济犯罪。
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2022
12/14
11:42
分享
点赞

当数据库开始为Agent重写,OceanBase如何再造AI数据库?
Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Chamath Palihapitiya 为 AI 编程初创公司融资 1.35 亿美元并出任 CEO
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
