
富士通展示Dataffinic Computing高速大数据处理原型技术
富士通实验室正在努力满足在处理分析工作负载的大数据系统中加快处理速度的需求。
近日富士通表示,已经开发了一项新技术可以帮助在分布式存储系统中高速处理大数据,并且信息是保存在多个驱动器中的。这项新技术是在开源Ceph分布式存储框架上实现的,富士通认为它可以很好地运行以消除服务器尝试从这些存储系统读取数据时出现的瓶颈。
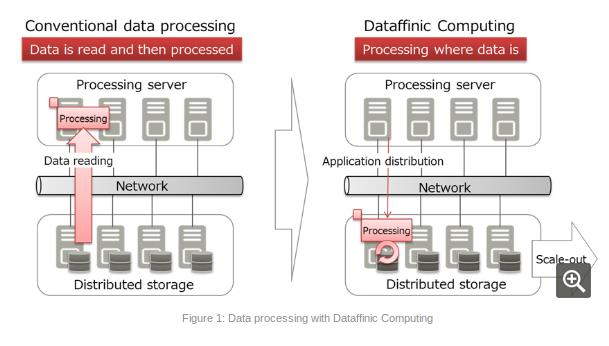
富士通工程师在博客文章中谈到了所谓的“Dataffinic Computing”技术,他表示,存储和服务器之间流动的大量数据是分析系统延迟的主要原因。但是通过在存储中处理这些数据,他们认为这样可以加快速度,因为不需要先移动数据。
Dataffinic Computing通过网络连接多个服务器,同时保持原始存储功能。富士通说,这种方法分解了非结构化视频和日志数据,让所有数据都更容易访问和压缩。
“这意味着分散于分布式存储中的数据可以单独处理,保持访问性能的可扩展性,并提高整体系统性能,”富士通的工程师声称。
富士通的系统还可以预测在分析数据时维护数据所需的存储资源需求。
“存储节点面临各种系统负载以安全地维护数据,包括错误后的自动恢复处理,添加更多存储容量后的数据重新分配处理,以及作为预防性维护一部分的磁盘检查处理,”富士通的工程师写道。“该技术模拟了存储系统中出现的系统负载类型,预测了不久将来所需的资源。基于此,该技术控制数据处理资源及其分配,而不会降低系统存储功能的性能。”
富士通表示,Dataffinic原型系统包括5个存储节点和5个服务器,由一个千兆网络连接。工程师们通过从50GB视频数据中提取出例如人和车等对象来测量其数据处理性能。
工程师表示,Dataffinic系统可以在50秒内处理这些数据,这比使用传统方法处理数据所花费的500秒缩短了10倍。
“这项技术可以实现对爆炸式增加的数据进行可扩展和高效的处理,”富士通工程师这样表示。
Constellation Research分析师Holger Mueller表示,富士通的这项新技术可能很有用处,因为存储对于依赖大数据的下一代软件应用来说至关重要。
Mueller说:“企业需要坚持数据进行时间分析、记录保存和法定监管。因此,存储硬件制造商必须创新,应对必须存储和处理的越来越多的数据。很高兴看到研发投资带来了新的高性能存储选择。”
下一步将是通过商业应用验证该技术。如果运行可靠的话,富士通计划在2019年之前将基于该架构的新产品推向市场。
来源:至顶网服务器频道
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

清华大学等团队如何让AI智能体拥有“记忆力“,从而真正学会自主探索未知世界?
清华大学等机构提出JAMEL框架,通过代码覆盖率信号联合训练AI智能体的潜在记忆模块与探索策略,以极低token消耗实现媲美大型闭源模型的自主探索能力。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

当AI“管家“学会分工协作:卡内基梅隆大学研究团队如何让电脑操作智能体突破单打独斗的瓶颈
卡内基梅隆大学提出MACU框架,让经理AI统筹多个员工AI并行完成复杂电脑操作任务,通过动态调整任务图,在四个基准上均超越单智能体。
2018
09/25
10:40
分享
点赞

Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
Infineon Live Lab正式发布:全球首个实时云端实体硬件评估平台
Serve Robotics携手NoScrubs,自主配送机器人跨界拓展洗衣服务
Workr Robotics CEO:工业机器人自动化应按小时付费
专访CreateMe CEO:从缝纫到粘合,实体AI如何重塑服装制造
AI浪潮为集成商带来全新连接挑战
