
在现场:HPC China 2017见闻录 原创
至顶网服务器频道合肥 10月20日 新闻消息(文/李祥敬): 又到一年一度的全国高性能计算年会,今年的HPC China在安徽合肥举行。本届大会的主题是“应用驱动 生态共建”,探讨了在新IT背景下未来HPC发展的新趋势和新挑战。下面是笔者在HPC China 2017大会上的见闻,因为此前仍连续多届参加HPC China,所以希望透过所见所闻呈现本届大会的与众不同。

HPC China 2017大会
对于HPC China的历史沿革,我们需要有所了解。 全国高性能计算学术年会创办于2005年,至今已成功举办12届,年会围绕高性能计算技术的研究进展与发展趋势、高性能计算的重大应用等主题展开。今年的大会也是如此,而且这是在云计算、大数据、人工智能等技术技术潮流快速发展的背景下召开,所以其与往届相比有着更为不同的意义所在。
展区一览
作为历时三天的大会,展区部分肯定是不能错过的。
在今年的HPC China上,笔者看到了联想、中科曙光等服务器厂商的展台,还有NVDIA、英特尔的展台。每家厂商的展台标语还是很值得玩味的,联想是“智能超算”,曙光是“中国第一的HPC提供商”,NVDIA是“人工智能推动高性能计算新突破”,英特尔是“洞见始于芯”。

英特尔展台

联想展台

曙光展台

NVIDIA展台
在每家展台,还展出了自家代表性的产品,比如联想NeXtScale WCT水冷服务器、曙光高密度浸没式服务器、NVIDIA DGX Station等。

联想NeXtScale WCT水冷服务器

曙光高密度浸没式服务器

NVIDIA DGX Station
虽然现在是一个软件定义的时代,但是厂商在硬件层面也在进行积极的创新,比如在功耗、性能、密度等层面,上述几个产品就是典型的代表。除了这些产品,不管是英特尔还是NVIDIA,在芯片层面也在积极进行革新。
比如NVIDIA Tesla V100加速卡,采用下一代显卡Volta架构,12nm制程,CUDA单元达到了5120个,16GB HBM2显存,单精度浮点是惊人的15TFLOPS。
英特尔全新至强可扩展处理器借助提升的HPC性能以及英特尔Omni-Path架构,英特尔Optane技术内存等,让计算力同数据分析、深度学习相结合,让企业得以借助深度学习、人工智能等新型工具和手段建立发掘数据价值,加速数据洞察的新途径。
除了CPU和GPU,现在FPGA等芯片也涌现出来,很显然未来是一个多样化计算力的融合时代,企业不应局限于其中的某一个,而是根据自己的工作负载情况有针对性选择。
多样与融合
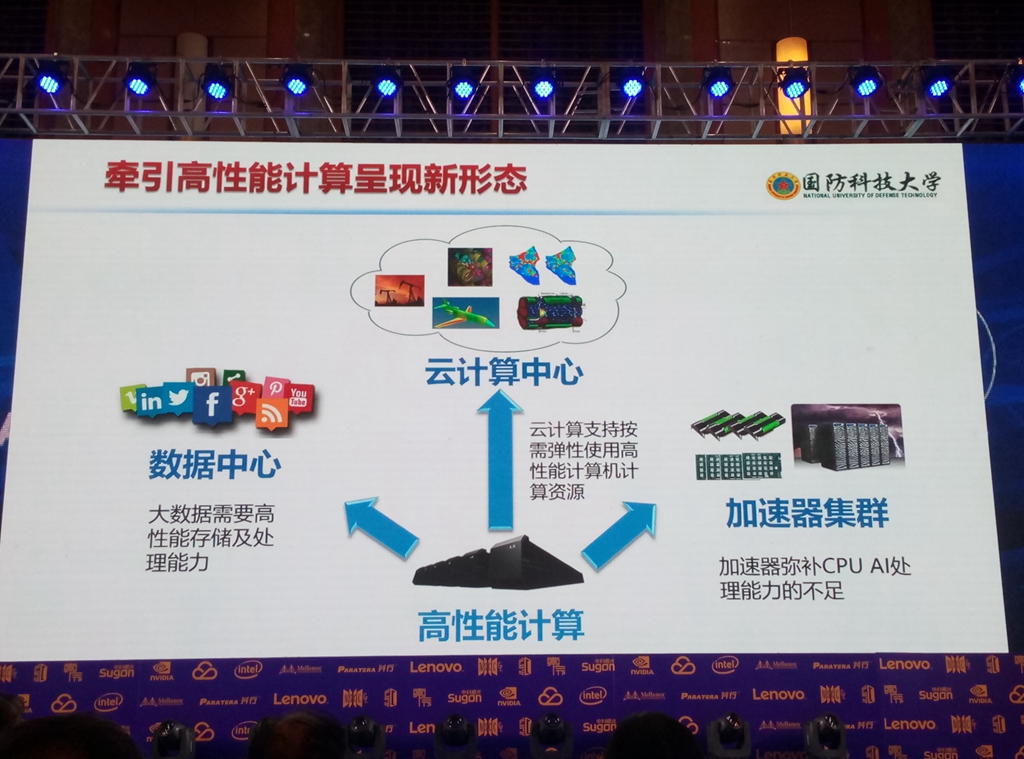
中国工程院院士、国防科技大学计算机学院院长廖湘科演讲PPT一页
中国工程院院士、国防科技大学计算机学院院长廖湘科在HPC China 2017大会上进行了主题为《人工智能、大数据与高性能计算协同发展》的演讲,在演讲中,廖湘科表示,高性能计算为人工智能的崛起提供了计算引擎,大数据为人工智能提供了数据引擎,同时人工智能和大数据牵引高性能计算呈现新形态,未来人工智能、大数据和高性能计算会融合发展。
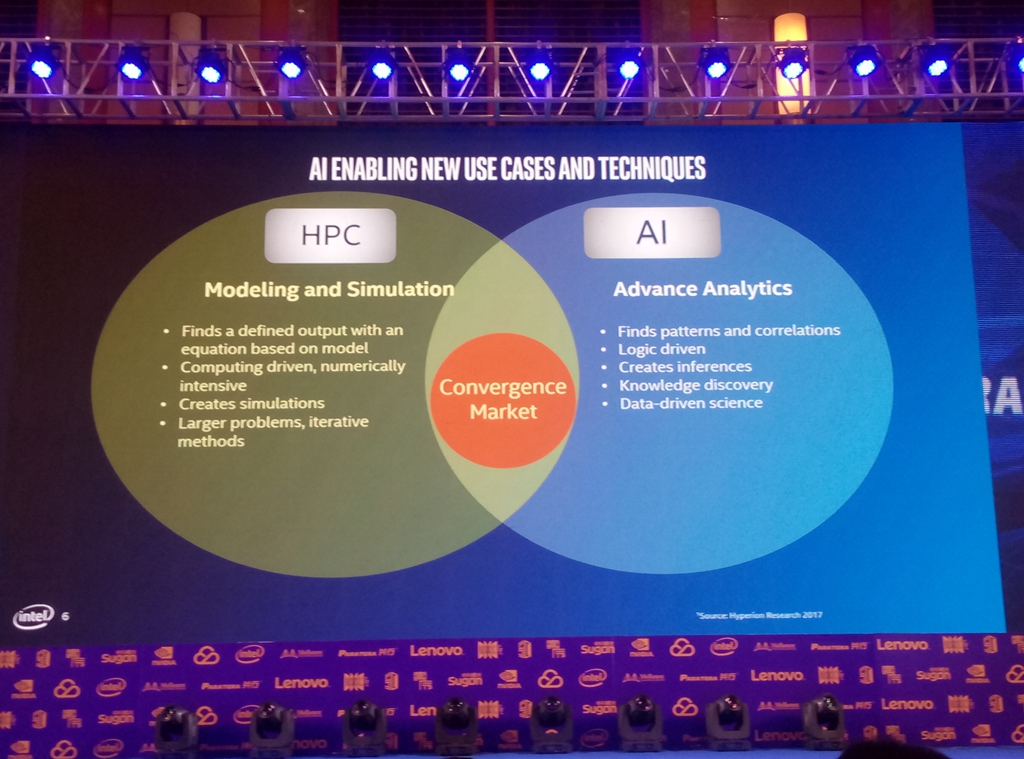
英特尔眼中的HPC与AI融合
英特尔的演讲也表达了同样的观点,那就是HPC与AI的融合。除了这点,英特尔HPC还会聚焦在E级计算、云中HPC等趋势。
同时,英特尔的专家在接受至顶网记者采访时表示,英特尔为HPC提供的不只是计算力,还有存储、网络、软件等端到端的HPC解决方式。
很显然,面对多样化的计算,企业需要的一个统一的一致性的使用体验,HPC也是如此。如何帮助客户提升HPC的部署、运维、优化、使用等体验才是未来厂商关注的焦点。
联想数据中心业务集团全球高性能计算与人工智能技术高级总监Scott Tease表示,面对即将到来的E级计算,联想将以其开放的生态圈、可扩展的基础设施、温水水冷技术、智能超算平台和分布式存储解决方案,以及HPC专家团队助力客户创新发展。

联想数据中心业务集团全球高性能计算与人工智能技术高级总监Scott Tease演讲PPT一页
据Scott Tease介绍,为了更好地让HPC赋能客户实现AI创新和数字化转型,联想将在人工智能、物联网、大数据等领域给予更多关注和投资,这些投资也包括即将在中国北京,美国莫里斯维尔,德国斯图加特落成的三大AI创新中心。
除了联想,中科曙光在先进计算的理念下拓展EasyOP高性能计算在线服务平台,探索计算服务业的新潮流。
在HPC China 2017上,曙光与中国科学技术大学就建立“EasyOP高性能计算在线服务平台(安徽分中心)”举行授牌仪式。

曙光公司副总裁任京暘
曙光公司副总裁任京暘表示,近年来,曙光不仅持续在高性能计算前沿发力,还于近期交付了中国首台量产全浸没式液冷服务器、全球首款量子通信云安全一体机、P+P架构全新DeskHPC等。
HPC China 2017 TOP 100排行榜公布
在HPC China上,TOP 100排行榜是压轴大戏。今年的榜样同样备受瞩目。浪潮以46套HPC系统在所有上榜厂商中排名第一,超出第二和第三名入围套数总和。或许这样的成绩有点“意外”,但是情理之中,浪潮在互联网市场的耕耘以及互联网厂商在人工智能和高性能计算方面的大量应用是促成这种格局的必然。
更多榜单信息,大家可以看我的同事Bob的文章——《HPC China 2017 TOP 100排行榜公布,浪潮46套排名第一!》
小结
HPC China作为国内高性能计算的风向标,依然在为我们指引HPC的新潮流。
在笔者看来,HPC已经来到了一个十字路口,在各种新技术的交织下,高性能计算也在谋求自身的革新。这种革新不光是技术和产品层面,还包括服务层面。
很多时候,我在想,HPC,并不只是高性能计算这样一个字面意思,其实其代表了一个服务或者计算力的交付,而这种交付是与时俱进的,其内涵和外延是不断扩展的。
所以,多样化的市场产品和技术是整个业界所喜闻乐见的,不管是CPU还是GPU,亦或FPGA,它们是计算力的承载体。当移动互联网和物联网为我们带来源源不断的数据时,借助这些计算力,加速数据价值实现,才能给个人、企业、社会带来“取之不尽用之不竭”的创新力。(文/李祥敬)
好文章,需要你的鼓励


如何评估量子计算机的性能表现
IBM提出评估量子计算机性能的三个基本指标:可编程量子比特(衡量规模)、量子比特操作数(衡量质量)和每秒最大电路数(衡量速度)。可编程量子比特决定用户可直接控制的量子资源规模;量子比特操作数反映系统可靠执行复杂运算的能力;电路吞吐量则体现系统的性价比。这三项指标适用于超导、离子阱、量子点等各类量子硬件平台,为跨平台性能比较提供统一框架。

沉睡的“孪生大脑“被唤醒:冲绳科学技术大学院大学的研究者们找到了让AI视觉学习更聪明的秘密
冲绳科学技术大学院大学研究者提出SiamJEPA,在JEPA框架中引入孪生学生编码器,证明其充当正则化器、加速训练并提升图像表示质量。

中层管理者是企业AI转型的关键角色,他们对此心知肚明
Salesforce对逾500名中层管理者的调查显示,三分之二的管理者对AI在未来工作中的作用持乐观态度,77%的人每周借助AI工具节省超3小时。研究表明,美国员工比全球平均水平更倾向于质疑AI,而新兴经济体的员工则更信任AI。调查同时指出,管理者需要实操培训、清晰的AI战略及技术支持,以推动企业AI转型成功落地,人才培养始终比技术本身更为关键。

化学AI的“文字切割师“之争:BPE与Unigram-LM,谁才是解读分子语言的更好工具?
这项研究对比了化学AI中常用的BPE和Unigram-LM两种分词算法,发现二者在化学SMILES上构建的词汇表几乎完全不同,词汇重叠不超过16%,分词粒度相差近三分之一,证明分词算法是不可忽视的关键设计决策。
2017
10/20
13:31
分享
点赞

如何评估量子计算机的性能表现
中层管理者是企业AI转型的关键角色,他们对此心知肚明
Anthropic推出Claude Corps项目:资助1000名职场新人用AI服务公益事业
AI旅行平台Fora完成6000万美元D轮融资,估值达10亿美元
离开谷歌数月后,他拿下3亿美元估值的Pre-Seed融资
Google将NotebookLM更名为Gemini Notebook,已有3000万用户使用
英特尔携手谷歌Gemini加速芯片研发与企业智能体转型
Microagi获5500万美元融资,用AI训练工厂机器人
小鹏L03搭载谷歌地图Auto SDK,成为亚太首款实现该集成的量产车型
1Password为Claude带来安全凭证访问功能
瑞士Mimic Robotics发布高性能仿人机械手M1.0
台积电亚利桑那园区投资扩至2650亿美元,AI需求推动营收创历史新高
