
Superuser Awards揭晓 OpenStack Summit Berlin 2018进入第二天 原创
至顶网服务器频道 11月15日 新闻消息(文/李祥敬):德国柏林时间2018年11月14日,OpenStack Summit Berlin 2018进入第二天,在今天的活动上,OpenStack基金会宣布了最新的OpenStack Train版本,并宣布Open Infrastructure Summit将在2019年Q4在中国举行。同时基金会详细介绍了OpenStack基金会旗下的四个独立项目——Airship、Zuul、StarlingX、Kata Containers。



Airship是一个新型云开放基础设施项目,其最初是想实现一个在Kubernetes上引入OpenStack(OOK)以及生成云的生命周期管理的声明式平台。Airship允许云运营商在每个阶段管理站点,包括从最初创建到后来次要和主要更新以及配置更改和OpenStack升级。它通过统一、声明式、完全容器化以及云原生平台来实现这一点。

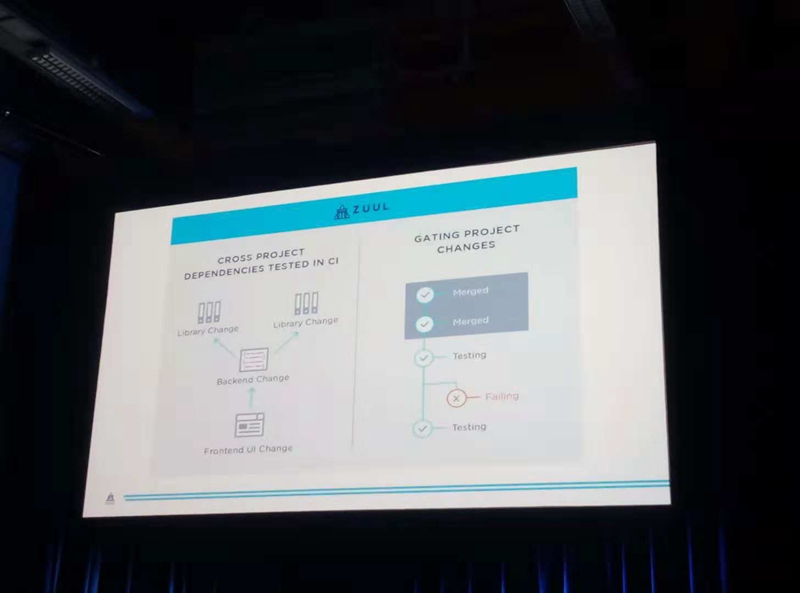
开源的持续集成/部署平台(CI/CD)Zuul已经成为由OpenStack基金会托管的独立项目。该项目最初是为OpenStack CI测试开发的。它已经被许多不同的组织所贡献和使用。Zuul具有项目门控,具有Ansible的CI/CD和跨项目依赖关系。
StarlingX是一个为分布式边缘云提供用户服务的开源项目,为用户提供分布式边缘云所需的服务,用户可以在这些服务中进行选择,或将其作为程序包加以使用。该项目以开源生态系统中的现有服务为基础,采用如Ceph、OpenStack和Kubernetes等前沿项目组件,并通过配置管理和故障管理等新服务加以补充,其重点集中在高可用性(HA)、服务质量(QoS)、性能和低延迟等关键要求方面。

Kata Containers是由OpenStack基金会管理,是一个可以使用容器镜像以超轻量级虚机的形式创建容器的运行时工具,Kata Containers创建的不同容器跑在一个个不同的虚拟机(kernel)上,比起传统容器提供了更好的隔离性和安全性。同时继承了容器快速启动和快速部署等优点。Kata Containers符合OCI(Open Container Initiative)规范,同时还可以兼容K8S的CRI(Container Runtime Interface)接口规范。

在主题演讲中,OpenStack Nova项目负责人则介绍了Nova的最新特性,比如对GPU、FPGA、ARM等的支持。Nova是OpenStack架构中最为基础的服务组件。

在OpenStack项目中,Nova是一个成熟而复杂的项目,而伴随着整个OpenStack技术框架日趋成熟,Nova的稳定性和采纳程度都在持续攀升。同时,受人工智能、机器学习、NFV和边缘计算等用例的驱动,Nova也在与时俱进,不断吸纳新的技术。


GPU加速器的Cyborg接口现在允许从OpenStack框架内访问和重新编程FPGA,包括用于以编程方式自动执行此操作的REST API。
Ironic裸机控制器允许大规模集群将其镜像加载到主内存而不是本地存储,并且这将大大加快裸机服务器的部署。Ironic还具有控制物理服务器中BIOS设置的接口,并配置各种设置,例如SR-IOV外设总线虚拟化。
现在雅虎大规模运行Ironic插件,管理着超过100万个内核,运行各种应用程序。Adobe拥有一个超过100000个核心的OpenStack云,由四个人运营——该公司表示,运行成本比公有云上的基础设施低30%。企业SaaS软件供应商Workday拥有一个50000核心的OpenStack集群,该集群正在扩展到300000个核心,以支持快速扩展的业务。
随着工作负载数量的增加以及工作负载本身在容量和用户方面的增长,OpenStack用户集群的规模不断扩大,这意味着目前OpenStack云上的虚拟机管理程序和虚拟机的数量不断发展,即使容器正在成为打包和部署软件的方式。
此外,备受关注的Superuser Awards获奖者被公布,那就是city network,其是在欧洲和北美拥有多个数据中心的OpenStack公有云供应商。

来源:至顶网服务器频道
好文章,需要你的鼓励


Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
火箭实验室(Rocket Lab)宣布计划以现金加股票方式,斥资80亿美元收购主要卫星运营商铱星通信(Iridium Communications),交易预计于2027年中完成。铱星目前运营着由66颗活跃低轨卫星组成的星座网络,拥有约255万活跃用户,2024年营收达8.717亿美元。收购完成后,Rocket Lab计划借助其新型重型运载火箭Neutron及Lightning卫星平台,扩大铱星星座规模,开拓未被覆盖的市场并降低发射成本。

香港大学与武汉大学联手打造的卫星图像预测系统,竟能“预感“干旱来袭?
香港大学与武汉大学联合开发的EO-WM系统,将地球观测卫星图像预测重新定义为天气驱动的世界建模问题,通过把气象信号拆解为气候基线、天气异常和累积压力三层,显著提升了对极端干旱和热浪事件下植被退化的预测准确性。

Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
音乐流媒体平台Tidal宣布,将于7月中旬启用自动化工具,对完全由AI生成的音乐添加"AI"标识,并移除具有欺诈性质的曲目。平台还将取消AI生成音乐的版税资格,仅向真人创作、演唱的原创音乐开放变现渠道。此外,Tidal明确将高频异常上传、干扰真实艺术家等行为列为欺诈活动。Deezer、Spotify等竞争对手此前已推出类似检测机制,流媒体行业正加速构建AI内容治理体系。

腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。
2018
11/15
13:55
分享
点赞

江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
Claude Tag:将职场AI从个人助手升级为团队协作伙伴
数百万颗超新星爆炸或将揭开暗能量的秘密
Base44发布自研大语言模型,氛围编程平台寻求核心竞争壁垒
遗留系统与数据鸿沟制约亚洲财资中心发展
机器人手部公司与特斯拉达成商业秘密诉讼和解,完成1100万美元融资
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
想进大厂?初创公司或许才是你的最佳跳板
公共电力性价比优势面临多年来最严峻考验
特斯拉开始向HW3车型推送FSD v14"精简版"
