
英特尔至强6性能核处理器性能显著提升
随着企业数字化转型进程的加速及新兴技术的大规模应用,业界对多元化、高质量和绿色算力的需求与日俱增。近期,英特尔发布的英特尔® 至强® 6性能核处理器,凭借创新的微架构、显著提升的核心数量、双倍内存带宽,以及对PCIe 5.0和CXL 2.0等最新技术的支持等领先特性,实现了整体性能的显著提升,能够应对边缘、数据中心、云环境的严苛挑战,是数据中心的理想选择。
在云计算领域,相比上一代处理器,至强6性能核处理器能够提供多达2倍的每路核心数,并实现平均单核性能提升1.2倍、每瓦性能提升1.6倍,且帮助云服务提供商(CSP)在同等性能水平下实现平均30% TCO的显著下降。在科学计算中,至强6性能核处理器则凭借MRDIMM实现更强存力,并通过英特尔® AVX-512输出更高算力,从而实现2.31倍NEMO geomean代际性能提升、2.43倍OpenFOAM geomean代际性能提升,以及2.5倍HPCG代际性能提升。
现阶段,以深度学习、机器学习等算法为代表的AI技术正步入高速发展时期,对计算资源的需求急剧增加。而得益于内置的AI加速功能——英特尔® 高级矩阵扩展 (AMX) 和专门面向AI优化的英特尔® AVX-512提高性能与效率,至强6性能核处理器凭借在运行AI工作负载上展现出的卓越性能,已成为数据中心和CSP的优选机头。
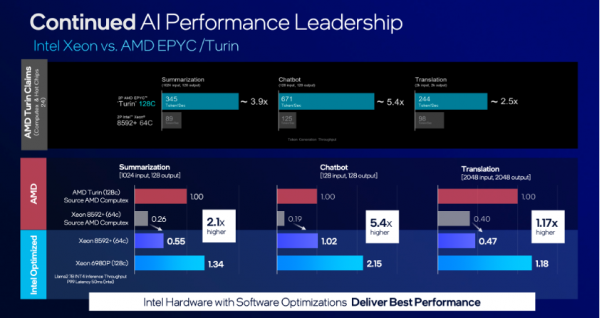
值得注意的是,在软件优化的加持下,至强6性能核处理器能够在运行多元化AI工作负载时展现出最佳性能。如在运行7亿参数的Llama2 INT4推理任务时,至强6性能核处理器提供了比AMD Turin 128核处理器更高的吞吐量。而在诸如文本摘要、聊天机器人和翻译这类生成式AI应用中,至强6性能核处理器分别展现出了约2.1倍、5.4倍及1.17倍的性能提升。
此外,在最新的MLPerf推理v4.1基准测试中,至强6性能核处理器与第五代至强处理器相比,实现了AI性能约1.9倍的几何平均值提升。特别是在自然语言处理任务BERT上,其相比第三代至强处理器性能提升高达17倍,而在计算机视觉任务ResNet50上,性能提升也高达15倍。而这主要得益于至强6性能核处理器的先进架构,包括对英特尔AMX的支持,以及优化的内存带宽等创新。
现阶段,以至强6900P系列处理器为代表的至强6性能核处理器已上市,并被诸多CSP广泛应用至实践中。面对AI时代对算力多元、高效的需求,英特尔通过持续加速创新,打造包括至强6处理器在内的领先硬件,以及开发者首选的软件工具、开发套件和优化库,从而助力生态伙伴以提升的性能拓展新商机,并实现关键业务成果。
好文章,需要你的鼓励


科创新源拟用 2.45 亿元收购导热材料企业,新加坡智科承接海外资产整合
今天讲的出海案例是科创新源,这家高分子材料与液冷板厂商拟用 2.45 亿元收购兆科控制权,并拟通过新加坡智科整合越南制造与海外经营资产。

香港理工大学提出“光学推理“:用图片代替文字做推理,效率翻近两倍
香港理工大学提出"光学推理",将AI推理步骤渲染为图片代替文字,在五款顶级AI模型测试中平均节省28%令牌,效率近两倍。

iOS 27 相册 AI 新功能深度解析:苹果如何在不失真的前提下完善你的照片记忆
苹果高管在最新采访中详细介绍了iOS 27照片应用的三项AI新功能。"空间重构"可在拍摄后调整照片构图视角,仅在视角偏移处生成新内容;"扩展"功能允许用户向外延伸画面最多25%,且每张照片仅限使用一次,防止过度修改;"清除"功能则升级为可处理更复杂的对象。苹果强调,所有功能的核心目标是在保留原始记忆真实感的同时,帮助用户完善影像效果。

AI评测系统竟能被轻易“作弊“?卡内基梅隆大学等机构发现16%的测试题可被绕过,并研发出自动防御工具
卡内基梅隆大学等机构发现,16%的主流AI评测任务存在可被绕过的漏洞,并提出三智能体自动防御方案,将KernelBench攻击成功率从76%降至0%。
2024
10/22
12:46
分享
点赞

科创新源拟用 2.45 亿元收购导热材料企业,新加坡智科承接海外资产整合
iOS 27 相册 AI 新功能深度解析:苹果如何在不失真的前提下完善你的照片记忆
iOS 27 Beta 1 新听写功能默认关闭,附开启教程
软通动力向沙特交付机械革命硬件项目,全栈智能业务进入中东本地合作阶段
索尼AI乒乓球机器人如何推动物理AI技术发展
Parallel Systems CEO:我们正在构建全球首个自主货运铁路系统
Dietsmann携机器人技术亮相非洲能源周,推动智能化运维转型
DJI与Insta360专利大战全面爆发,创作者科技领域迎来史上最激烈竞争
桑达尔·皮查伊斯坦福毕业典礼演讲:加州乐观主义与做有价值的难事
MassRobotics宣布2026年机器人奖章得主:斯坦福大学冈村·艾莉森与首尔国立大学金雅英获此殊荣
更便宜、更快速、更懂本土文化:Avataar AI视频模型专为印度规模化场景而生
诺和诺德遭遇网络攻击,患者数据外泄
