
全新Spectrum-4以太网平台和互连技术 NVIDIA多管齐下加速互联互通 原创
在3U一体数据中心新加速计算架构中,CPU承担通用计算业务应用的工作负载,GPU解决并行计算的工作负载,DPU承担加速数据移动的工作负载,互联互通的网络重要性不言而喻。
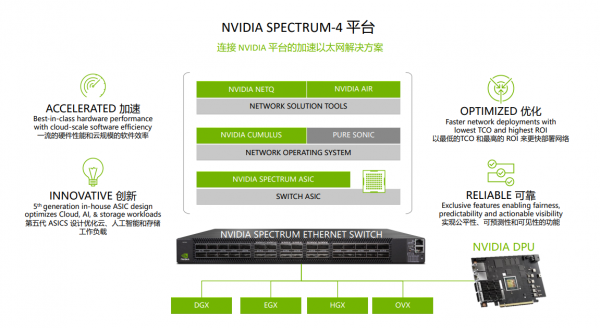
在GTC 2022上,NVIDIA宣布了一系列的网络产品更新,其中包括Spectrum-4以太网平台以及NVIDIA OVX 系统等。
Spectrum-4以太网平台让连接更高效更安全
数据中心呈现指数级增长,服务器和应用层面对网络带宽的要求越来越高,同时还要更好的安全性和强大的功能。为了满足这些需求,一个可以在大规模应用场景提供高性能、低延时以及高级的虚拟化和模拟仿真支持的以太网平台,是一个必不可少的解决方案。
NVIDIA Spectrum-4是新一代的以太网平台,将为大规模数据中心基础设施提供所需的超高网络性能和强大安全性。

NVIDIA网络专家崔岩告诉记者,Spectrum-4以太网平台不光是一款交换机产品,包含Spectrum-4交换机、ConnectX-7智能网卡和BlueField-3 DPU。“Spectrum-4以太网平台和Quantum-2 InfiniBand平台均包括BlueField-3 DPU,BlueField-3 DPU最大的作用就是卸载、加速和隔离数据中心基础设施,实现软件定义、硬件加速的网络、存储和安全。在网络、存储、安全性能大幅提升的同时,还通过DOCA软件架构提供强大可编程性和向后兼容性。”

其中,Spectrum-4交换机实现了纳秒级计时精度,相比普通毫秒级数据中心提升了五到六个数量级。这款交换机还能加速、简化和保护网络架构,支持多种加密、解密、加速功能。与上一代产品相比,其每个端口的带宽提高了2倍,交换机数量减少到1/4,功耗降低了40%,可以替代更多原有的交换机,使得拓扑结构更简单、管理更容易,从能耗到空间占用等等方面都会带来好处。
NVIDIA Spectrum-4 ASIC和SN5000交换机系列基于台积电4N工艺,包含1000多亿个晶体管以及经过简化的收发器设计,具有领先的能效和总拥有成本。
崔岩表示,Spectrum-4 400G交换机更高效、更安全、更节能省电。凭借支持128个400GbE端口的51.2Tbps聚合ASIC带宽,以及自适应路由选择和增强拥塞控制机制,Spectrum-4优化了基于融合以太网的RoCE (RDMA over Converged Ethernet)网络架构,并显著提升了数据中心的应用速度。

ConnectX-7智能网卡具有四个方面的优势:加速软件定义的网络、提供从边缘到核心的安全性、存储性能上的提升、精准计时为数据中心应用程序和时间敏感型基础设施提供更精准的时间同步。

NVIDIA BlueField-3 DPU和DOCA数据中心基础设施软件组成,能够大幅加速大规模云原生应用。而且BlueField-3 DPU还可以实现零信任安全,把应用域和基础设施域进行隔离,保障客户端的应用和基础设施端的数据安全。
BlueField-3 DPU可以提供更好的编程能力,NVIDIA也会同步更新DOCA SDK的开发平台,使更多的开发者能够基于BlueField-3 DPU平台开发软件定义网络、存储和安全的应用程序。同时DOCA上也会提供更多的服务,让用户直接采用基于容器的服务,支撑网络上面的业务。
崔岩说,Spectrum-4不只是一个网络平台,还会与NVIDIA其他的平台软件和应用进行整合,提供更好的以太网连接,达到最好的网络应用效果支撑上层应用。“我们通过与生态系统合作可提供多种应用场景的解决方案,配合Spectrum-4以太网平台和Quantum-2 InfiniBand平台可以为客户构建更高性能、更低延时、更安全的网络架构,更好地支撑上层业务应用负载和AI加速负载。”
总之,由Spectrum交换机、BlueField DPU和ConnectX智能网卡组成的Spectrum平台能够提高AI应用、数字孪生和云基础架构的性能和可扩展性,为现代数据中心带来极高的效率和可用性。
互连技术满足多样化工作负载要求
在GTC 2022上,NVIDIA发布了用于驱动大规模数字孪生的NVIDIA OVX计算系统。NVIDIA OVX专为运行NVIDIA Omniverse(实时物理级准确世界模拟和3D设计协作平台)中的复杂数字孪生模拟而设计。

OVX服务器由8个NVIDIA A40 GPU、3个NVIDIA ConnectX-6 Dx 200Gbps网卡、1TB系统内存和16TB NVMe存储组成。
OVX计算系统可以从由8台OVX服务器组成的单节点 扩展到通过NVIDIA Spectrum-3交换架构连接的一个或多个OVX SuperPOD(由32台OVX服务器组成),来加速大规模数字孪生模拟。

NVIDIA网络市场总监孟庆表示,未来,OVX服务器会搭载Spectrum-4实现集群的扩展和性能提升。“目前数据中心正在向着基础设施平台的方向发展,用来支撑从民生到科学探索、人工智能、私人服务等各方面的应用。高带宽、低延迟、数据安全和性能隔离——这是现代数据中心对网络的直接需求。”
伴随着NVIDIA Hopper架构的公布,首款基于Hopper架构的GPU——NVIDIA H100将搭载新的互联技术,第4代NVIDIA NVLink结合全新的外接NVLink Switch,可将NVLink扩展为服务器间的互连 网络,最多可以连接多达256个H100 GPU,相较于上一代采用NVIDIA NVLink只能连接机器内的8个GPU ,数量高出32倍 ,这样让数据处理通路更加顺畅。

孟庆说,NVLink Switch与InfiniBand网络的最大区别是NVLink只连接GPU,通俗说就是“内存网络”,它连接的是GPU计算的内存或者可以理解为显存,它不连接其他所有的通用计算网络。而InfiniBand仍然是AI和超级计算的首选网络。
NVIDIA全新的InfiniBand网络平台,基于英伟达的Quantum-2交换机、ConnectX-7网络适配器、BlueField-3数据处理 器 (DPU)以及所有支持新架构的软件DOCA。

孟庆表示,InfiniBand网络搭载第三代SHARP网络计算,以及精确计时功能,其可以让GPU之间甚至跨节点AI训练的时候,保证数据一致性,承载云原生、AI、HPC集群。

此外,NVIDIA还推出了一款全新的融合加速器H100 CNX,其耦合H100 GPU与NVIDIA ConnectX-7 400Gb/s InfiniBand和以太网智能网卡,可为I/O密集型应用(如企业级数据中心内的多节点AI训练和边缘5G信号处理)提供强劲性能。
我们知道NVIDIA致力于打造3U一体的战略,也就是CPU、GPU、DPU。在今年GTC上,NVIDIA正式推出了Grace CPU。而NVIDIA Hopper架构GPU可与NVIDIA Grace CPU通过NVLink-C2C互联,与PCIe 5.0相比,可将CPU和GPU之间的通信速度提高7倍以上。
孟庆说,NVIDIA NVLink-C2C是一种超快速的芯片到芯片 的互连技术,将支持 NVIDIA GPU、CPU、DPU、SmartNIC和SOC之间实现一致的互连,助力数据中心打造新一代的系统级集成。
结语
随着数据中心对于网络的要求越来越高,网络平台的革新不可缺少。不管是Spectrum-4以太网平台还是NVLink、InfiniBand等互连技术的更新,NVIDIA在数据中心的互联互通方面一直持续持续创新,让数据中心能够应对不断涌现的新型工作负载。
来源:至顶网计算频道
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2022
04/14
15:10
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
英特尔推出具备高性能和能效的以太网解决方案
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
